改编自https://www.bilibili.com/video/BV1iJ41127cw?spm_id_from=333.337.search-card.all.click提供的代码。下文为改动之后的代码:
import numpy as np
import pandas as pdfrom sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
导入数据,按9:1划分训练、测试集,随机数定为42(任意)
sediment=pd.read_csv('E:/Resource/Develop/notebook/random_forest.csv')
X=sediment.drop(["S"],axis=1)
y=sediment["S"]
x_train,x_test,y_train,y_test=train_test_split(X,y,random_state=42,test_size=0.1)
优化参数:遍历字典中的参数取值。字典可以根据得到的结果继续更新,缩小上次的字典范围;字典中的数值根据自己的数据特点确定。
#导入随机森林模块
from sklearn.ensemble import RandomForestRegressor
#导入网络搜索交叉验证,网络搜索可以让模型参数按照我们给定的列表遍历,找到效果最好的模型
#交叉验证可以告诉我们模型的准确性
from sklearn.model_selection import GridSearchCV
#构造参数字典,让这三个参数按照列表给定的顺序排列组合遍历一遍
param_grid={'n_estimators':range(5,150,5),#决策树的个数'max_depth':[3,4,5,6,7,8,9],#最大树深,树太深会造成过拟合'max_features':[0.3,0.4,0.6,1,2,3]#决策树划分时考虑的最大特征数
}
#实例化随机森林回归器
rf=RandomForestRegressor(random_state=42)
#一随机森林回归器为基础构造网络搜索回归器
grid=GridSearchCV(rf,param_grid=param_grid,cv=10)#十则交叉验证grid.fit(x_train,y_train)
查看最优参数结果(这一“最优”参数是基于两次random_state=42得到的,一次是随机选取的训练测试集,另一次是随机森林模型当中建模的随机路径,42(或其他任意数字代表某一种随机过程,帮助我们复现该次随机的结果。只要我们下回还用2次random_state=42,就能得到和这回同样的结果)
#查看效果最好的模型
grid.best_params_
#制定效果最好参数对应的模型
rf_reg=grid.best_estimator_
rf_reg
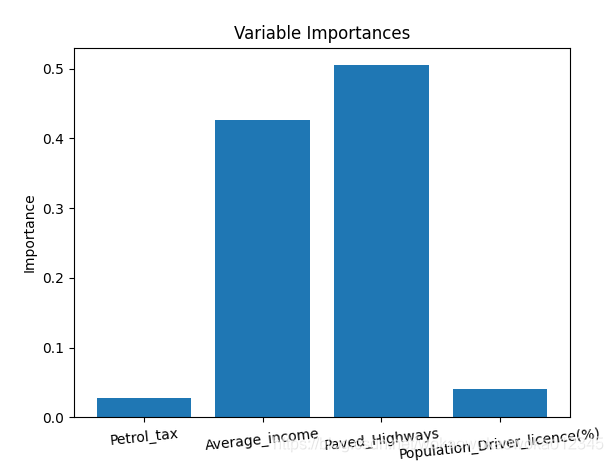
得到模型之后分析参数重要性
#特征重要度分析
rf_reg.feature_importances_
print('特征排序:')
feature_names=X.columns
feature_importances=rf_reg.feature_importances_
indices=np.argsort(feature_importances)for index in indices:print('feature %s (%f)' %(feature_names[index],feature_importances[index]))
参数重要性排序作图
plt.figure(figsize=(7,5))
plt.title('随机森林模型中不同特征的重要程度')
plt.bar(range(len(feature_importances)),feature_importances[indices],color='b')
plt.xticks(range(len(feature_importances)),np.array(feature_names)[indices],color='b')
plt.show()
#可视化测试集上回归预测的结果
result={"labels":y_test,"prediction":rf_reg.predict(x_test)}
result=pd.DataFrame(result)
输出测试集的真实值(labels)和预测值(prediction)
print(result)
根据抽样序号在图中展现真实值和预测值结果(见下面的例图)
result['labels'].plot(style='k.',figsize=(15,5))
result['prediction'].plot(style='r.')
plt.legend(fontsize=15,markerscale=3)#设置图例字号以及图例大小
plt.tick_params(labelsize=15)#设置坐标数字大小
plt.grid()

评估该随机森林回归模型的好坏
#计算测试集的均方误差和均方根误差
from sklearn import metrics
MSE=metrics.mean_squared_error(y_test,rf_reg.predict(x_test))
RMSE=np.sqrt(MSE)
print('(MSE,RMSE)=',(MSE,RMSE))
#计算测试集的R方
from sklearn.metrics import r2_score
print('The value of R-squared of LinearRegression is', r2_score(y_test,rf_reg.predict(x_test)))






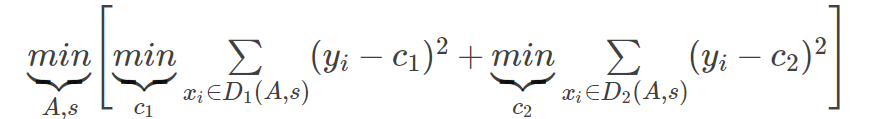





![DS和[address]](https://img-blog.csdnimg.cn/20200202162712584.png)