文章目录
- 一、Datax概述
- 1.概述
- 2.DataX插件体系
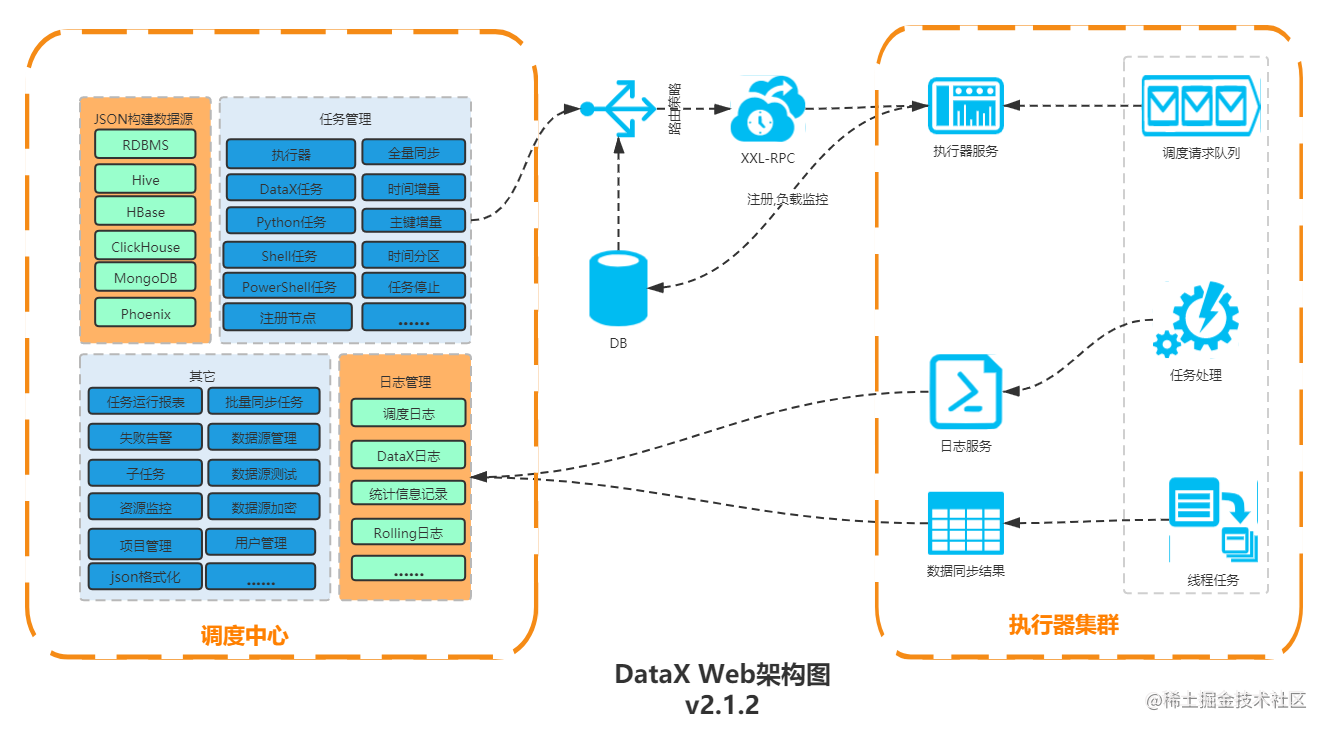
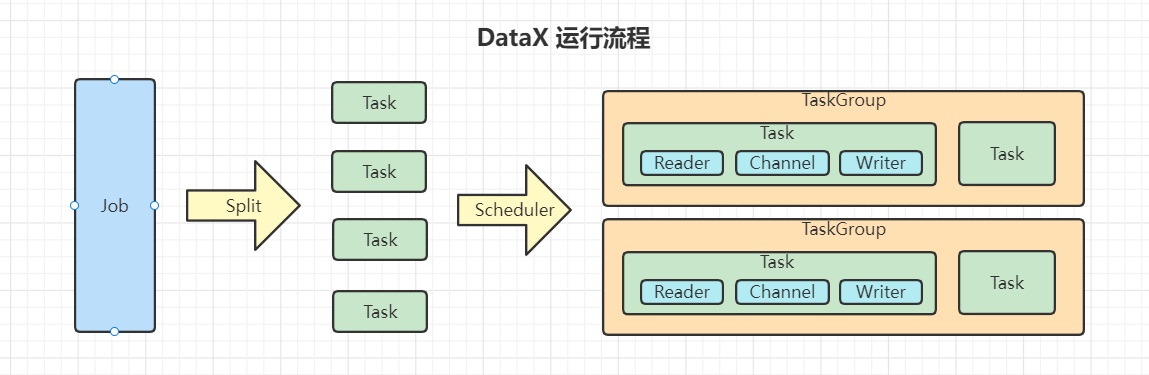
- 3.DataX核心架构
- 二、安装
- 2.1下载并解压
- 2.2运行自检脚本
- 三、基本使用
- 3.1从stream读取数据并打印到控制台
- 1. 查看官方json配置模板
- 2. 根据模板编写json文件
- 3. 运行Job
- 3.2 Mysql导入数据到HDFS
- 1. 查看官方json配置模板
- 2. 根据模板编写json文件
- 3. 运行Job
- 3.3 HDFS数据导出到Mysql
- 1. 将3.2中导入的文件重命名并在数据库创建表
- 2. 查看官方json配置模板
- 3. 根据模板编写json文件
- 4. 运行Job
- 3.4 mysql同步到mysql
- 3.5 mysql同步到hbase
- 3.6 hbase同步到hbase
- 3.7 hbase同步到mysql
- 四、辅助资料
一、Datax概述
1.概述
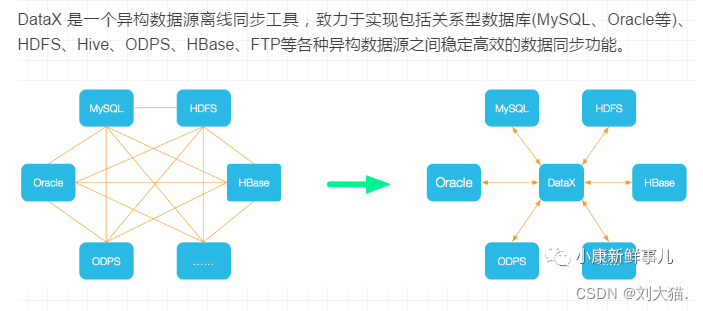
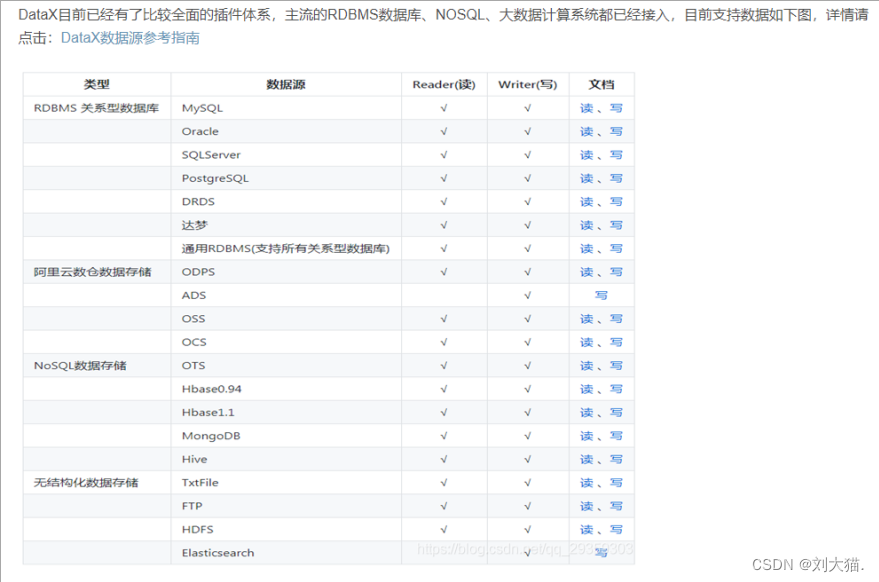
2.DataX插件体系
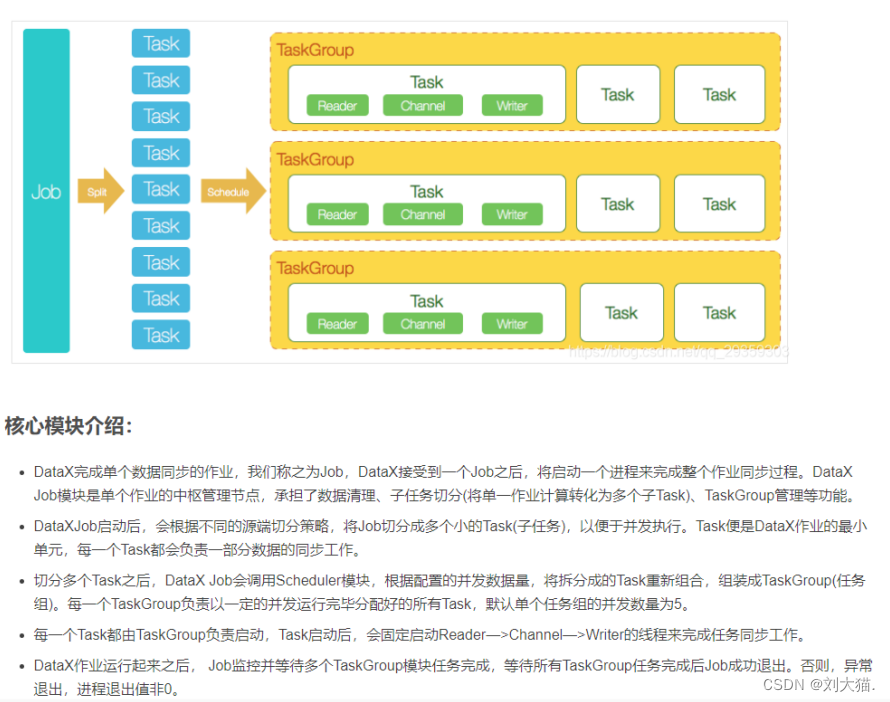
3.DataX核心架构
二、安装
2.1下载并解压
源码地址: https://github.com/alibaba/DataX
这里我下载的是最新版本的 DataX3.0 。下载地址为:
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
# 下载后进行解压
[xiaokang@hadoop ~]$ tar -zxvf datax.tar.gz -C /opt/software/
2.2运行自检脚本
[xiaokang@hadoop ~]$ cd /opt/software/datax/
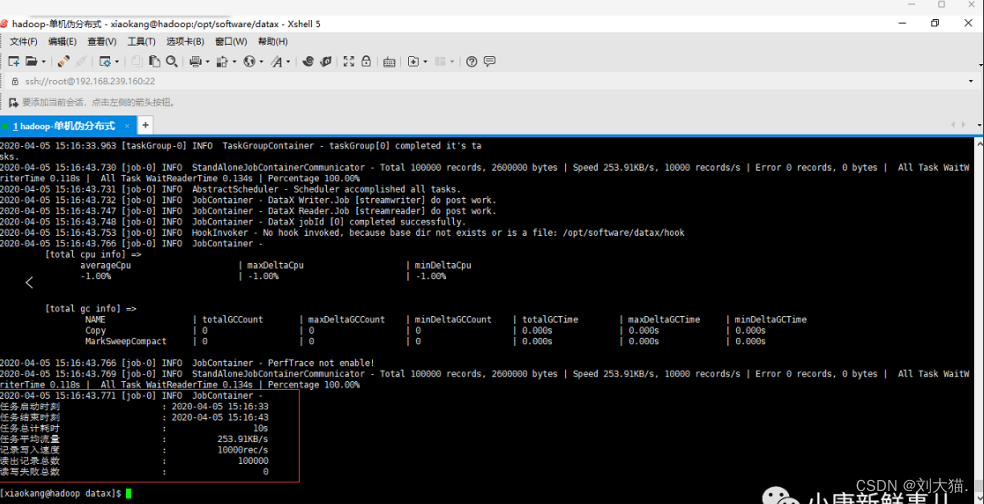
[xiaokang@hadoop datax]$ bin/datax.py job/job.json
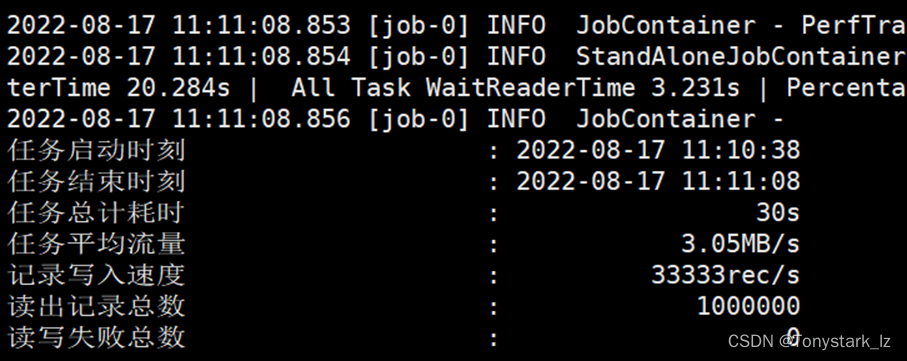
出现以下界面说明DataX安装成功
三、基本使用
3.1从stream读取数据并打印到控制台
1. 查看官方json配置模板
[xiaokang@hadoop ~]$ python /opt/software/datax/bin/datax.py -r streamreader -w streamwriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the streamreader document:https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document:https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "streamreader", "parameter": {"column": [], "sliceRecordCount": ""}}, "writer": {"name": "streamwriter", "parameter": {"encoding": "", "print": true}}}], "setting": {"speed": {"channel": ""}}}
}
2. 根据模板编写json文件
{"job": {"content": [{"reader": {"name": "streamreader", "parameter": {"column": [{"type":"string","value":"xiaokang-微信公众号:小康新鲜事儿"},{"type":"string","value":"你好,世界-DataX"}], "sliceRecordCount": "10"}}, "writer": {"name": "streamwriter", "parameter": {"encoding": "utf-8", "print": true}}}], "setting": {"speed": {"channel": "2"}}}
}
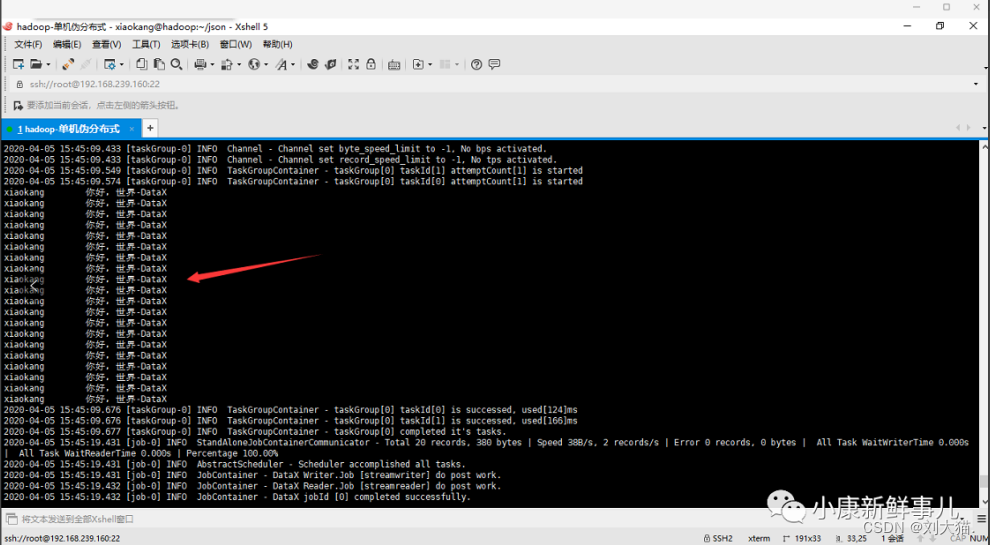
3. 运行Job
[xiaokang@hadoop json]$ /opt/software/datax/bin/datax.py ./stream2stream.json
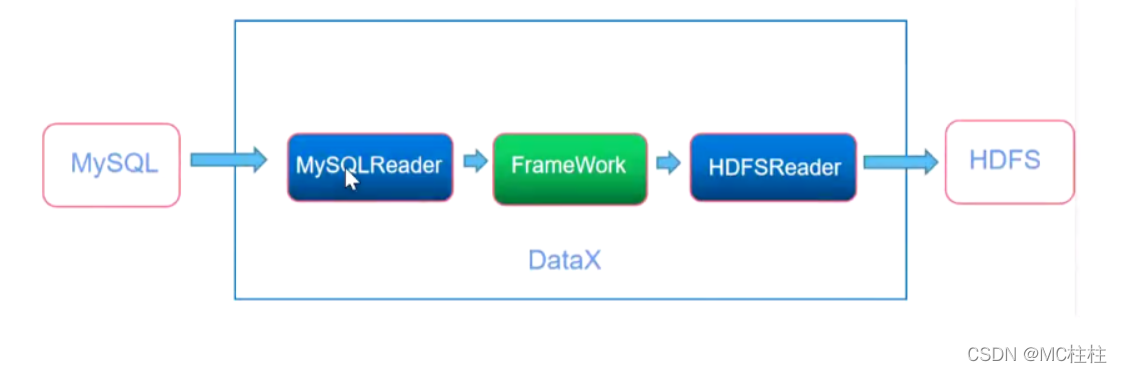
3.2 Mysql导入数据到HDFS
示例:导出 MySQL 数据库中的 help_keyword 表到 HDFS 的 /datax目录下(此目录必须提前创建)。

1. 查看官方json配置模板
[xiaokang@hadoop json]$ python /opt/software/datax/bin/datax.py -r mysqlreader -w hdfswriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the mysqlreader document:https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md Please refer to the hdfswriter document:https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"column": [], "connection": [{"jdbcUrl": [], "table": []}], "password": "", "username": "", "where": ""}}, "writer": {"name": "hdfswriter", "parameter": {"column": [], "compress": "", "defaultFS": "", "fieldDelimiter": "", "fileName": "", "fileType": "", "path": "", "writeMode": ""}}}], "setting": {"speed": {"channel": ""}}}
}
2. 根据模板编写json文件


{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"column": ["help_keyword_id","name"], "connection": [{"jdbcUrl": ["jdbc:mysql://192.168.1.106:3306/mysql"], "table": ["help_keyword"]}], "password": "xiaokang", "username": "root"}}, "writer": {"name": "hdfswriter", "parameter": {"column": [{"name":"help_keyword_id","type":"int"},{"name":"name","type":"string"}], "defaultFS": "hdfs://hadoop:9000", "fieldDelimiter": "|", "fileName": "keyword.txt", "fileType": "text", "path": "/datax", "writeMode": "append"}}}], "setting": {"speed": {"channel": "3"}}}
}
3. 运行Job
[xiaokang@hadoop json]$ /opt/software/datax/bin/datax.py ./mysql2hdfs.json
3.3 HDFS数据导出到Mysql
1. 将3.2中导入的文件重命名并在数据库创建表
[xiaokang@hadoop ~]$ hdfs dfs -mv /datax/keyword.txt__4c0e0d04_e503_437a_a1e3_49db49cbaaed /datax/keyword.txt
表必须预先创建,建表语句如下:
CREATE TABLE help_keyword_from_hdfs_datax LIKE help_keyword;
2. 查看官方json配置模板
[xiaokang@hadoop json]$ python /opt/software/datax/bin/datax.py -r hdfsreader -w mysqlwriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the hdfsreader document:https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md Please refer to the mysqlwriter document:https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "hdfsreader", "parameter": {"column": [], "defaultFS": "", "encoding": "UTF-8", "fieldDelimiter": ",", "fileType": "orc", "path": ""}}, "writer": {"name": "mysqlwriter", "parameter": {"column": [], "connection": [{"jdbcUrl": "", "table": []}], "password": "", "preSql": [], "session": [], "username": "", "writeMode": ""}}}], "setting": {"speed": {"channel": ""}}}
}
3. 根据模板编写json文件
{"job": {"content": [{"reader": {"name": "hdfsreader", "parameter": {"column": ["*"], "defaultFS": "hdfs://hadoop:9000", "encoding": "UTF-8", "fieldDelimiter": "|", "fileType": "text", "path": "/datax/keyword.txt"}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["help_keyword_id","name"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.1.106:3306/mysql", "table": ["help_keyword_from_hdfs_datax"]}], "password": "xiaokang", "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "3"}}}
}
4. 运行Job
[xiaokang@hadoop json]$ /opt/software/datax/bin/datax.py ./hdfs2mysql.json
3.4 mysql同步到mysql
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"password": "gee123456","username": "geespace","connection": [{"jdbcUrl": ["jdbc:mysql://192.168.20.75:9950/geespace_bd_platform_dev"],"querySql": ["SELECT id, name FROM test_test"]}]}},"writer": {"name": "mysqlwriter","parameter": {"column": ["id", "name"],"password": "gee123456","username": "geespace","writeMode": "insert","connection": [{"table": ["test_test_1"],"jdbcUrl": "jdbc:mysql://192.168.20.75:9950/geespace_bd_platform_dev"}]}}}],"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}}}
}
3.5 mysql同步到hbase
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"password": "gee123456","username": "geespace","connection": [{"jdbcUrl": ["jdbc:mysql://192.168.20.75:9950/geespace_bd_platform_dev"],"querySql": ["SELECT id, name FROM test_test"]}]}},"writer": {"name": "hbase11xwriter","parameter": {"mode": "normal","table": "test_test_1","column": [{"name": "f:id","type": "string","index": 0}, {"name": "f:name","type": "string","index": 1}],"encoding": "utf-8","hbaseConfig": {"hbase.zookeeper.quorum": "192.168.20.91:2181","zookeeper.znode.parent": "/hbase"},"rowkeyColumn": [{"name": "f:id","type": "string","index": 0}, {"name": "f:name","type": "string","index": 1}]}}}],"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}}}
}
3.6 hbase同步到hbase
{"job": {"content": [{"reader": {"name": "hbase11xreader","parameter": {"mode": "normal","table": "test_test","column": [{"name": "f:id","type": "string"}, {"name": "f:name","type": "string"}],"encoding": "utf-8","hbaseConfig": {"hbase.zookeeper.quorum": "192.168.20.91:2181","zookeeper.znode.parent": "/hbase"}}},"writer": {"name": "hbase11xwriter","parameter": {"mode": "normal","table": "test_test_1","column": [{"name": "f:id","type": "string","index": 0}, {"name": "f:name","type": "string","index": 1}],"encoding": "utf-8","hbaseConfig": {"hbase.zookeeper.quorum": "192.168.20.91:2181","zookeeper.znode.parent": "/hbase"},"rowkeyColumn": [{"name": "f:id","type": "string","index": 0}, {"name": "f:name","type": "string","index": 1}]}}}],"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}}}
}
3.7 hbase同步到mysql
{"job": {"content": [{"reader": {"name": "hbase11xreader","parameter": {"mode": "normal","table": "test_test_1","column": [{"name": "f:id","type": "string"}, {"name": "f:name","type": "string"}],"encoding": "utf-8","hbaseConfig": {"hbase.zookeeper.quorum": "192.168.20.91:2181","zookeeper.znode.parent": "/hbase"}}},"writer": {"name": "mysqlwriter","parameter": {"column": ["id", "name"],"password": "gee123456","username": "geespace","writeMode": "insert","connection": [{"table": ["test_test"],"jdbcUrl": "jdbc:mysql://192.168.20.75:9950/geespace_bd_platform_dev"}]}}}],"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}}}
}
四、辅助资料
DataX介绍以及优缺点分析:
https://blog.csdn.net/qq_29359303/article/details/100656445?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162434122516780357231881%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162434122516780357231881&biz_id=0&utm_med
datax详细介绍及使用:
https://blog.csdn.net/qq_39188747/article/details/102577017?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162434122516780357231881%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162434122516780357231881&biz_id=0&utm_med