一、项目有前后端分离和前后端不分离:
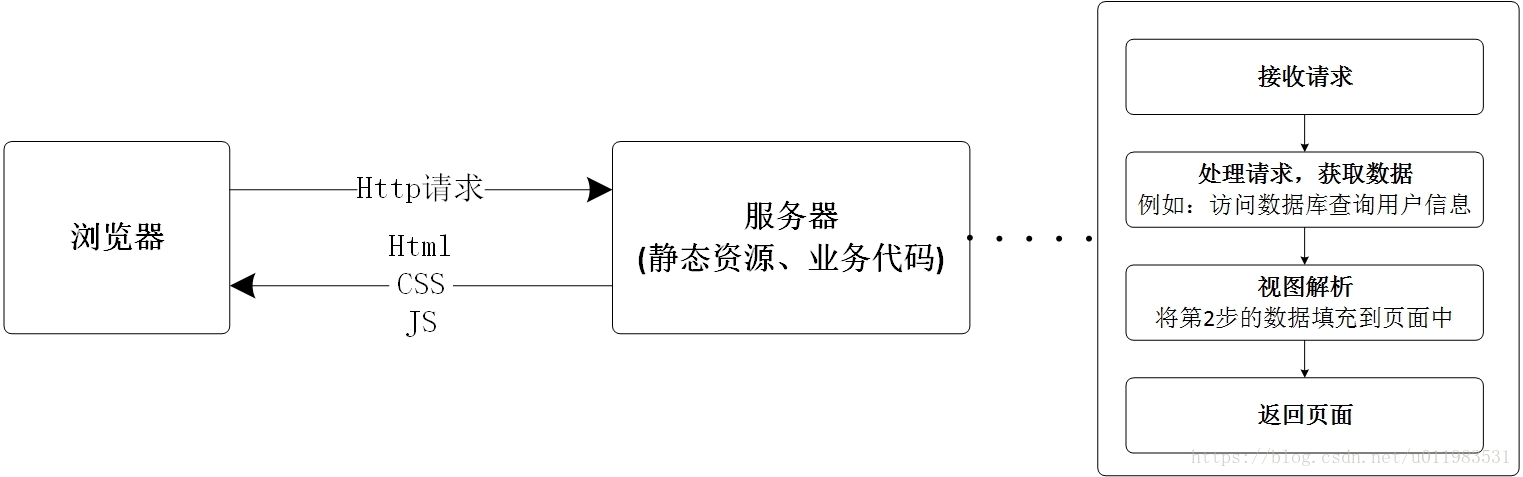
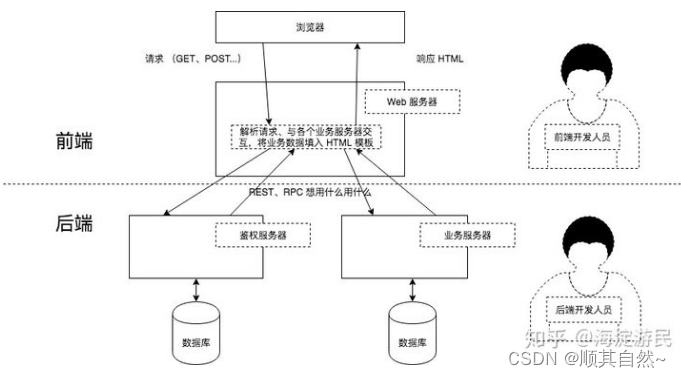
在前后端不分离架构中,所有的静态资源和业务代码统一部署在同一台服务器上。服务器接收到浏览器的请求后,进行处理得到数据,然后将数据填充到静态页面中,最终返回给浏览器。
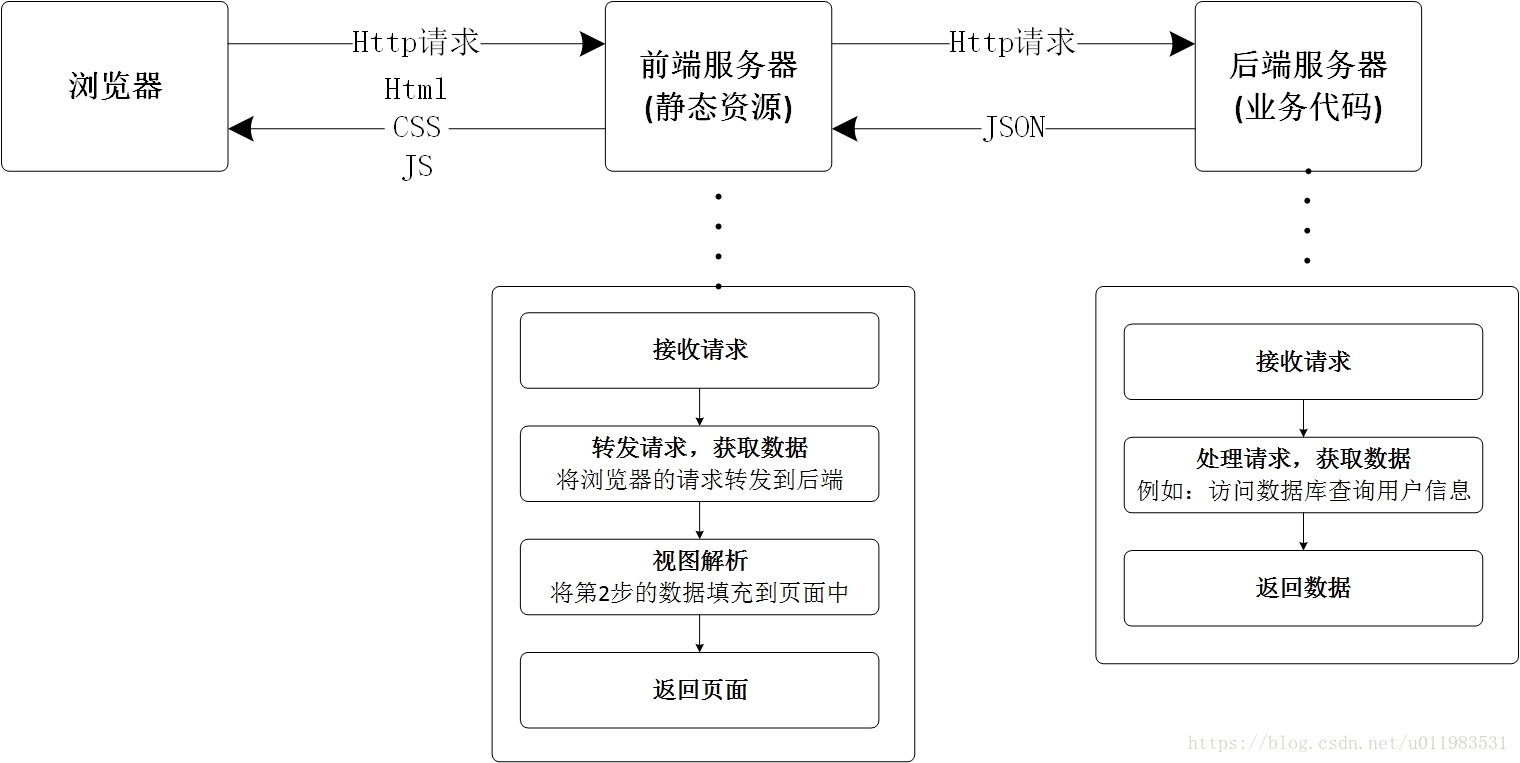
实现前后端分离后,有了下面几点改变:
1.服务器一分为二,前后端分别部署,静态资源放在前端服务器,业务代码放在后的服务器
2.前端服务器需要接收Http请求(一般使用node.js)
3.前端服务器需要进行视图解析(可以使用vue.js、angular.js)
4.前端服务器需要处理路由(也就是页面之间的跳转逻辑)
5.后端服务器只需要返回数据
一、前言
前后端分离已成为互联网项目开发的业界标准使用方式,通过nginx+tomcat的方式(也可以中间加一个nodejs)有效的进行解耦,并且前后端分离会为以后的大型分布式架构、弹性计算架构、微服务架构、多端化服务(多种客户端,例如:浏览器,车载终端,安卓,IOS等等)打下坚实的基础。这个步骤是系统架构从猿进化成人的必经之路。
核心思想是前端html页面通过ajax调用后端的restuful api接口并使用json数据进行交互。
在互联网架构中,名词解释:
Web服务器:一般指像nginx,apache这类的服务器,他们一般只能解析静态资源。
应用服务器:一般指像tomcat,jetty,resin这类的服务器可以解析动态资源也可以解析静态资源,但解析静态资源的能力没有web服务器好。
二、技术分工(开发人员分离)
以前的JavaWeb项目大多数都是java程序员又当爹又当妈,又搞前端,又搞后端。
随着时代的发展,渐渐的许多大中小公司开始把前后端的界限分的越来越明确,前端工程师只管前端的事情,后端工程师只管后端的事情。正所谓术业有专攻,一个人如果什么都会,那么他毕竟什么都不精。大中型公司需要专业人才,小公司需要全才,但是对于个人职业发展来说,我建议是分开。
1、对于后端java工程师:(负责Model层,业务处理/数据等)
把精力放在java基础,设计模式,jvm原理,spring+springmvc原理及源码,linux,mysql事务隔离与锁机制,mongodb,http/tcp,多线程,分布式架构,弹性计算架构,微服务架构,java性能优化,以及相关的项目管理等等。
后端追求的是:三高(高并发,高可用,高性能),安全,存储,业务等等。
2、对于前端工程师:(负责View和Controller层。)
把精力放在html5,css3,jquery,angularjs,bootstrap,reactjs,vuejs,webpack,less/sass,gulp,nodejs,Google V8引擎,javascript多线程,模块化,面向切面编程,设计模式,浏览器兼容性,性能优化等等。
前端追求的是:页面表现,速度流畅,兼容性,用户体验等等。
术业有专攻,这样你的核心竞争力才会越来越高,正所谓你往生活中投入什么,生活就会反馈给你什么。并且两端的发展都越来越高深,你想什么都会,那你毕竟什么都不精。
通过将team分成前后端team,让两边的工程师更加专注各自的领域,独立治理,然后构建出一个全栈式的精益求精的team。
三、开发模式
以前老的方式是:
产品经历/领导/客户提出需求===》UI做出设计图 ===》前端工程师做html页面===》后端工程师将html页面套成jsp页面(前后端强依赖,后端必须要等前端的html做好才能套jsp。如果html发生变更,就更痛了,开发效率低)===》集成出现问题 ===》前端返工 ===》后端返工===》二次集成 ===》集成成功 ==》交付
新的方式是:
产品经历/领导/客户提出需===》UI做出设计图 ===》前后端约定接口&数据&参数 ===》前后端并行开发(无强依赖,可前后端并行开发,如果需求变更,只要接口&参数不变,就不用两边都修改代码,开发效率高)===》前后端集成 ===》前端页面调整 ===》集成成功 ===》交付
四、请求方式
以前老的方式是:
1、客户端请求
2、服务端的servlet或controller接收请求(后端控制路由与渲染页面,整个项目开发的权重大部分在后端)
3、调用service,dao代码完成业务逻辑
4、返回jsp
5、jsp展现一些动态的代码
新的方式是:
1、浏览器发送请求
2、直接到达html页面(前端控制路由与渲染页面,整个项目开发的权重前移)
3、html页面负责调用服务端接口产生数据(通过ajax等等,后台返回json格式数据,json数据格式因为简洁高效而取代xml)
4、填充html,展现动态效果,在页面上进行解析并操作DOM。
总结一下新的方式的请求步骤:
大量并发浏览器请求--->web服务器集群(nginx)--->应用服务器集群(tomcat)--->文件/数据库/缓存/消息队列服务器集群同时又可以玩分模块,还可以按业务拆成一个个的小集群,为后面的架构升级做准备。
五、前后分离的优势
1、可以实现真正的前后端解耦,前端服务器使用nginx。前端/WEB服务器放的是css,js,图片等等一系列静态资源(甚至你还可以css,js,图片等资源放到特定的文件服务器,例如阿里云的oss,并使用cdn加速),前端服务器负责控制页面引用&跳转&路由,前端页面异步调用后端的接口,后端/应用服务器使用tomcat(把tomcat想象成一个数据提供者),加快整体响应速度。(这里需要使用一些前端工程化的框架比如nodejs,react,router,react,redux,webpack)
2、发现bug,可以快速定位是谁的问题,不会出现互相踢皮球的现象。页面逻辑,跳转错误,浏览器兼容性问题,脚本错误,页面样式等问题,全部由前端工程师来负责。接口数据出错,数据没有提交成功,应答超时等问题,全部由后端工程师来解决。双方互不干扰,前端与后端是相亲相爱的一家人。
3、在大并发情况下,我可以同时水平扩展前后端服务器,比如淘宝的一个首页就需要2000+台前端服务器做集群来抗住日均多少亿+的日均pv。(去参加阿里的技术峰会,听他们说他们的web容器都是自己写的,就算他单实例抗10万http并发,2000台是2亿http并发,并且他们还可以根据预知洪峰来无限拓展,很恐怖,就一个首页。。。)
4、减少后端服务器的并发/负载压力。除了接口以外的其他所有http请求全部转移到前端nginx上,接口的请求调用tomcat,参考nginx反向代理tomcat。且除了第一次页面请求外,浏览器会大量调用本地缓存。
5、即使后端服务暂时超时或者宕机了,前端页面也会正常访问,只不过数据刷不出来而已。
6、也许你也需要有微信相关的轻应用,那样你的接口完全可以共用,如果也有app相关的服务,那么只要通过一些代码重构,也可以大量复用接口,提升效率。(多端应用)
7、页面显示的东西再多也不怕,因为是异步加载。
8、nginx支持页面热部署,不用重启服务器,前端升级更无缝。
9、增加代码的维护性&易读性(前后端耦在一起的代码读起来相当费劲)。
10、提升开发效率,因为可以前后端并行开发,而不是像以前的强依赖。
11、在nginx中部署证书,外网使用https访问,并且只开放443和80端口,其他端口一律关闭(防止黑客端口扫描),内网使用http,性能和安全都有保障。
12、前端大量的组件代码得以复用,组件化,提升开发效率,抽出来!
六、注意事项
1、在开需求会议的时候,前后端工程师必须全部参加,并且需要制定好接口文档,后端工程师要写好测试用例(2个维度),不要让前端工程师充当你的专职测试,推荐使用chrome的插件postman或soapui或jmeter,service层的测试用例拿junit写。ps:前端也可以玩单元测试吗?
2、上述的接口并不是java里的interface,说白了调用接口就是调用你controler里的方法。
3、加重了前端团队的工作量,减轻了后端团队的工作量,提高了性能和可扩展性。
4、我们需要一些前端的框架来解决类似于页面嵌套,分页,页面跳转控制等功能。(上面提到的那些前端框架)。
5、如果你的项目很小,或者是一个单纯的内网项目,那你大可放心,不用任何架构而言,但是如果你的项目是外网项目,呵呵哒。
6、 以前还有人在使用类似于velocity/freemarker等模板框架来生成静态页面,仁者见仁智者见智。
7、这篇文章主要的目的是说jsp在大型外网java web项目中被淘汰掉,可没说jsp可以完全不学,对于一些学生朋友来说,jsp/servlet等相关的java web基础还是要掌握牢的,不然你以为springmvc这种框架是基于什么来写的?
8、如果页面上有一些权限等等相关的校验,那么这些相关的数据也可以通过ajax从接口里拿。
9、对于既可以前端做也可以后端做的逻辑,我建议是放到前端,为什么?因为你的逻辑需要计算资源进行计算,如果放到后端去run逻辑,则会消耗带宽&内存&cpu等等计算资源,你要记住一点就是服务端的计算资源是有限的,而如果放到前端,使用的是客户端的计算资源,这样你的服务端负载就会下降(高并发场景)。类似于数据校验这种,前后端都需要做!
10、前端需要有机制应对后端请求超时以及后端服务宕机的情况,友好的展示给用户
原文:https://blog.csdn.net/bntX2jSQfEHy7/article/details/80589580
二、前后端接口联调:
前言:
以JC同事为例,他公司为前后端分离架构,前端vue全家桶;前后端人员开会协商数据接口后(主要是定义传输的数据和API接口),前后端并行开发;因为后台此时无法提供后端数据,所以前端需要用mock模拟假数据,管理API接口,获取数据,到时接口联调时连接后端服务器,访问后端数据即可。
但是JC同事的ajax的借口写的是与后端叔叔商量好的绝对路径(域名+请求路径+请求参数,跨域问题已解决),因为这是以后真正的请求路径,所以JC同事又不像先写本地相对路径,后期再来修改(万一后台叔叔开发的慢了,鬼知道有多少接口要修改呀)。于是他就迷茫了。。。
仔细看看这其实就是前后端分离中的mock数据和联调的问题,就现在来说能解决的方式有很多种。先说mock数据,gulp,webpack, fekit (去哪儿网的一款前端自动化构建工具,据说历史比webpack和gulp都要久远)等等自动化构建工具都有mock数据的功能,这不是问题;再说绝对路径的问题,其实只需要做一个host的映射就行了。
一、什么是前后端接口联调
之前开发写代码的时候,所有的ajax数据都不是后端返回的真实数据,而是我们自己通过接口mock模拟的假数据,当前端的代码编写完毕,后端的接口也已经写好之后,我们就需要把mock数据干掉,尝试使用后端提供的数据,进行前后端的一个调试,这个过程我们就把它称之为前后端的接口联调。
为什么要联调 本地的mock数据是JC同事自己写的,肯定符合前端需求,但是后端接口首先需要测试通不通,还需要测试数据格式对不对,还有后端有没有填写足够的数据,比如写列表页,前端想分页,如果后端就写了两条测试数据,你咋整? 所以,Jack需要根据后端对接口的调整,不断地来回切换url,这样岂不是还在受后端的影响,还谈什么毛线的前后端分离,名存实亡嘛!
二、如何实现前后端接口联调
首先,我们已经知道,目前的前后端分离的架构应用分为两种情况:
前后端完全分离,前后端分别拥有自己的域名和服务器。
前后端开发分离,但是部署时是一个域名和一台服务器。
虽然架构可以采用前后端分离,但是部署有可能就不一样了,这和项目的大小,公司的情况等等都有关系了,一个百八十人用的小系统,还得两台服务器两个域名,你不觉着浪费吗?两种不同的部署情况直接导致了前期在设计联调方案的时候就不同了。
如果你们公司的项目在部署时是两台服务器对应两个域名,恭喜你,这是最nice的方案,也是联调最舒服的方式。第二种情况,也就是开发时前后端分离,部署时是一个域名和一台服务器。知道这个之后,他就明白接下来该怎么操作了。JC同事之前在项目根目录static文件夹下新建了一个mock文件夹,里面写了一些json文件,当我们做联调的时候,这些mock数据就没用了,我们要把mock数据切换成后端提供给我们的真实的数据。
当我的朋友Jack把static文件夹下的mock数据删除之后,在运行项目,发现报错了,浏览器告诉他,你访问的mock下面的index.json文件找不到404。
我们平时本地前端开发环境dev地址大多是 localhost:8080,而后台服务器的访问地址就有很多种情况了,比如 后端程序猿本地IP(127.0.0.1:8889),或者外网域名,当前端与后台进行数据交互时,自然就出现跨域问题(后台服务没做处理情况下)。axios不支持jsonp, 所以我们就要使用http-proxy-middleware中间件做代理。
现在通过在前端修改 vue-cli 的配置可解决: vue-cli中的 config/index.js 下配置 dev选项的 {proxyTable}:
proxyTable: {
'/api': {
target: '127.0.0.1:8889', // 真实请求的地址
changeOrigin: true, // 是否跨域
}
}
如果你想在公司的vue项目中实现前后端联调,不需要再使用类似于fiddler charles的抓包代理工具了,你只需要使用proxyTable这个配置项,把你需要请求的后端的服务器地址写在target值里就OK了。
解决完跨域问题后,接下来Jack该想想怎么在一台服务器一个域名下进行联调的问题了。比较常见的做法是前端在本地修改,本地查看,测试好了以后上传到服务器,看看线上环境可不可以,OK的话一切都好;不行就本地接着改,然后在上传。
联调完之后,如何将前端打包的项目文件发给后端,这里也需要注意两点:
(1)css、js和图片等静态文件
这时候的静态文件在开发阶段不需要任何考虑,按照你喜欢的相对路径或者相对于项目的根路径的形式写就行了,因为早晚还得交给后端。但是,需要注意:
如果你采用 相对项目根路径的书写方式来写你的静态文件路径 时,一定要先和后端商量好,将来项目部署的时候他会把你的前端整个项目放在哪里?如果不是根目录下,你就挂了。比如:你的reset.css的路径是 /exports/styles/common/reset.css ,后端把你前端项目放在了根目录下的 frontEnd 文件夹下, reset.css 文件就报404了。
如果后端采用的java,你需要特别注意的是, tomcat的根目录 并不是 webapps 文件,而后端项目默认是部署在 webapps/ROOT 文件下的,所以你如果使用了相对项目根路径的书写方式来写你的静态文件路径时,对不起又是404了。
(2)ajax后端数据
因为现在唯一的一台服务器还是在后端程序猿那里,所以此时你还是可以写绝对路径(域名+请求路径),利用hosts文件来改变域名映射实现联调。
https://www.douban.com/note/686499733/?type=rec#sep
三、前端性能优化
1.内容优化
(1)减少HTTP请求数
(3)避免重定向
(4)使用Ajax缓存
(5)延迟加载组件,预加载组件
(6)减少DOM元素数量
(7)避免404
2.服务器优化
(1)使用内容分发网络(CDN):把网站内容分散到多个、处于不同地域位置的服务器上可以加快下载速度。
(2)GZIP压缩
(3)设置ETag:ETags(Entity tags,实体标签)是web服务器和浏览器用于判断浏览器缓存中的内容和服务器中的原始内容是否匹配的一种机制。
(4)提前刷新缓冲区
(5)对Ajax请求使用GET方法
(6)避免空的图像src
3.Cookie优化
(1)减小Cookie大小
(2)针对Web组件使用域名无关的Cookie
4.CSS优化
1)将CSS代码放在HTML页面的顶部
2)避免使用CSS表达式
(3)使用<link>来代替@import
(4)避免使用Filters
5.javascript优化
(1)将JavaScript脚本放在页面的底部。
(2)将JavaScript和CSS作为外部文件来引用:在实际应用中使用外部文件可以提高页面速度,因为JavaScript和CSS文件都能在浏览器中产生缓存。
(3)缩小JavaScript和CSS
(4)删除重复的脚本
(5)最小化DOM的访问:使用JavaScript访问DOM元素比较慢。
(6)开发智能的事件处理程序
(7)javascript代码注意:谨慎使用with,避免使用eval Function函数,减少作用域链查找。
6.图像优化
(1)优化图片大小
(2)通过CSS Sprites优化图片
(3)不要在HTML中使用缩放图片
(4)favicon.ico要小而且可缓存
四、前端安全问题
1.算法加密:
(1) RSA加密
(2) MD5加密
(3) SHA256加密
推荐一个网址:https://www.haorooms.com/post/js_my_passwordjm