0 序言
时间已经进入了2023年,今年将是属于我们这一届秋招的一年。回顾2022年的学习和实习历程,我觉得今年学习收获还是不少的,甚至可以说是整个高等教育生涯中,收获最多的一年。
1 学习情况总结
1.1 读书和学习总结
1.1.1 对于Java的学习
原来按照本科毕业那年既定的计划来看的话,我是打算转Java的。不过,今年2023届秋招Java岗的情况似乎不容乐观,身边好多我觉得能力出众的Java大佬都铩羽而归,最终只去了一些中厂和外资,这些单位开出的工资和大厂还是有一定差距的,着实为他们惋惜。
于是,我就只能减少投入到学习Java中的时间,并打算重新回归C/C++。在2022年年初,精力几乎都投入到了java的学习中去了,读完了《Head First Java》和《java核心技术》卷I和卷II的主要部分,并结合《疯狂spring boot终极讲义》以及springboot实战三剑客系列的书,系统的学习了一遍ssm。虽然之前也写过一些java的项目,但无非是淘宝接单群里的那种学生课设,那会还真没有接触过企业级的java开发,对于一些java的八股文也有所欠缺,所以主要补的是基础知识。
随着4,5月暑期实习简历的投递,以及今年9月秋招的到来,互联网行情变差的问题也显露出来,尤其Java,已经不是2020年那会,来人就给offer的境遇了,于是我把目光重新转向了C++。
1.1.2 对于C++的学习
我自以为自己C++的基础还是可以的,实习经历也有一段(虽然是名不见经传的小单位)。该单位位于南京,属于制造业,是做变电器的。而我们工作的是为变电器开发控制软件,用于控制变电器的电压等参数。具体做的是Qt开发,写套接字编程向后端发送命令以控制变电器设备。
关于C++的学习,我大致是阅读完了之前本科时期没有读完的,两本久仰大名的书——侯捷翻译的《Essential C++》和《Effective C++》。
1.1.3 对于Scala的学习
可以说,自从接触到大数据组件后,就很难避免与Scala打交道,正如同接触到后端开发,就很难避免与Java打交道。研二充裕的时间给予了我系统学习Scala的可能。
我学习scala的基本方法, 是根据《Scala编程》一书的知识进行学习。一开始,我看了几集尚硅谷的教程,发现实在是太浪费时间了,还是直接看书来的快。Scala底层用的是Java,和Python挺像的,入手也快。就像《Head First Java》是面向有C/C++基础的读者,有C/C++基础的人看学java看《Head First Java》是很容易入手Java的。当时,也是听了MetaNovas里同事的建议,看了这本书,确实比直接看《Java核心技术》来的快,但要了解更加细节的内容的话,《Java核心技术》这本书是避免不了的。
1.2 竞赛情况总结
今年(2022年)参加了3场数学建模类的竞赛,分别是美国数学建模比赛(MCM)、mathorCup和五一赛。参加五一赛和mathorCup原本是为了防止MCM铩羽而归,导致之前为比赛做的准备完全泡汤而参加的。所以,我在参加完MCM后,又参加了mathorCup和五一杯。最终MCM比赛结果出乎预料,拿了M奖。美赛是数学建模领域最权威的比赛,也是唯一权威的全球性赛事,且M奖获奖率在5-7%,这个结果确实是令人心满意足。就这样,我算是圆满的结束了高等教育阶段的比赛生涯,彻底AFK了。而mathorCup和五一杯的结果也不再重要,更像是为了组员而参加似的。
2 秋招准备
2023年春与秋是24届应届生的主战场,尤其是3-4月份的暑期实习招聘,是秋招之前竞争最为惨烈的战场。到目前为止,我复习完了计网和操作系统的八股文,由于当年考过CCNA的缘故,我有一定的底子,计算机网络的复习速度还是挺快的。截止到目前,我刚刚完成了计算机网络和操作系统两门专业课的复习,接着就准备开始复习数据结构的面试题了。
3 对2021年实习的回忆
3.1在阿伯茨科技南京分部实习的回忆
北京阿博茨科技有限公司是由原海豚浏览器团队的骨干们建立的,CEO正是原来海豚浏览器团队的一把手杨永智,而坐镇南京的高管是余宙。
我大致在2020年8月在BOSS上投递了简历,面试官很NICE,问的我也都答出来了。他要我9月去上班,然而到了9月份,我的辅导员吴庆洲以疫情为由不批大家的出门申请,而隔壁的辅导员都是全批的(是的,其他人点名都是表示感激和致敬,就他例外),后来听本科的同学说,那几个能出门的学生都是给他塞了红包才解决问题的(那会是我太年轻了)。不过,正因为我那会没有去实习,而是老老实实呆在学校里复习考研,才最终上岸(其实呢,我得感谢他没放我出去实习,不然我没考上研究生的话,我的现在一切都不会这么好,但收红包的事情我觉得是真的腐败,我这里表示强烈谴责)。
到后来,在2021年3月我在我校的研究生拟录取名单中看到了自己的名字后,我便开始找实习,以填补自己对python实习经历的缺失。在这时,我想起了自己之前给北京阿博茨科技投过简历的事。
于是,我重新联系了之前HR,HR王欢让我重发简历重新面试。不过呢这次面试就是唠嗑,直接让我过了,几天后我就去实习了。那个时候也没有相关法律,监管也不严。工作内容主要是爬虫,爬取各大基金网站的数据用以数据分析。这里,要特意指出为什么不爬天天基金的数据,而是单独爬取各个基金网站的数据,因为天天基金的数据是二手的,曾经因为天天基金的数据有误,导致团队被甲方喷的很惨(这是leader和我解释的),所以公司高管们一致认为,必须从各个原本的基金网站爬取一手的数据。我除了成为一个无情的取数机器外(哈哈这是自嘲),我的mentor除了教我技术,还教会了我不少为人处世的东西,真的很感谢他,这是我真正走进社会的开始。
除此之外,主要是对各大基金网站和Debank、非小号网站的数据进行提取、清洗、存储。并按照要求推进其他项目。例如,编写数据爬虫代码并进行模块化封装,爬虫并将数据入库,使得公司自研的资产管理投研金融数据平台Fin.data顺利运转。同时爬取各个公募基金的公告并入库,用于Everdroid.ai平台,该平台旨在提供非结构化数据提取和解析能力,应用场景如财务报告解析、证件识别。
以下是当时工作时候的一些总结:
爬虫被锁IP,报“很抱歉,由于您访问的URL有可能对网站造成安全威胁,您的访问被阻断。 您的请求ID是······“![]() https://timtian.blog.csdn.net/article/details/116696336DeBank和非小号网站的数据分析-实习工作小结
https://timtian.blog.csdn.net/article/details/116696336DeBank和非小号网站的数据分析-实习工作小结![]() https://timtian.blog.csdn.net/article/details/123150014 最终,还拿到了return offer。我就纳闷,为什么我们组的leader不知道我要去读研的事情呢?我明明和HR交待了的啊~
https://timtian.blog.csdn.net/article/details/123150014 最终,还拿到了return offer。我就纳闷,为什么我们组的leader不知道我要去读研的事情呢?我明明和HR交待了的啊~
4 2022年实习总结
今年(指2022年,虽然是在2023年的时候发出来的,但是本文的“今年”都是指2022年)一共在三个单位实习,3-6月是研一下学期。很不幸,苏州因为疫情静默,哈尔滨随后也因为疫情静默,因此并没有去学校,而是呆在家中学习,也籍此获得了两个实习机会。
4.1 在上海元炘执药科技有限公司|MetaNovas的实习
我在元炘执药(元星智药)的工号是P004,即全部门的第4号实习员工,我是在公司组建之初加入的。一开始,我在BOSS直聘上收到我司的面试邀请,想着用来增加面试经验也是不错的,于是就接受了HR的面试邀请。出乎意料的是,面试官给出的题目都比较对我胃口。然后,我的笔试和面试都比较顺利,最终顺利通过了。HR开出了200/天的薪资,并告知我支持远程办公(当时上海正处于静默),我想着我一边上网课一边实习,能拿学位证还能增加实习经历还能赚钱,这岂不美哉!入职!
入职之后,我发现单位领导和同事都是很NICE的。公司学历门槛很高,全部门就我一个211,其他实习同学以华五居多(尤其是复旦和交大),再不济也是个985,除此之外就是MIT之类的美国名校,第一次能和这么多大佬们一起上班还是很激动的。由于加入时间较早,我们组的组长也是部门领导余论,他是个和蔼可亲的人,真就手把手教人,对于我个人能力提升确实很大,我真是感激他。我们组主要负责基础设施的建设,例如elasticsearch、neo4j和airflow,这三个是第一阶段的工作任务,第二阶段是搭建Hadoop以供后期Flink使用。
在这里我不得不对之前没有来得及写的实习总结做一个补充。在文章实习小结·改进代码(解决爆栈问题)![]() https://blog.csdn.net/qq_41938259/article/details/123914290?spm=1001.2014.3001.5501中,我讲述了我在EC2服务器上运行python脚本时遇到out of menory问题的解决方案。由于xml文件较大,一次性提取所有数据加载到内存中,引发爆栈使得linux内核kill掉了python进程,进而引发out of menory问题。我当初得想法是一条一条数据发,确实是解决了爆栈的问题,但是领导第二天就和我说,你一条条发,反复建立连接断开连接,会大量消耗服务器资源的,等同于在搞DDOS攻击。我想了下,确实是如此。我进而改为每50000条数据发一次(每个xml文件的数据量大致是百万级的)。实现方式就是加一个变量cnt并初始化为0,每清洗一条数据就让cnt自增,当cnt==50000时或者文件读到尾时,便将数据发送一次。代码修改后如下:
https://blog.csdn.net/qq_41938259/article/details/123914290?spm=1001.2014.3001.5501中,我讲述了我在EC2服务器上运行python脚本时遇到out of menory问题的解决方案。由于xml文件较大,一次性提取所有数据加载到内存中,引发爆栈使得linux内核kill掉了python进程,进而引发out of menory问题。我当初得想法是一条一条数据发,确实是解决了爆栈的问题,但是领导第二天就和我说,你一条条发,反复建立连接断开连接,会大量消耗服务器资源的,等同于在搞DDOS攻击。我想了下,确实是如此。我进而改为每50000条数据发一次(每个xml文件的数据量大致是百万级的)。实现方式就是加一个变量cnt并初始化为0,每清洗一条数据就让cnt自增,当cnt==50000时或者文件读到尾时,便将数据发送一次。代码修改后如下:
import logging
from lxml import etree
from elasticsearch import Elasticsearch# get data from xml file
def get_data(address):xml = etree.parse(address)root = xml.getroot()datas = root.xpath('//PubmedArticle/MedlineCitation')es = Elasticsearch(hosts=['http://localhost:9200'])// cnt是计数器 cnt = 0// data_size是data的总长度data_size = len(data)for data in datas:// 每一条数据,cnt自增一次cnt += 1# print(data)if len(data.xpath('./DateCompleted')) != 0:year = data.xpath('./DateCompleted/Year/text()')[0]month = data.xpath('./DateCompleted/Month/text()')[0]day = data.xpath('./DateCompleted/Day/text()')[0]Date = month+'-'+day+'-'+year# print(Date)date_completed = Dateelse:date_completed = 'NULL'year = data.xpath('./DateRevised/Year/text()')[0]month = data.xpath('./DateRevised/Month/text()')[0]day = data.xpath('./DateRevised/Day/text()')[0]Date = month + '-' + day + '-' + yeardate_revised = Dateif len(data.xpath('./Article/Journal/ISSN/text()')) != 0:issn = data.xpath('./Article/Journal/ISSN/text()')[0]# print(issn)ISSN = issnelse:ISSN = 'NULL'id = data.xpath('./PMID/text()')[0]if id != '':ID = idelse:ID = 'NULL'if len(data.xpath('./parent::*/PubmedData/ArticleIdList/ArticleId[@IdType="doi"]/text()')) != 0:doi = data.xpath('./parent::*/PubmedData/ArticleIdList/ArticleId[@IdType="doi"]/text()')[0]# print(doi)DOI = doielse:DOI = '0'title = data.xpath('./Article/ArticleTitle/text()')if len(title) != 0:# print(title)Title = title[0]else:Title = 'NULL'Abstract = data.xpath('./Article/Abstract/AbstractText/text()')if len(Abstract) == 1:AbstractList = Abstract[0]# print(Abstract)elif len(Abstract) == 0:AbstractList = 'NULL'else:length = len(Abstract)# print(length)AbstractString = ''for tmp in Abstract:AbstractString.join(tmp)# Abstract = data.xpath('./Article/Abstract/AbstractText/text()')[0]# Abstract = data.xpath('./Article/Abstract/AbstractText[@Label="BACKGROUND"]/text()')[0]AbstractList = AbstractString# print(AbstractString)authorLastName = data.xpath('./Article/AuthorList/Author/LastName/text()')authorForeName = data.xpath('./Article/AuthorList/Author/ForeName/text()')authorName = []if len(authorForeName) != 0 and len(authorLastName) != 0 and len(authorForeName) == len(authorLastName):for i in range(len(authorLastName)):authorName.append(authorForeName[i] + ' ' + authorLastName[i] + ',')# print(authorName)Names = "".join(authorName)else:Names = "NULL"jsonData = {"title": Title,"Authors": Names,"abstract": AbstractList,"date": {"completed_date": date_completed,"revised_date": date_revised,},"journal_issn": ISSN,"journal_doi": DOI,"article_id": ID}// 当cnt为50000时发送数据,这样既不会爆栈也不会变成DDOS攻击// 当然读到文件结尾时,即使不满50000也需要发送数据,故cnt == data_sizeif cnt == 50000 || cnt == data_size:index_name = "pubmed-paper-index"es.index(index=index_name, body=jsonData)if __name__ == '__main__':# List of pending documentsaddress = []path1 = "pubmed22n"path2 = ".xml.gz"path = ''for i in range(715, 1115):if i >0 and i <= 9:path = path1 + '000' + str(i) +path2address.append(path)elif i >= 10 and i<= 99:path = path1 + '00' + str(i) + path2address.append(path)elif i >= 100 and i <= 999:path = path1 + '0' + str(i) + path2address.append(path)else:path = path1 + str(i) + path2address.append(path)# process the filefor add in address:get_data(add)logging.basicConfig()logger = logging.getLogger(__name__)logger.setLevel(logging.INFO)logger.info(add + f"finished!")第二个问题,仍然是在以上的场景中。不过是在我做完了自动化脚本后才被提出来的。自动化脚本的文章介绍在这里:
实习工作小结——下载和导入Elasticsearch模块实现自动比对的功能![]() https://timtian.blog.csdn.net/article/details/124319573?spm=1001.2014.3001.5502
https://timtian.blog.csdn.net/article/details/124319573?spm=1001.2014.3001.5502
该问题在于,当python脚本的进程被KILL时,如果重新导入该文件自然会很耗时,那怎么从断开的地方重新写入?
很明显try-except语句是无法处理的,原因是进程都被kill掉了,try-except语句就无法继续执行了。这里的解决方案是使用日志,在每次遍历的时候,将主键pmid覆盖输出到日志文件,于是自动化脚本重新执行时增加参数,代码中使用sys.argv[]用来接收命令行中参数,用以判断这一轮是否是因为之前断开后,而重新进行的。是的话,脚本会读取日志文件获得pmid的值,于是便从与该pmid一致的数据开始,进行写入操作。此时,问题便被解决了。
第三个事情是,重做了前端检索页面,原来我展示的前端是这样的:为基于elasticsearch和flask的web端检索系统增加新的检索功能![]() https://timtian.blog.csdn.net/article/details/125389132?spm=1001.2014.3001.5502 前端写的肉眼可见的糟糕。我本来准备写一篇博客来特别介绍下的。结果那段时间我事情有点多,直到离职之后我都没来得及写,原来项目的github仓库是私有的,于是现在也下载不到代码,那篇博客就这么被耽搁了。
https://timtian.blog.csdn.net/article/details/125389132?spm=1001.2014.3001.5502 前端写的肉眼可见的糟糕。我本来准备写一篇博客来特别介绍下的。结果那段时间我事情有点多,直到离职之后我都没来得及写,原来项目的github仓库是私有的,于是现在也下载不到代码,那篇博客就这么被耽搁了。
接下来,我来介绍下我们元星制药工程部门数仓建模相关的内容:ODS层使用的是S3,直接存放XML文件的gzip压缩包,然后我们读取压缩包并解压将数据放入ES中,所以我认为我负责的ES的工作,应该属于DWD层,而后期搭建的HIVE更多的是负责DIM层和DWS层,关于ADS层同样使用的是ES,因为一些项目对检索速度要求比较高,是直接从ES取数据的。
4.2 在上海星环科技的实习
一开始在面试的时候,小组leader也是当时我的面试官征露姐就指出,组里都是学数科的,所以代码量很少,而数据治理主要都是些人工完成的内容,需要我有耐心。我欣然接受了,一是因为280/天给的是真的高,还有房补1000,虽然房补需要租房合同,住长辈家是拿不到的,但280/天我也知足了。其次就是,那会我对于数仓理论和概念的了解确实不是很清晰,而星环该团队对这一方面确实有一定的话语权,和他们共事,我确实能对数仓理论和概念得到一个清晰而直观的了解。
依我愚见,光阅读《大数据之路》一书,读者们和我一样,恐怕很难理解书中的概念。但是,我经过了这次实习,对于数仓理论,我有种拨开云雾见青天的感觉。在以前,对于我来讲往往工作只是工作,并不知道自己在干嘛,自己工作的意义何在,通过这次实习,我对数仓理论和概念有了更深刻的了解。回过头来总结时,我确实是对自己在前两次实习中做的事情有了一个大致的定位。
星环的这个项目是东方航空委托的一个数据治理的项目,在此期间我学习了excel的操作,尤其是透视表的操作。由于组内都是数科的童鞋和老师们,于是工作中的代码量并不是很大,主要就是使用EXCEL,当然也可以使用python写自动化脚本,反正只要最终实现得没问题就行。还有就是绘制一些统计学图表,JD是数据开发的工作有一点像BI工程师。同时,我还要整理元数据和绘制血缘图谱。
什么是血缘图谱?血缘图谱是根据元数据描绘各个系统间的关系,以及各个系统得各个表间的关系的图标。元数据分为业务类的和技术类的,首先要将业务类的元数据手工筛选出来,然后才能绘制依此绘制血缘图谱。
这里,我来介绍下我们的工作流程。首先是统计,统计汇总各个系统的名称和用途并确定对应的梳理者。扶着梳理的人找系统对应的表,梳理所有字段,统计表的完整性,如果这个表空缺值太多,那我们就舍弃,留下的都是有价值的表。第二阶段猜测各个字段的含义,并区分数据为业务数据、元数据、存疑三部分(如何区分?一般是找到对应的系统,根据相关功能并使用SQL查询表格具体内容来确定)最后按照自己的想法绘制血缘图谱,等一轮梳理结束后(可能是2-4个系统)找业务方沟通,确定自己的猜测是否正确,并进行修改直至完善。
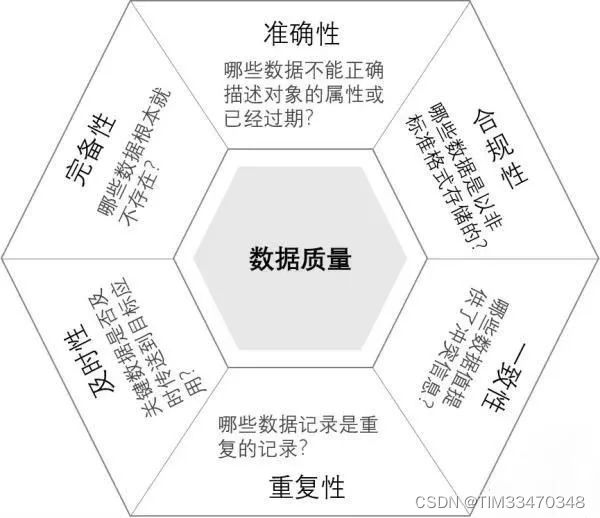
关于数据质量评估的办法,我离职的比较早,没有介入相关的工作。但是后来我问了下buddy,她告知我,我们组是根据数据质量的六性进行数据质量检查的。什么是数据质量的六性呢?我找了篇文章,可以参考下:
数据质量管理:6个维度,50个检查项!![]() https://blog.csdn.net/mm_ren/article/details/119307351 其中,02. 数据质量维度讲述的就是数据质量的六性。
https://blog.csdn.net/mm_ren/article/details/119307351 其中,02. 数据质量维度讲述的就是数据质量的六性。
接着,我升入了研二,前往北京,开始了在航天科技第五研究院503所的实习。
4.3 在航天五院503所的实习
我于2020年7月3日入职卫星通信事业部,目前经手了两个项目,都是与starlink相关的。一个是总控平台,另外是一个是星间链路可视化的项目,密级都是保密10年。总控平台后端使用的spring boot前端使用的vue.js,星间链路可视化的那个项目后端使用的是django前端还是vue.js。前者(总控平台)我负责前后端的编写,俨然变成了全栈(大雾)。后者(星间链路可视化)我只负责前端vue.js但并不意味着轻松,项目时间吃紧甚至比全栈还难受。
期间,我被调去中国资源卫星中心做测试,具体内容是给starlink测速,并传文件用于评估链路稳定性。虽然是杂活,但也收获不少,当然这只是其中的一个缩影。最让我吃惊的涉密文件需要人肉快递(就是说得你自己随身携带送到目的地)。军工企业确实与普通IT企业有很大差距,航天系统里都是令人瞻仰的伟大科学家们,是我值得学习并为之奋斗终生的榜样。
5 结语——尚未结束的故事
这里我想到了《高堡奇人》最后一季,主人公朱丽·安娜一直追随着财政大臣田上信介的占卜——田上曾经预言结局将遵循第三十六卦。于是,朱丽安娜按照田上的遗言翻寻《易经》,发现第三十六卦是大大吉,释义是“未完成之事”。最终,安娜完成了“未完成之事”,我希望我也能完成我自己的“未完成之事”。
此文谨以纪念2022年——这奋斗的一年。










![[ 和你一起终身学习]---家长也是需要学习,需要成长的](https://img-blog.csdnimg.cn/20181104220825695.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTMwNjc3NTY=,size_16,color_FFFFFF,t_70)
