git原理笔记(一)
这个笔记是对于git内部原理的一个理解。网上很多关于git的用法的教程。这里推荐廖雪峰的git教程。
这里主要记录如下的内部原理的理解
1. git如何存储
2. git如何管理版本
一. git如何存储
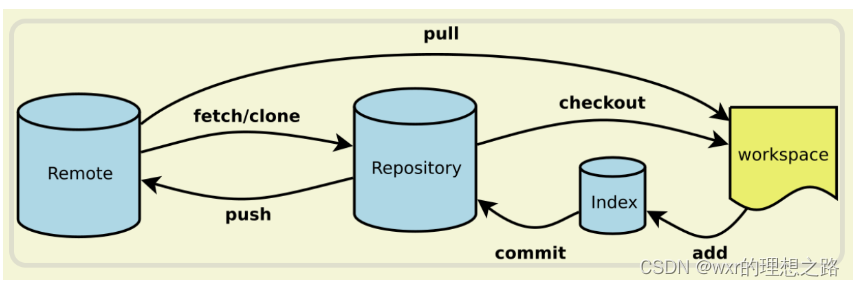
常常在使用git的过程中,一直在思考,git到底是如何存储我们提交的这些代码的。后来通过种种学习,发现,git将我们的所有东西都放在了.git目录下。那么.git目录下有什么东西呢。下面是随便建立的一个git库下面的.git目录

目录简要说明如下:
branches——以前用来指定一个URL去fetch,pull,push的一个快捷方式,不过现在不用了
config——当前项目的配置文件,包括怎么去fetch,push等。后面再引用格式中会提到
description——仅供gitweb程序使用的描述性文件
HEAD——存储HEAD引用指向的位置,后面有提到引用的概念
hooks——这个目录包含的是shell脚本,相应的git命令执行时,这些脚本会被回调。
info——记录当前库的额外信息
objects——真正保存数据的地方
refs——存放引用的地方
1.1 使用底层命令,向git存数据
在平时的使用中,都是通过,git commit将数据存入本地库中。为了查看git的存储原理,这里使用git hash-object命令,将数据直接写入git的库中。向git库中存入,一个wanbiao的内容。如下

-w表示写入,–stdin表示从标准输入中读入数据内容,否则,后面跟上文件路径。文件就是需要存储的内容
前面说过,objects目录用来存放数据,那么,我们去objects目录下看看有什么东西没有。

发现在objects下面多了一个cc目录,并且多了一个文件。将目录名字和文件名字拼接在一起,就是git hash-object输出的内容。
这是因为:向git写入数据的时候,会得到一个sha-1的校验和。然后以这个校验和的前两位为目录名,后38位为文件名,然后再将数据内容写入这个文件中,本例中数据内容就是字符串“wanbiao”。
使用git cat-file 查看如下:

这里有必要提一下,这40个字符怎么来的。
git使用{数据类型+数据长度+\0+数据内容},获得相应额SHA-1的值。
为了说明此情况,这里引用git官网上面的ruby代码来演示。

1.2 git的内部数据类型
在上面中,保存了数据,如果这个是一个文件,文件内容我们可以按上述的方法保存,但是文件的名字怎么保存呢。此时,在git内部中,使用了如下的类型来保存不同的数据。
1. blob
2. tree
3. commit
4. tag
blob类型表示,数据内容
tree类型表示,目录内容
commit类型表示,提交内容
tag类型表示,标签内容
要查看数据类型,可以使用
git cat-file -t如下

接下来,我们将前面的wanbiao内容,放入一个name的文件中。
因此,这里应该使用tree类型,使用git write-tree创建tree对象,因为一个tree对象中可以用很多的类型,比如blob,还有其他的tree,因此,git write-tree之前,需要将放入tree对象中的东西,放在一个暂存区中。使用命令 git update-index 放入暂存区。演示如下:

对于git update-index的用法如下:

git write-tree,将当前暂存区中的内容,保存为一个tree对象,这个tree对象,被存储的方式与blob对象一样,也是讲前两位作为目录,后38位作为文件。因此我们在objects里面可以看一下,如下:

再看看这个tree对象的内容
git cat-file -p如下:

有了上面的tree对象之后,就可以创建一个commit对象了,这个对象用于保存当前提交的一些信息,使用git commit-tree,来创建tree对象如下:

查看内容使用,git cat-file -p 如下:

可以看到提交者的详细信息。使用如下命令来查看提交记录:

没有使用git add,git commit,就已经成功的创建了一个提交。这里为什么没有直接使用git log,是因为当前的引用,还没有配置好。这个留到下一节来记录,即,git如何管理版本.下图我们创建的对象的一个关系图:

我们再创建一个提交,如下的操作

1.3 git如何管理各个版本之间的差异
在上面的所有数据,每次提交都是一个新的内容。如果我们修改了一个文件,那么git是如何管理这个文件的呢?我能想到的方法是:1.每次都保存这个新修改的文件。2.保存的仅仅是两个文件的差分。
第一种情况就会增加非常大的存储。比如我又一个10M的文件。但是我只是在某一次提交中,改变了一下这个文件的最后一行。如果每次都保存新修改的文件。那么10M的文件肯定有两个,这非常消耗存储。
我来测试一下git到底使用的是那种模式来管理的。这里准备一个大文件。将其加入git中,然后修改一小部分,在次提交,看看git内部数据存储的变化
首先增加一个大文件

我们现在稍微更改一下。在提交看看git的大小

从size一行可以看出,虽然我们只改变了TextView.java的最后一行,但是git每次都保存了完整的文件内容。
因此,可以推断git就是把每个文件都保存了一份。git肯定会占用很大的存储空,事实也是如此,当你从其他的保存差分的版本控制系统,迁移到git的时候,git会占用更多的空间。
那么,git能不能优化一下呢?答案是肯定得。通过运行git gc,进行优化。这里尝试一下,如下结果

size的大小变成了108减少了几乎一半的大小。那么git到底做了什么操作,才减少了操作。
在最开始提过,git将数据放在objects目录下,现在看看objects下面是什么样子

发现有4个对象,这四个对象,分别是2个commit对象,一个tree对象,
一个blob对象。并且info和pack目录下面多了内容。通过git cat-file -p 命令查看blob对象,就会发现,这个对象保存的是当前最新的文件的内容。那么以前的内容上哪里去了?
答案就是:在pack里面。pack下面有两个文件一个.idx文件,一个.pack文件。.pack文件保存的是各个对象打包之后的数据。因为所有的对象都保存在一个文件,为了区分他们,有了idx文件,这个文件保存有偏移量,类型,以及大小。使用git verify-pack -v命令进行查看。如下:

可以看到,里面有两个对象,一个blob对象,一个tree对象。
注意:从git官网的资料来看,这个blob对象的大小应该为差分的大小,即pack里面存储的内容应该是TextView.java两次修改产生的差分。但是笔者在这里TextView就不是保存的差分,也试过保存二进制文件,显示的也不是差分。此处视乎更官网有些差别
至于为什么会出现这种差异,有待后面考证。
那么这里总结一下(官网说法):git 每次都对修改的整个文件进行全部保存,当触发了git gc,那么,会对非悬空对象进行打包,打包文件中,保存的是各个版本之间的差异,因此可以节省内存。
实际情况:git每次对修改的整个文件进行全部保存,当触发了git gc之后,对非悬空对象进行打包,打包文件中,保存的还是整个文件的内容,并没有减少。(有待下一步研究)