目录
1、前言
1.1、项目背景
1.2、场景执行步骤
2、司机长链接
2.1、司机出车环境
2.2、主要用到的包
2.3、脚本解析
3、全流程压测脚本
3.1、司乘数据准备
3.2、全链路压测脚本
4、资源监控与收集
4.1、聚合报告
4.2、自研脚本
1、前言
1.1、项目背景
在车辆与用户数的日益增长情况下,避免日后系统数据增长可能带来的系统瓶颈,确保多用户访问不会出现问题,特针对现有重要代表性接口以及全流程进行压力测试。
1.2、场景执行步骤
针对全流程压测:
1、先开启司机长链接脚本,取保司机在线。
2、查看redis,查询司机接口,确认多少司机在线(达到满足压测条件)。
3、执行接口全流程压测脚本。
4、服务器性能监控与数据收集(阿里云、Jmeter聚合报告、自研脚本)。
2、司机长链接
模拟司机出车,需要开发辅助脚本。由于之前有Java版,但供组内使用时发现不太方便,所以重新开发一版(Python版本)。
2.1、司机出车环境
模拟司机出车环境:测试环境、测试环境2、预发环境
模拟司机出车.py:模拟一个司机出车
模拟司机出车(多线程).py:模拟多个司机出车
模拟司机出车(多线程)-压测.py:模拟多个司机出车,主要用于压测任务,在指定坐标点范围内随机生成坐标出车

2.2、主要用到的包
脚本开发过程中主要用到的包:socket、threading、requests、MySQLdb、redis、pandas
2.3、脚本解析
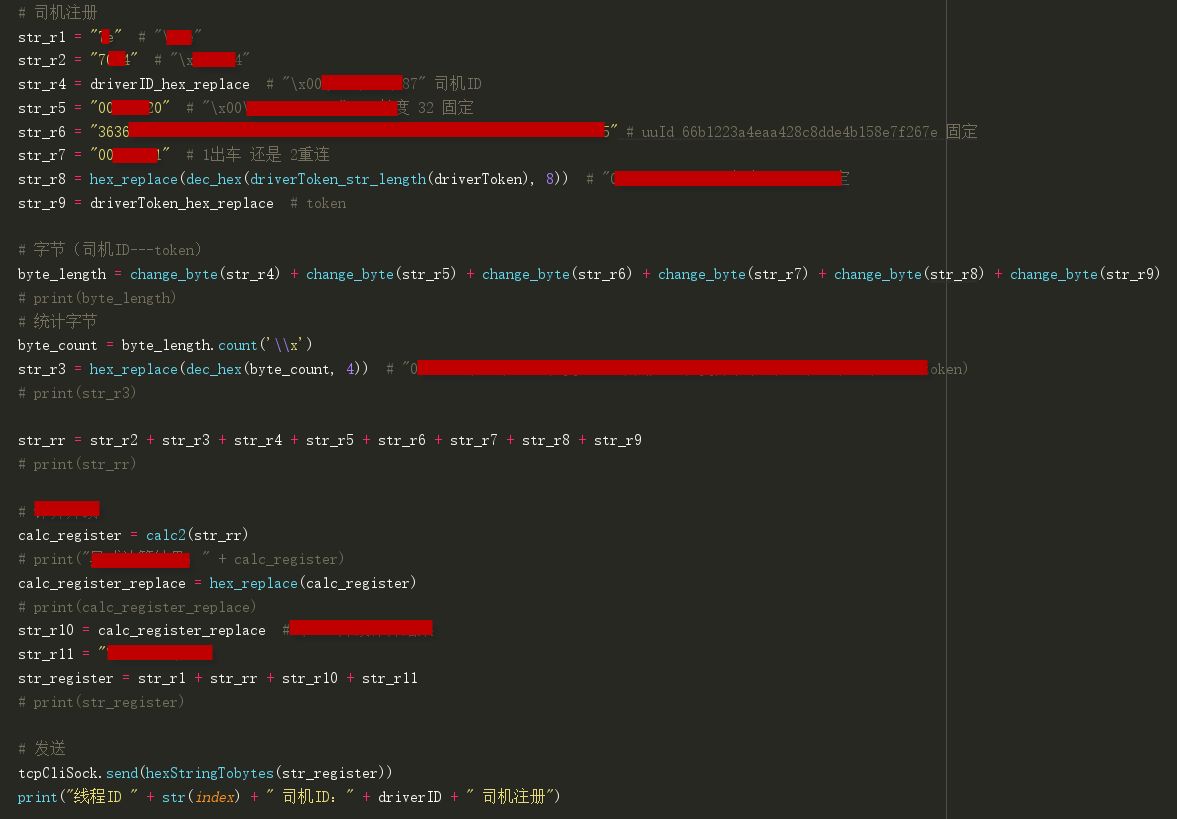
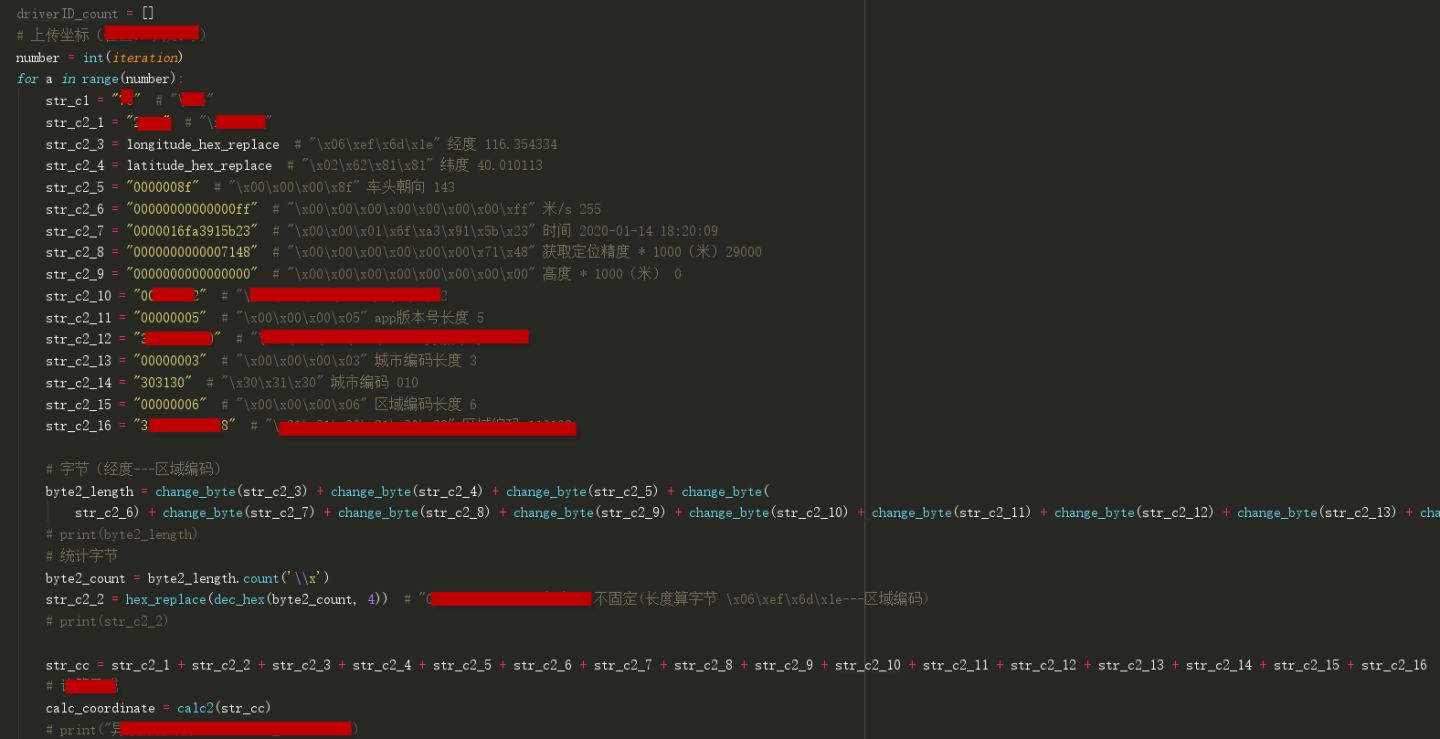
1、模拟司机出车的主要动作就是:司机注册(司机在线)和上传坐标(司机位置)
司机注册(部分代码):
上传坐标(部分代码):
2、调用函数(部分):进制转换、随机生成坐标
进制转换(部分代码):
# 字符串转16进制
def str_hex(mystr):str1_16 = ":".join("{:02x}".format(ord(c)) for c in mystr)# print(str1_16)str2_16 = str1_16.replace(':', '\\x')str3_16 = "\\x"+str2_16# print(str3_16)return str(str3_16)# 10进制转16进制
def dec_hex(str_10, number):str_16 = str(hex(int(str_10)))# print(str_16)str2_16 = str_16.replace("0x", '')# number为16进制长度str3_16 = str2_16.rjust(number,'0')# print(str3_16)str4_16_string = ""for i_str3 in range(len(str3_16)//2):# print(i_str3)result = "\\x" + str3_16[i_str3*2:i_str3*2+2]# print(result)str4_16_string += result# print(str4_16_string)return str(str4_16_string)'''
十六进制字符串转bytes
eg:
'01 23 45 67 89 AB CD EF 01 23 45 67 89 AB CD EF'
b'\x01#Eg\x89\xab\xcd\xef\x01#Eg\x89\xab\xcd\xef'
'''
def hexStringTobytes(strTobytes):toBytes = strTobytes.replace(" ", "")# print(toBytes)# print(bytes.fromhex(toBytes))return bytes.fromhex(toBytes)随机生成坐标(代码):
# 随机生成范围内经纬度坐标(base_log:经度基准点,base_lat:维度基准点,radius:距离基准点的半径)
def randomLogLat(base_log = None, base_lat = None, radius = None):radius_in_degrees = radius / 111300u = float(random.uniform(0.0, 1.0))v = float(random.uniform(0.0, 1.0))w = radius_in_degrees * math.sqrt(u)t = 2 * math.pi * vx = w * math.cos(t)y = w * math.sin(t)longitude = y + base_loglatitude = x + base_lat# 这里是想保留6位小数loga = '%.6f' % longitudelata = '%.6f' % latitudereturn loga, lata
3、程序运行主体代码
模拟司机出车.py
# 程序运行主体
var = 1
while var == 1:# 选择环境env = input("请选择环境:1(测试环境)、2(测试环境2)、3(预发环境):")if env == "1" or env == "2" or env == "3":if env == "1":environment = "test"elif env == "2":environment = "test2"elif env == "3":environment = "uat"phone = input("请输入司机端手机号:")# 手机号格式校验:ret = re.match(r"^1[235678]\d{9}$", phone)if ret:coordinate = input("请输入经纬度坐标 例如 116.321895, 39.966849:")strlist = coordinate.split(',')longitude = strlist[0].strip()latitude = strlist[1].strip()# print(longitude)# print(latitude)# # 保留6位小数# print(format(float(longitude), '.6f'))# print(format(float(latitude), '.6f'))iteration = input("请输入司机上线迭代次数(5秒一次迭代)需大于0:")# 判断输入的是否为整数且不为0if (iteration.isdigit() == True) and (int(iteration) != 0):# 司机长链接runLonglink(environment, phone, format(float(longitude), '.6f'), format(float(latitude), '.6f'), iteration)else:print("输入迭代次数格式错误\n")else:print("手机号格式错误\n")else:print("选择环境不对\n")模拟司机出车(多线程).py
# 程序运行主体
if __name__=="__main__":threads = []t1 = threading.Thread(target=runLonglink, args=("test", 137xxxxxxxx, 116.321423,39.966684, 50)) threads.append(t1)t2 = threading.Thread(target=runLonglink, args=("test", 137xxxxxxxx, 116.321315,39.967362, 300)) threads.append(t2)t3 = threading.Thread(target=runLonglink, args=("test", 137xxxxxxxx, 116.321576,39.966901, 300)) threads.append(t3)t4 = threading.Thread(target=runLonglink, args=("test", 137xxxxxxxx, 116.354229,40.008462, 300)) threads.append(t4)for t in threads:t.start()for t in threads:t.join()print("执行完毕")模拟司机出车(多线程)-压测.py
出车的司机数据存放到了Dtoken.csv文件里。
# 程序运行主体
if __name__=="__main__":threads = []# 获取CSV文件token_data = pandas.read_csv('Dtoken.csv', sep=',', header=None)print("出车司机个数 " + str(token_data.count().values[0]))# 逐行读取for index in token_data.index:# print(index)token_data_driverID = str(token_data.loc[index].values[0])token_data_driverToken = str(token_data.loc[index].values[1])# print(token_data_driverID)# print(token_data_driverToken)# 随机生成范围内经纬度坐标random_longitude, random_latitude = randomLogLat(base_log=116.321407, base_lat=39.966886, radius=1000)print(random_longitude + "," + random_latitude)t_Longlink = threading.Thread(target=runLonglink, args=(index + 1, "test", token_data_driverID, token_data_driverToken, random_longitude, random_latitude, 10))threads.append(t_Longlink)for t in threads:t.start()for t in threads:t.join()print("执行完毕")Dtoken.csv文件(存放司机ID、司机Token)。

4、执行脚本
例如:模拟司机出车.py

3、全流程压测脚本
3.1、司乘数据准备
ID(乘客/司机)、Token,是每个接口都会用到的,所以压测前先把这些基础数据准备完成。
1、获取乘客ID和Token
根据乘客手机号(参数化),发送验证码(可设置通用验证码,跳过此步),进行登录,并对接口返回进行提取乘客ID和Token,保存到指定文件里。
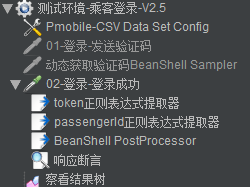
2、获取司机ID和Token
根据司机手机号(参数化),发送验证码(可设置通用验证码,跳过此步),进行登录,并对接口返回进行提取司机ID和Token,保存到指定文件里。

3、动态获取验证码(代码):
import redis.clients.jedis.Jedis;
import org.apache.commons.lang3.StringUtils;String host = "XXX"; //服务器地址
int port = 6379; //端口号
String password = "XXX"; //redis密码
int index = 1; //redis db
String key = "XXX_135XXXXXXXX";Jedis jedis = new Jedis(host, port);
if(StringUtils.isNotBlank(password)){jedis.auth(password);}
jedis.select(index); //选择redis dbSet keys = jedis.keys(key);
log.info("keys: "+keys);code = jedis.get(keys.iterator().next()); //获取key的值
vars.put("code",code.replace("\"", "")); //将key的值保存为变量4、写文件(代码):
FileWriter fstream = new FileWriter("D:\\xxx.txt",true);
BufferedWriter out= new BufferedWriter(fstream);
BufferedWriter bw = null;
out.write(vars.get("id")+","+vars.get("token")+"\r\n");
out.close();
fstream();3.2、全链路压测脚本
脚本主要分为两大块:服务中订单和创建订单。

1、服务中订单(对司机之前未完成的订单和乘客未支付的订单的处理)

例如:已经派单,循环判断接单状态,失败(派单失败)或者成功(司机接到派单)。

如派单成功,接着按流程走(去接乘客、到达乘客上车点、开始计费、到达目的地、发起收款、乘客支付、乘客评价等)。

2、创建订单:
分为3个分支(获取预估价格失败、叫车成功、叫车失败)

例如:叫车成功,循环判断接单状态,失败(派单失败)或者成功(司机接到派单)。
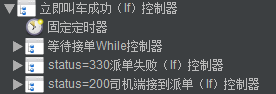
如司机接单成功,接着流程走(去接乘客、到达乘客上车点、开始计费、到达目的地、发起收款、乘客支付、乘客评价等)。

4、资源监控与收集
Jmeter进行全流程压测时,可以使用阿里云、Jmeter聚合报告、自研脚本等对服务器性能监控与数据收集。
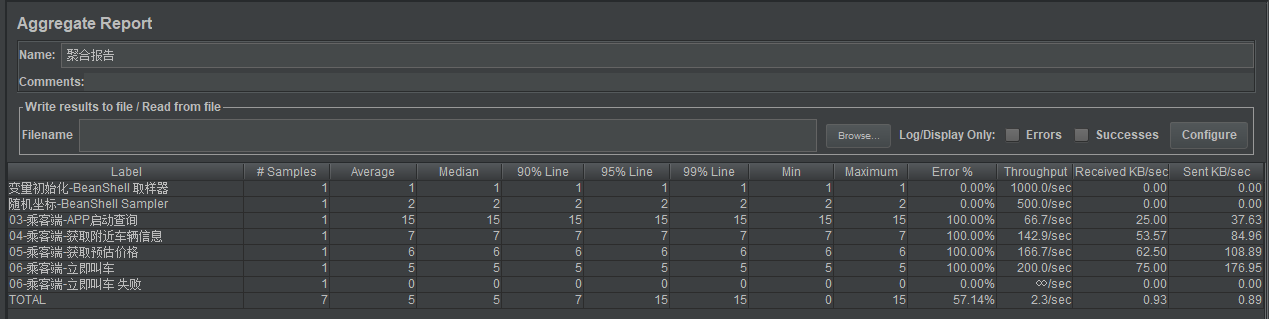
4.1、聚合报告
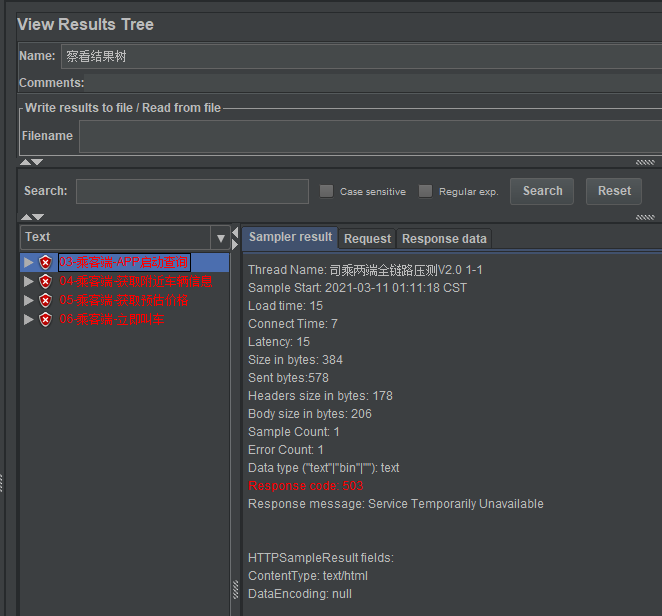
在Jmeter脚本里添加:察看结果树、聚合报告。

聚合报告
察看结果树
Jmeter常用术语:
(1)线程数:并发用户数。
(2)请求数Samples:发出了多少个请求,例:模拟10个用户,每个用户迭代10次,就是100次。
(3)平均响应时间Average:单个请求平均响应时间(毫秒)。
(4)中位数Median: 50% 用户的响应时间(毫秒)。
(5)90% Line:90% 用户的响应时间。
(6)Min:最小响应时间(毫秒)。
(7)Max:最大响应时间(毫秒)。
(8)错误率Error%:出现错误的请求的数量/请求的总数。
(9)吞吐量Throughput:表示每秒完成的请求数(Request per Second)。
4.2、自研脚本
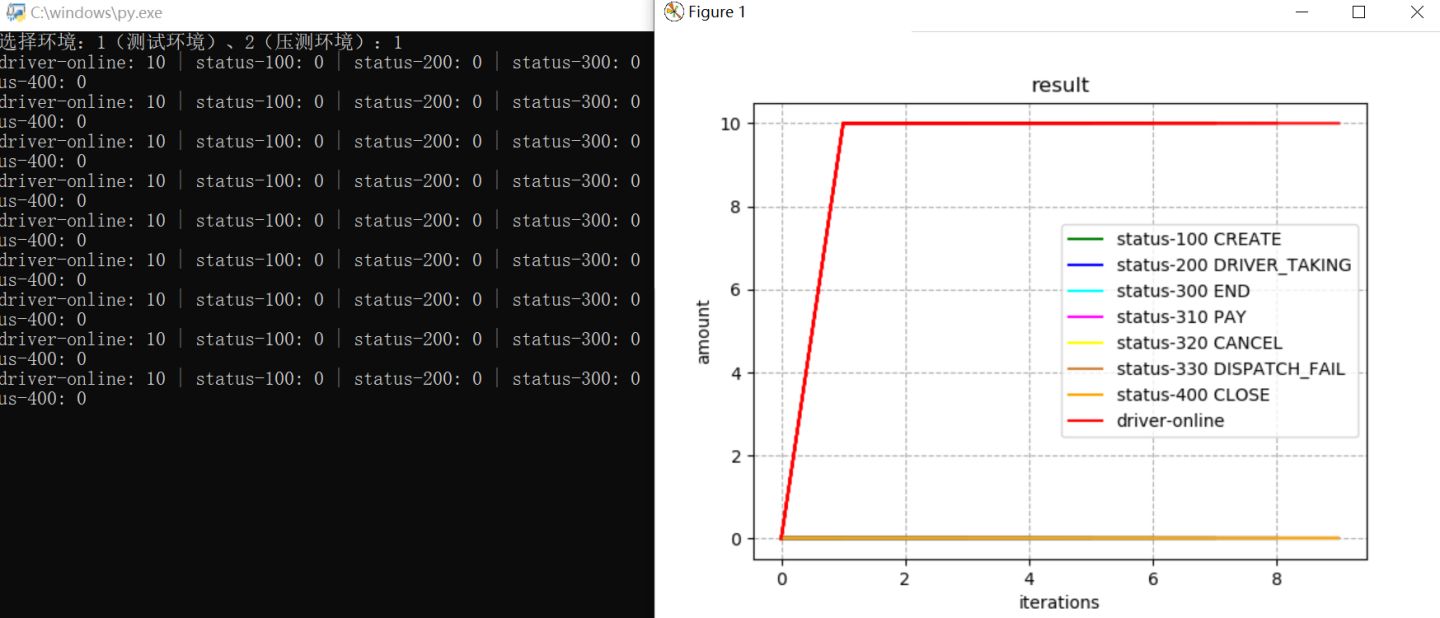
在整个司乘订单状态流转过程中,想监控一下这些状态,开发了实时查询司机在线、发单、接单状态脚本。
脚本生成图形使用matplotlib包。
脚本大概流程:从redis获取司机在线数,并且通过查询数据库中订单的状态,绘制订单状态图(实时)。
程序运行主体代码:
# 选择环境
environment = input("选择环境:1(测试环境)、2(压测环境):")
if environment == "1" or environment == "2":plt.ion()plt.figure(1)number = [0,]driver_online = [0,]status_100 = [0,]status_200 = [0,]status_300 = [0,]status_310 = [0,]status_320 = [0,]status_330 = [0,]status_400 = [0,]# 当前时间t = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())for i in range(1000000):number.append(i + 1)# print(number)online = int(get_driver_online(environment))s100 = int(get_status_100_count(environment, t))s200 = int(get_status_200_count(environment, t))s300 = int(get_status_300_count(environment, t))s310 = int(get_status_310_count(environment, t))s320 = int(get_status_320_count(environment, t))s330 = int(get_status_330_count(environment, t))s400 = int(get_status_400_count(environment, t))driver_online.append(online)# print(driver_online)status_100.append(s100)# print(status_100)status_200.append(s200)# print(status_200)status_300.append(s300)# print(status_300)status_310.append(s310)# print(status_310)status_320.append(s320)# print(status_320)status_330.append(s330)# print(status_330)status_400.append(s400)# print(status_400)plt.title('result')plt.grid(linestyle="--") # 设置背景网格线为虚线# color:b:blue、g:green、r:red、c:cyan、m:magenta、y:yellow、k:black、w:whiteplt.plot(number, status_100, color='green', label='status-100 CREATE')plt.plot(number, status_200, color='blue', label='status-200 DRIVER_TAKING')plt.plot(number, status_300, color='cyan', label='status-300 END')plt.plot(number, status_310, color='magenta', label='status-310 PAY')plt.plot(number, status_320, color='yellow', label='status-320 CANCEL')plt.plot(number, status_330, color='peru', label='status-330 DISPATCH_FAIL')plt.plot(number, status_400, color='orange', label='status-400 CLOSE')plt.plot(number, driver_online, color='red', label='driver-online')handles, labels = plt.gca().get_legend_handles_labels()by_label = OrderedDict(zip(labels, handles))plt.legend(by_label.values(), by_label.keys())plt.xlabel('iterations')plt.ylabel('amount')# plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果要显示中文字体,则在此处设为:SimHeiplt.show()plt.pause(0.3)print("driver-online: " + str(online) + " | status-100: " + str(s100) + " | status-200: " + str(s200) + " | status-300: " + str(s300) + " | status-310: " + str(s310) + " | status-320: " + str(s320) + " | status-330: " + str(s330) + " | status-400: " + str(s400))
else:print("选择环境不对")如图所示:运行时的订单流转状态图(10个司机出车,还没有接单)。










![[JAVA数据结构]堆](https://img-blog.csdnimg.cn/d397a5a0e2444038bf048690b33f674c.png)