前面看了transformer的原理及源代码,今天实战下,看看他的效果;
一、环境
- win10
- DataX 3.0(从我的datax分支打包而来)
- job.json使用datax的样例json,源文件在xxx\DataX\core\src\main\job\中,打包编译后在xxx\DataX\target\datax\datax\job下。本文略做修改,主要修改2出,是否打印和记录行数
{"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"percentage": 0.02}},"content": [{"reader": {"name": "streamreader","parameter": {"column" : [{"value": "DataX","type": "string"},{"value": 19990704,"type": "long"},{"value": "1999-07-04 00:00:00","type": "date"},{"value": true,"type": "bool"},{"value": "test","type": "bytes"}],"sliceRecordCount": 1 // 原来是100000,修改为1行,看到效果就行}},"writer": {"name": "streamwriter","parameter": {"print": true, // 原来是false,不打印,为了在控制台看到效果,修改为true"encoding": "UTF-8"}}}]}
}
原job.json 解读:从streamreader中读取1行数据,写入streamwriter。streamreader里有5个字段(string,long,date,bool,bytes)对应的值分别为Datax、19990904、“1999-09-04 00:00:00”、true和“test”。job的全局设置是1个channel,容错率是0.02;
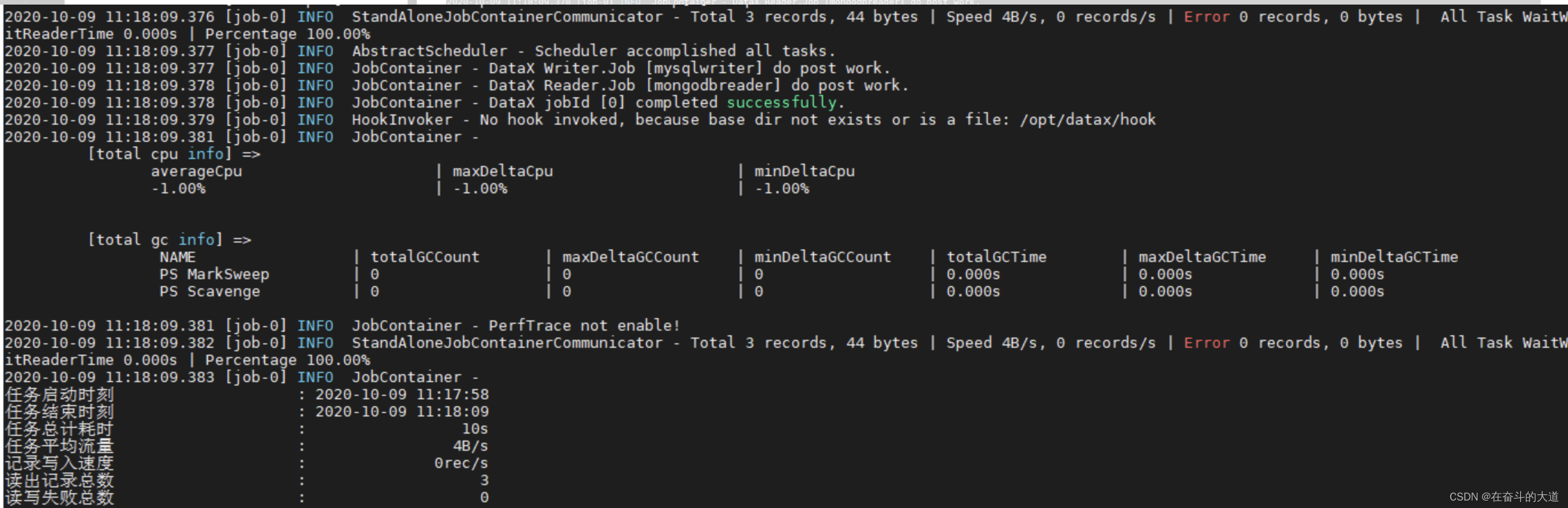
先看下不加transformer时候的运行效果

二、SubstrTransformer
在job中加入dx_substr类型的transformer
"transformer": [{"name": "dx_substr", //通过唯一标识符指定datax内置的transformer"parameter": {"columnIndex": 0, // col列的下标"paras": ["1", //从 col的哪个下标开始截取"4" //截取后该col 值的长度]}}]
效果如下:

解释:columnIndex为0获取的字段的值是“Datax”,将“Datax”从下标1开始,截取长度4,所以是“atax”
三、ReplaceTransformer
"transformer": [{"name": "dx_replace","parameter":{"columnIndex":0, //对下标为0的字段进行处理"paras":["3","4","****"] // 将下标3到4的字符内容替换为 ****}}]
效果:

解释:
columnIndex=0的字段的值是“Datax”,“Datax”的3到4位置内容是“ax”,将“ax”替换为****,最终结果是 Dat****
四、PadTransformer
"transformer": [{"name": "dx_pad","parameter":{"columnIndex":0,"paras":["l","9","-"] // l在头部填充,9是最后数据的长度,-是要填充的内容}}]
效果:

解释:
columnIndex=0的字段的值是“Datax”,在“Datax”的头部插入“-”,使其最后长度是9,最终结果是 ----Datax
五、FilterTransformer
"transformer": [{"name": "dx_filter","parameter": {"columnIndex": 1, // 取下标为1的字段"paras": [ // 过滤条件 <0 , 注意满足添加的数据会被过滤掉"<","0"]}}]
效果:
解释:
columnIndex=1的数据值是19990704,因为19990704<0 不成立,所以不会被过滤掉;
六、GroovyTransformer
"transformer": [{"name": "dx_groovy","parameter": {"code": "Column column = record.getColumn(0);def str = column.asString();def sb = new StringBuffer(str);def header = sb.insert(0,'AA');def strHeader = header.toString();record.setColumn(1, new StringColumn(strHeader));return record","extraPackage": ["import groovy.json.JsonSlurper;"]}}]
效果:

解释:
code中的值如下:
Column column = record.getColumn(0); \\获取下标为0的col
def str = column.asString(); \\ 获取col中的值
def sb = new StringBuffer(str); \\转为stringBuffer
def header = sb.insert(0,'AA'); \\在sb的头部插入字符AA
def strHeader = header.toString(); \\sb转为string
record.setColumn(0, new StringColumn(strHeader)); \\ 数据重新写入col
return record" \\返回数据行
dx_groovy
- 参数。
- 第一个参数: groovy code
- 第二个参数(列表或者为空):extraPackage
- 备注:
- dx_groovy只能调用一次。不能多次调用。
- groovy code中支持java.lang, java.util的包,可直接引用的对象有record,以及element下的各种column(BoolColumn.class,BytesColumn.class,DateColumn.class,DoubleColumn.class,LongColumn.class,StringColumn.class)。不支持其他包,如果用户有需要用到其他包,可设置extraPackage,注意extraPackage不支持第三方jar包。
- groovy code中,返回更新过的Record(比如record.setColumn(columnIndex, new StringColumn(newValue));),或者null。返回null表示过滤此行。
- 用户可以直接调用静态的Util方式(GroovyTransformerStaticUtil),目前GroovyTransformerStaticUtil的方法列表 (按需补充);
七、总结
- 从上面可以看着需要对数据做transformer,只需在job.json里设置对应的参数即可;
- 目前datax内置了5种transform,每种都有一个name进行唯一标识,方便用户调用;
- json中的transformer节点里面可以设置多个transformer类;
- 既然提供了抽象类Transformer,那么肯定可以用户自定义transformer类;(本质和hive中的udf类似,要写hive中的udf,可以看本文)
注:
-
对源码进行略微改动,主要修改为 1 阿里代码规约扫描出来的,2 clean code;
-
所有代码都已经上传到github(master分支和dev),可以免费白嫖