SpringMVC + MyBatis分库分表方案
mybatis作为流行的ORM框架,项目实际使用过程中可能会遇到分库分表的场景。mybatis在分表,甚至是同主机下的分库都可以说是完美支持的,只需要将表名或者库名作为动态参数组装sql就能够完成。但是多余分在不同主机上的库,就不太一样了,组装sql无法区分数据库主机。网上搜索了一下,对于此类情况,大都采用的动态数据源的概念,也即定义不同的数据源连接不同的主机数据库,在查询前通过动态数据源进行数据源切换,但从实现上来看,这个切换并不是单sql级别的,而可以理解为时间级别的切换,即查询前切到对应数据源,这种实现在并发场景下并不能满足分库减压需求,甚至会导致查错数据库的情况。
这里给出分库分表的实现方式,特别在分库的方案上,采用真正可并发的方案。
这里以银行卡消费记录为例子来看这个问题,银行有多个用户,通过Card( id,owner) 来标志,每个卡有消费记录,CostLog(id,time,amount) ,由于消费记录数据过多,我们对数据进行分库分表存储。
一、基本配置
首先我们来看下mybatis结合springmvc的基本配置方式(不进行分库分表)。
mybatis的配置链路可以有底层到上层解释为: DB(数据库对接信息) -》数据源(数据库连接池配置) -》session工厂(连接管理与数据访问映射关联) -》DAO(业务访问封装)
<!--定义mysql 数据源,连接数据库主机的连接信息 --><bean id="test1-datasource" class="org.apache.commons.dbcp.BasicDataSource"><property name="driverClassName" value="${jdbc.driverClassName}"></property><property name="url" value="${jdbc.url}"></property><property name="username" value="${jdbc.username}"></property><property name="password" value="${jdbc.password}"></property><property name="maxActive" value="40"></property><property name="maxIdle" value="30"></property><property name="maxWait" value="30000"></property><property name="minIdle" value="2"/><property name="timeBetweenEvictionRunsMillis" value="3600000"></property><property name="minEvictableIdleTimeMillis" value="3600000"></property><property name="defaultAutoCommit" value="true"></property><property name="testOnBorrow" value="true"></property><property name="validationQuery" value="select 1"/></bean><!--定义session工厂,指定数据访问映射文件和使用的数据源--><bean id="test1-sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><property name="mapperLocations"><list><value>classpath*:confMapper/*Mapper.xml</value></list></property><property name="dataSource" ref="test1-datasource"/></bean><!--定义session工厂和DAO扫描路径,自动进行DAO与session工厂的绑定--><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="com.ming.test.po"/><property name="sqlSessionFactoryBeanName" value="test1-sqlSessionFactory"/></bean>
上面配置中需要我们自己定义的 内容有
1.session工厂中的数据访问映射文件,这里需要符合配置中命名规范并放在对应路径下,以Mapper.xml结尾,可以叫做 CostLogMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="CostDao"><resultMap id="BaseResultMap" type="CostLog"><result property="id" column="id"/><result property="time" column="time"/><result property="amount" column="amount"/></resultMap><select id="queryCostLog" resultMap="BaseResultMap">SELECT `id`,`time`,`amount` FROM CostLog WHERE `id` = #{id}</select>
</mapper>
2.扫描绑定中 basePackage指定的包名下的DAO类
public interface CostDao {CostLog queryCostLog(@Param("id") int id);
}
3.上面两项所依赖的数据对象 CostLog
@Setter
@Getter
public class CostLog {private Integer id;private Date time;private Integer amount;
}
4.对应的数据库表
这里我们和 CostLog 使用同样的命名
我们可以使用如下代码访问:
@Service
public class CostLogService {@ResourceCostDao costDao;public CostLog queryCostDao(int id) {return costDao.queryCostLog(id);}
}
二、不分主机的分库表实现
对于上例,我们只需要在DAO中增加库表名参数,并适当修改SQL即可
数据访问映射配置写法:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="CostDao"><resultMap id="BaseResultMap" type="CostLog"><result property="id" column="id"/><result property="time" column="time"/><result property="amount" column="amount"/></resultMap><select id="queryCostLog" resultMap="BaseResultMap">SELECT `id`,`time`,`amount` FROM ${dbName}.${tbName} WHERE `id` = #{id}</select>
</mapper>
DAO类写法:
public interface CostDao {CostLog queryCostLog(@Param("dbName") String dbName, @Param("tbName") String tbName, @Param("id") int id);
}
调用层计算库表名称,并传递参数:
@Service
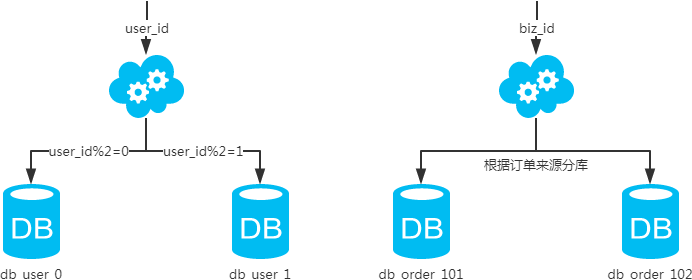
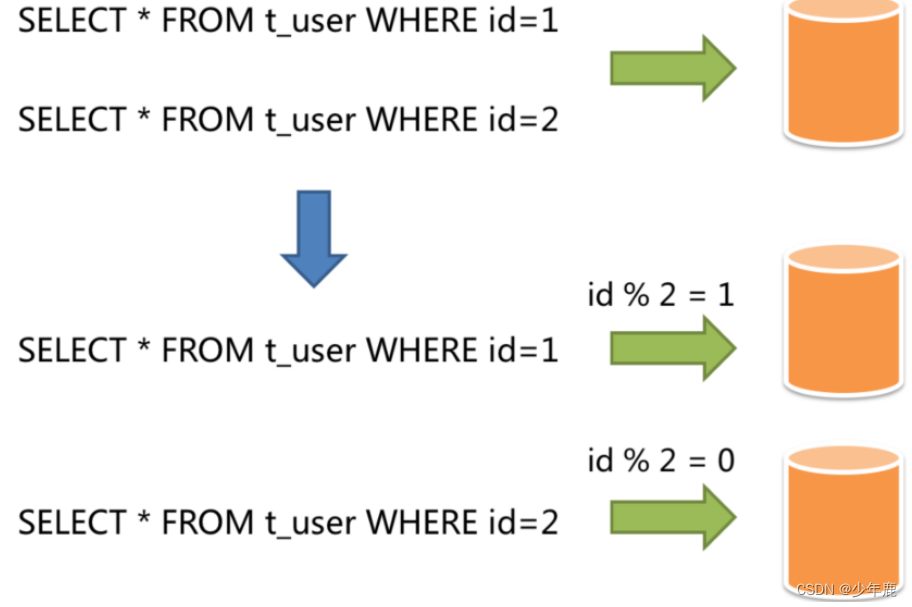
public class CostLogService {@ResourceCostDao costDao;public CostLog queryCostDao(int id) {//分两库两表db1、db2,每个库中又有两个表tb1、tb2,我们根据账户id模4的取模值来分库表,0:db1.tb1 ;1:db1.tb2;2:db2.tb1;3:db2.tb2String dbName = id % 4 < 2 ? "db1" : "db2";String tbName = id % 2 == 0 ? "tb1" : "tb2";return costDao.queryCostLog(dbName, tbName, id);}
}
三、分主机的分库实现
首先通过需求确认几点:
1.我们期望不同的查询根据id自动到不同的主机上去查询,也就是db1和db2在不同的主机上
2.我们分库目的是数据库减负并且会有并发访问,因此db1和db2要能够同时提供服务
鉴于第一点,我们需要定义两个数据源,同时分别连接不同的数据库主机。
鉴于第二点,我们需要将数据源的选择细化到单个请求。
a.一种是将逻辑封装到DAO中实现,使DAO进行访问前根据请求参数按照我们定义的逻辑选择数据源。遗憾的是,DAO的具体实现是又mybatis动态代理生成的,这个功能依赖mybatis的支持,我目前并不知道mybatis有提供这么一个功能。
b.另一种是定义两个DAO,分别连接不同的数据源,但是两个DAO的查询逻辑是完全一样的。我们采用这种方式。
一种实现是我们定义两套完全相同的数据映射配置和两个DAO接口,分别连接不同的数据源,但这种方式实际上会有较多的重复配置,如果分库不止两个,而是多个,那么后续维护修改就更加困难。有没有办法让多个DAO使用同一个数据访问映射文件呢,经过测试,是有的,甚至多个DAO接口可以继承同一个DAO接口的实现(通过DAO注解直接定义访问逻辑)。
我们可以定义一个父级DAO接口A,然后为每个分库定义一个空的DAO接口,每个接口都继承接口A。如下,我们定义 Db1CostDao 和 Db2CostDao 都继承 CostDao。

子接口只需挂一个名字,而无需有额外实现
public interface Db1CostDao extends CostDao {
}
然后我们在各个数据源的MapperScannerConfigurer配置中,将各个子接口关联到不同的分库session工厂上。而在数据访问映射文件中,我们定义的DAO类型为父级DAO接口A。这样在spring启动扫描时,由于每个子DAO都是接口A的子接口,因此每个子DAO都实例化为一个bean,我们可以在数据访问业务层通过自定义逻辑返回对应的DAO。最终查询的数据库为对应的子DAO接口所对应的数据库。
<!--定义mysql 数据源,连接数据库主机的连接信息 --><bean id="test1-datasource" class="org.apache.commons.dbcp.BasicDataSource"><property name="driverClassName" value="${jdbc.driverClassName}"></property><property name="url" value="${jdbc.url}"></property><property name="username" value="${jdbc.username}"></property><property name="password" value="${jdbc.password}"></property><property name="maxActive" value="40"></property><property name="maxIdle" value="30"></property><property name="maxWait" value="30000"></property><property name="minIdle" value="2"/><property name="timeBetweenEvictionRunsMillis" value="3600000"></property><property name="minEvictableIdleTimeMillis" value="3600000"></property><property name="defaultAutoCommit" value="true"></property><property name="testOnBorrow" value="true"></property><property name="validationQuery" value="select 1"/></bean><!--定义session工厂,指定数据访问映射文件和使用的数据源--><bean id="test1-sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><property name="mapperLocations"><list><value>classpath*:confMapper/*Mapper.xml</value></list></property><property name="dataSource" ref="test1-datasource"/></bean><!--定义session工厂和DAO扫描路径,自动进行DAO与session工厂的绑定--><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="test.dao.db1"/><property name="sqlSessionFactoryBeanName" value="test1-sqlSessionFactory"/></bean><!--定义mysql 数据源,连接数据库主机的连接信息 --><bean id="test2-datasource" class="org.apache.commons.dbcp.BasicDataSource"><property name="driverClassName" value="${jdbc.driverClassName}"></property><property name="url" value="${jdbc.url}"></property><property name="username" value="${jdbc.username}"></property><property name="password" value="${jdbc.password}"></property><property name="maxActive" value="40"></property><property name="maxIdle" value="30"></property><property name="maxWait" value="30000"></property><property name="minIdle" value="2"/><property name="timeBetweenEvictionRunsMillis" value="3600000"></property><property name="minEvictableIdleTimeMillis" value="3600000"></property><property name="defaultAutoCommit" value="true"></property><property name="testOnBorrow" value="true"></property><property name="validationQuery" value="select 1"/></bean><!--定义session工厂,指定数据访问映射文件和使用的数据源--><bean id="test2-sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><property name="mapperLocations"><list><value>classpath*:confMapper/*Mapper.xml</value></list></property><property name="dataSource" ref="test1-datasource"/></bean><!--定义session工厂和DAO扫描路径,自动进行DAO与session工厂的绑定--><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="test.dao.db2"/><property name="sqlSessionFactoryBeanName" value="test2-sqlSessionFactory"/></bean>
映射文件 CostLogMapper.xml则无需做任何修改。
在业务层我们通过自定义逻辑选择DAO
@Service
public class CostLogService {@ResourceDb1CostDao costDao1;@ResourceDb2CostDao costDao2;CostDao selectDao(int id) {return id % 4 < 2 ? costDao1 : costDao2;}public CostLog queryCostDao(int id) {//分两库两表db1、db2,每个库中又有两个表tb1、tb2,我们根据账户id模4的取模值来分库表,0:db1.tb1 ;1:db1.tb2;2:db2.tb1;3:db2.tb2String dbName = id % 4 < 2 ? "db1" : "db2";String tbName = id % 2 == 0 ? "tb1" : "tb2";return selectDao(id).queryCostLog(dbName, tbName, id);}
}
至此,在尽量少冗余代码的情况下,满足并发情况下分库需求。
jdbc.properties
#============================================================================
# MySQL
#============================================================================
jdbc.mysql.driver=com.mysql.jdbc.Driver
jdbc.mysql.url=jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true
jdbc.mysql.username=root
jdbc.mysql.password=root#============================================================================
# MS SQL Server
#============================================================================
#jdbc.sqlserver.driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
#jdbc.sqlserver.url=jdbc:sqlserver://127.0.0.1:1433;database=test;
#jdbc.sqlserver.username=sa
#jdbc.sqlserver.password=sa#============================================================================
# MS SQL Server (JTDS)
#============================================================================
jdbc.sqlserver.driver=net.sourceforge.jtds.jdbc.Driver
jdbc.sqlserver.url=jdbc:jtds:sqlserver://127.0.0.1:1433/test
jdbc.sqlserver.username=sa
jdbc.sqlserver.password=sa#============================================================================
# 通用配置
#============================================================================
jdbc.initialSize=5
jdbc.minIdle=5
jdbc.maxIdle=20
jdbc.maxActive=100
jdbc.maxWait=100000
jdbc.defaultAutoCommit=false
jdbc.removeAbandoned=true
jdbc.removeAbandonedTimeout=600
jdbc.testWhileIdle=true
jdbc.timeBetweenEvictionRunsMillis=60000
jdbc.numTestsPerEvictionRun=20
jdbc.minEvictableIdleTimeMillis=300000
多数据源时Spring配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xmlns:aop="http://www.springframework.org/schema/aop"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-3.0.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context-3.0.xsdhttp://www.springframework.org/schema/aophttp://www.springframework.org/schema/aop/spring-aop-3.0.xsd"><bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"><property name="location" value="classpath:jdbc.properties"/></bean><bean id="sqlServerDataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"><property name="driverClassName" value="${jdbc.sqlserver.driver}"/><property name="url" value="${jdbc.sqlserver.url}"/><property name="username" value="${jdbc.sqlserver.username}"/><property name="password" value="${jdbc.sqlserver.password}"/><property name="initialSize" value="${jdbc.initialSize}"/><property name="minIdle" value="${jdbc.minIdle}"/><property name="maxIdle" value="${jdbc.maxIdle}"/><property name="maxActive" value="${jdbc.maxActive}"/><property name="maxWait" value="${jdbc.maxWait}"/><property name="defaultAutoCommit" value="${jdbc.defaultAutoCommit}"/><property name="removeAbandoned" value="${jdbc.removeAbandoned}"/><property name="removeAbandonedTimeout" value="${jdbc.removeAbandonedTimeout}"/><property name="testWhileIdle" value="${jdbc.testWhileIdle}"/><property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}"/><property name="numTestsPerEvictionRun" value="${jdbc.numTestsPerEvictionRun}"/><property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}"/></bean><bean id="mySqlDataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"><property name="driverClassName" value="${jdbc.mysql.driver}"/><property name="url" value="${jdbc.mysql.url}"/><property name="username" value="${jdbc.mysql.username}"/><property name="password" value="${jdbc.mysql.password}"/><property name="initialSize" value="${jdbc.initialSize}"/><property name="minIdle" value="${jdbc.minIdle}"/><property name="maxIdle" value="${jdbc.maxIdle}"/><property name="maxActive" value="${jdbc.maxActive}"/><property name="maxWait" value="${jdbc.maxWait}"/><property name="defaultAutoCommit" value="${jdbc.defaultAutoCommit}"/><property name="removeAbandoned" value="${jdbc.removeAbandoned}"/><property name="removeAbandonedTimeout" value="${jdbc.removeAbandonedTimeout}"/><property name="testWhileIdle" value="${jdbc.testWhileIdle}"/><property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}"/><property name="numTestsPerEvictionRun" value="${jdbc.numTestsPerEvictionRun}"/><property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}"/></bean><bean id="multipleDataSource" class="com.cnblogs.lzrabbit.MultipleDataSource"><property name="defaultTargetDataSource" ref="mySqlDataSource"/><property name="targetDataSources"><map><entry key="mySqlDataSource" value-ref="mySqlDataSource"/><entry key="sqlServerDataSource" value-ref="sqlServerDataSource"/></map></property></bean><bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><property name="dataSource" ref="multipleDataSource"/></bean><!<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="com.cnblogs.lzrabbit"/></bean><!<context:component-scan base-package="com.cnblogs.lzrabbit"/><aop:aspectj-autoproxy/>
</beans>
Java代码编写
MultipleDataSource 多数据源配置类
package com.xxx.gfw.pubfound;import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;/****
* Project Name:gfw-public-foundation-impl
* <p>自定义多数据源配置类
*
* @ClassName: MultipleDataSource
* @date 2018年5月18日 下午4:47:20
*
* @author youqiang.xiong
* @version 1.0
* @since*/
public class MultipleDataSource extends AbstractRoutingDataSource {private static final ThreadLocal<String> dataSourceKey = new InheritableThreadLocal<String>();public static void setDataSourceKey(String dataSource) {dataSourceKey.set(dataSource);}@Overrideprotected Object determineCurrentLookupKey() {return dataSourceKey.get();}
}
自定义注解DataSourceType
package com.xxx.pubfound.aop.anntion;import java.lang.annotation.*;/****
* Project Name:gfw-base-common-service
* <p>自定义数据源类型注解,标志当前的dao接口使用的数据源类型
*
* @ClassName: DataSourceType
* @date 2018年5月18日 下午5:09:49
*
* @author youqiang.xiong
* @version 1.0
* @since*/
@Target({ ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DataSourceType {String value() default "dataSource";
}
两个service层分别加上DataSourceType 注解
ProvinceServiceImpl.java
package com.xxx.pubfound.service;import java.util.ArrayList;
import java.util.List;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import com.xxx.pubfound.aop.anntion.DataSourceType;
import com.xxx.pubfound.dao.SysProvinceDao;
import com.xxx.pubfound.dto.SysProvinceDTO;
import com.xxx.pubfound.struct.SysProvinceListStruct;
import com.xxx.pubfound.struct.SysProvinceStruct;
import com.xxx.rpc.api.AbstractRpcService;/****
* Project Name:gfw-public-foundation-impl
* <p> 省份服务层实现类
*
* @ClassName: ProvinceServiceImpl
* @date 2018年5月18日 下午6:29:35
*
* @author youqiang.xiong
* @version 1.0
* @since*/
@DataSourceType(value="gfwDataSource")
@Service
public class ProvinceServiceImpl extends AbstractRpcService implements ProvinceService {@Autowiredprivate SysProvinceDao sysProvinceDao;@Overridepublic SysProvinceListStruct getProvinceList() {List<SysProvinceDTO> list = sysProvinceDao.getProvinceList();return beanToStruct(list);}/**** * Project Name: gfw-public-foundation-impl* <p>将dto对象封装struct对象 ** @author youqiang.xiong* @date 2018年5月28日 下午3:31:42* @version v1.0* @since * @param provinceList* 省份列表dto* @return 省份列表struct*/private SysProvinceListStruct beanToStruct(List<SysProvinceDTO> provinceList){if(provinceList == null || provinceList.size() == 0){return null;}List<SysProvinceStruct> resultList = new ArrayList<SysProvinceStruct>();for(SysProvinceDTO dto:provinceList){SysProvinceStruct struct = new SysProvinceStruct();struct.provinceId = dto.getProvinceId();struct.provinceName = dto.getProvinceName();resultList.add(struct);}SysProvinceListStruct rsStruct = new SysProvinceListStruct(resultList);return rsStruct;}}
DefaultExceptionCollector.java
package com.xxx.pubfound.service;import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import com.alibaba.druid.pool.DruidDataSource;
import com.github.pagehelper.PageInfo;
import com.xxx.pubfound.aop.anntion.DataSourceType;
import com.xxx.pubfound.dao.PfExceptionLogDao;
import com.xxx.pubfound.dto.NotifyLevelEnum;
import com.xxx.pubfound.entity.PfExceptionLog;
import com.xxx.pubfound.struct.PagedPfExceptionLogStruct;
import com.xxx.pubfound.struct.PfExceptionLogStruct;
import com.xxx.rpc.api.AbstractRpcService;/****
* Project Name:gfw-public-foundation-impl
* <p>异常采集
*
* @ClassName: DefaultExceptionCollector
* @date 2018年5月28日 下午8:01:43
*
* @author youqiang.xiong
* @version 1.0
* @since*/
@DataSourceType(value="dataSource")
@Service
public class DefaultExceptionCollector extends AbstractRpcService implements ExceptionCollector {@AutowiredPfExceptionLogDao pfExceptionLogDao;@AutowiredDruidDataSource dataSource;@Overridepublic void collect(long reqTime, String exceptionClass, String stackTrace, int resultCode, String environment,String nodeNameEn) {System.out.println(dataSource.getConnectProperties());PfExceptionLog exceptionLog = new PfExceptionLog();exceptionLog.setEnvironment(environment);exceptionLog.setExceptionClass(exceptionClass);exceptionLog.setExceptionTime(new Date(reqTime));exceptionLog.setResultCode(resultCode);exceptionLog.setServiceName(nodeNameEn);exceptionLog.setStackTrace(stackTrace);pfExceptionLogDao.insert(exceptionLog);System.out.println("Exception ex:" + exceptionClass);System.out.println("Exception ex:" + resultCode);}@Overridepublic void collectNotify(long reqTime, String exceptionClass, String stackTrace, int resultCode,String environment, String nodeNameEn, NotifyLevelEnum level) {try{this.collect(reqTime, exceptionClass, stackTrace, resultCode, environment, nodeNameEn);}catch(Exception ex){ex.printStackTrace();}if(level.compareTo(NotifyLevelEnum.WARN) == 0){}else if(level.compareTo(NotifyLevelEnum.ERROR) == 0){}else if(level.compareTo(NotifyLevelEnum.FATAL) == 0){}}/*** 分页获取异常日志列表** @param pageNo 页码* @param size 每页数据量* @param serviceName* @param beginTime* @param endTime** @return*/
@Overridepublic PagedPfExceptionLogStruct queryExceptionLogList(int pageNo, int size, String serviceName, Long beginTime, Long endTime) {Date beginTimeDate = beginTime == null || beginTime <= 0 ? null : new Date(beginTime);Date endTimeDate = endTime == null || beginTime <= 0 ? null : new Date(endTime);int offset = pageNo < 1 ? 0 : (pageNo - 1) * size;List<PfExceptionLog> list = pfExceptionLogDao.selectPfExceptionLogList(offset , size , serviceName , beginTimeDate , endTimeDate);List<PfExceptionLogStruct> structList = new ArrayList<>();if (list != null || !list.isEmpty()) {for (PfExceptionLog pfExceptionLog: list) {structList.add(entityToStruct(pfExceptionLog));}}int total = pfExceptionLogDao.selectPfExceptionLogListCount(serviceName , beginTimeDate , endTimeDate);int pages = total % size == 0 ? total/size : total/size + 1;PageInfo<PfExceptionLogStruct> page = new PageInfo<>(structList);PagedPfExceptionLogStruct result = new PagedPfExceptionLogStruct(pageNo, total, pages, page.getList());return result;}private PfExceptionLogStruct entityToStruct(PfExceptionLog pfExceptionLog) {if (pfExceptionLog == null) {return null;}PfExceptionLogStruct pfExceptionLogStruct = new PfExceptionLogStruct();pfExceptionLogStruct.id = pfExceptionLog.getId();pfExceptionLogStruct.environment = pfExceptionLog.getEnvironment();pfExceptionLogStruct.exceptionClass = pfExceptionLog.getExceptionClass();pfExceptionLogStruct.exceptionTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(pfExceptionLog.getExceptionTime());pfExceptionLogStruct.resultCode = pfExceptionLog.getResultCode();pfExceptionLogStruct.serviceName = pfExceptionLog.getServiceName();pfExceptionLogStruct.stackTrace = pfExceptionLog.getStackTrace();return pfExceptionLogStruct;}/*** 根据异常日志id 获取异常日志详情** @param id 异常日志id** @return*/@Overridepublic PfExceptionLogStruct queryExceptionLogById(int id) {PfExceptionLog pfExceptionLog = pfExceptionLogDao.selectByPrimaryKey(id);return entityToStruct(pfExceptionLog);}
}
MultipleDataSourceAop.java多数据源自动切换切面类
package com.xxx.pubfound.aop;import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;import com.shangde.gfw.util.proxy.ProxyUtil;
import com.xxx.pubfound.MultipleDataSource;
import com.xxx.pubfound.aop.anntion.DataSourceType;/****
* Project Name:gfw-public-foundation-impl
* <p>多数据源自动切换通知类(拦截com.xxx.pubfound.dao中所有的类中的方法)<br>
* 首先判断当前类是否被该DataSourceType注解进行注释,如果没有采用默认的uam数据源配置;<br>
* 如果有,则读取注解中的value值,将数据源切到value指定的数据源
* @ClassName: MultipleDataSourceAspectAdvice
* @date 2018年5月18日 下午5:13:51
*
* @author youqiang.xiong
* @version 1.0
* @since*/
@Component
@Aspect
public class MultipleDataSourceAop {private final Logger logger = LoggerFactory.getLogger(getClass());/**** * Project Name gfw-public-foundation-impl* <p>* 拦截 pubfound.service中所有的方法,根据情况进行数据源切换** @author youqiang.xiong* @date 2018年5月18日 下午5:49:48* @version v1.0* @since* @param pjp* 连接点* @throws Throwable* 抛出异常*/@Before("execution(* com.xxx.pubfound.service.*.*(..))")public void changeDataSource(JoinPoint joinPoint) throws Throwable {Object target = ProxyUtil.getTarget(joinPoint.getTarget());if(target.getClass().isAnnotationPresent(DataSourceType.class)){DataSourceType dataSourceType = target.getClass().getAnnotation(DataSourceType.class);String type = dataSourceType.value();logger.info("数据源切换至--->{}",type);MultipleDataSource.setDataSourceKey(type);}else{logger.info("此{}不涉及数据源操作.",target.getClass());}}
}





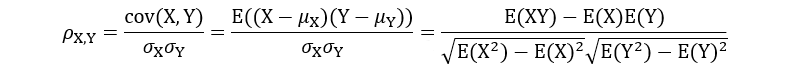

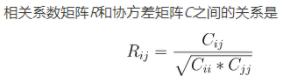

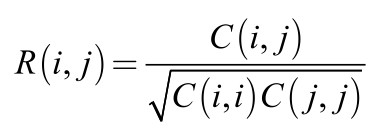


![MATLAB 协方差 [cov] 和相关系数 [corrcoef] 说明](https://img-blog.csdnimg.cn/img_convert/29b00a20cdc3d5619eec7b59b5d84261.bmp)