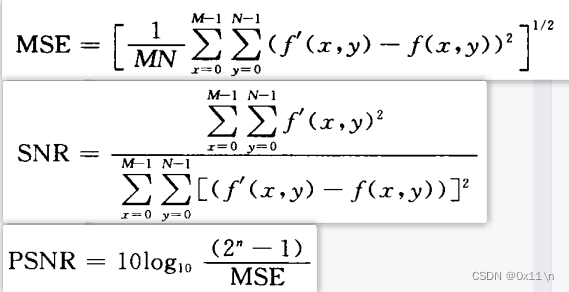视频编解码用到的一些算法:
正反傅里叶变换、fft算法
dct变换、快速dct变换
如何自己实现一个视频编解码器:
(1)取一帧作为I帧,类似jpeg压缩编码,也就是 rgb转yuv,然后dct去除高频信息。因为这种压缩会造成边界block通常使用插值让边界模糊。
(2)运动预测来计算P帧,新的一帧同样做yuv、dct之后,划分为n个宏快(16*16),与上一个参考值的n个宏快(16*16)进行n*n的双重循环计算相似度。比如当前P宏快1和上一参考帧宏快10最相似,那么两个宏快的坐标可以求出矢量变换方程。当然大部分宏块是不会变换的。P1的内容是n个宏块坐标。用这个坐标在上一个参考帧内找到宏块数据。
(3)继续运动预测计算P帧,以前一个参考帧(I帧或P帧)为基础继续宏块变换计算。当然n*n的对比效率低下,通常是以当前点朝四周扩散并且一定范围内选点进行对比。
(4)连续运动预测计算多个P帧,最后结果是,I编码的是A帧,P1编码的是B帧(记录B帧相比A帧有变换的宏快的坐标),P2编码的是C帧(P2记录C相比B有变化的宏快的坐标)。
(5)P帧目前是坐标数据,用P帧结合前一个参考帧进行预测得到一个预测的图片a',因为同时序的真实图片a也是知道的,a'-a 得到预测误差 e,P帧最终保存的就是这个 e (也就是残差)。通过 e 以及前一个参考帧可以完美还原。
(6)双向运动预测计算B帧,B帧跟P帧计算一样,B帧就是根据P1、P3计算P2。
(7)完整的简版视频编码器,I帧和P帧编码已经够了,市面上任然有很多面向低延迟的商用编码器是直接干掉B帧的,因为做实时传输时收到B帧没法播放,之后再往后好几帧收到下一个I或者P帧时,先前收到的B帧才能被解码出来,造成不少的延迟。
(8)组装GOP,一个I多个B、P就组成了一个完整的GOP,然后将一组GOP记录分辨率、时序、帧率等记录下来进行封装,例如mp4格式就ok了。

视频编码住组织整体框架:
不同的视频编码规范有不同的组织框架,但通常可以分为视频序列层、GOP图像组层、图像层、宏快组层、宏快层、YUV层

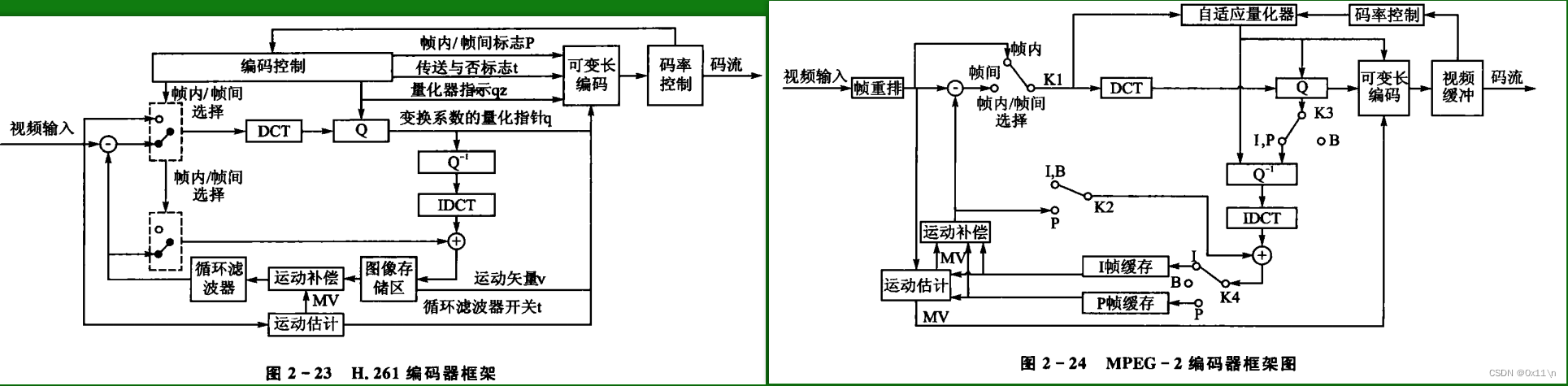
不同时期视频编码器结构:
最早的基础编码器是h261,使用16*16的宏快(包含4个8*8的Y亮度块和2个8*8的UV色度块),以宏块为单位进行编码,帧内编码直接DCT量化然后熵编码(没有帧内预测)。帧间编码做运动估计和运动补偿,预测对原始块做残差后进行DCT量化再熵编码。帧间仅前向预测。后续的编码器结构都在次基础上进行优化升级。
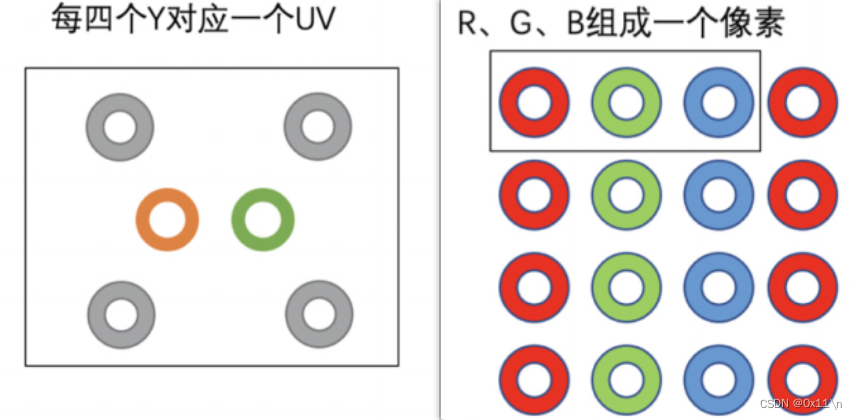
为什么视频编码要使用YUV而不是RGB?
之所以采用YUV,是因为它的亮度信号Y和色度信号U、V是分离的。如果只有Y信号分量而没有U、V分量,那么这样表示的图像就是黑白灰度图像。YUV最大的优点在于只需要占用极少的频宽(RGB要求三个独立的视频信号同时传输)。其中“Y”表示明亮度(Luminance或Luma),也称灰阶值;“U”和“V”表示的则是色度(Chrominance或Chroma),它们的作用是描述影像的色彩及饱和度,用于指定像素的颜色。因此如果只有Y数据,那么表示的图像就是黑白的。在编码时使用YUV格式能极大去除冗余信息,因为人眼对亮点信息的敏感度远高于色度敏感度,如果压缩UV数据,人眼对其感知较弱,所以压缩算法的第一步,往往先把RGB数据转换成YUV数据,对Y压缩一点,对UV多压缩一点,以平衡图像效果和压缩率。对亮度的变化敏感,对色度的变化相对不敏感。
RGB->YUV有损压缩,JPEG就是采用这个压缩方式。
什么是宏块划分:
每一帧图像,划分成一个个块来进行编码的,这一个个块在 H264 中叫做宏块,宏块大小一般是16x16(H264、VP8),32x32(H265、VP9),64x64(H265、VP9、AV1),128x128(AV1)这几种。
什么是空间冗余,如果去掉空间冗余?
一个图像一个帧内,每16*16作为一个字块,相邻的字块之间有较强的相关性和相似性。另外同一个 16*16 的小块内基本上每个像素点的颜色是一样的可以减少编码数据量。另外相邻的块之间是有联系的,也可以通过预测以及插值的方式来减少空间冗余,也就是在一帧内宏块A、B、C相似,那么只需要编码A同时记录BC坐标即可。
什么是时间冗余,如何去掉时间冗余?
在连续的多个帧内,以fps=25为例,相邻两帧之间时间上为40毫秒,两个图像的变换很小,相似性很高。通过帧间预测的方法来去掉冗余的数据,例如前面a帧减去后面bcdef五帧得到残差,那么只需要保留a帧以及bcdef帧的残差进行编码就可以了,而且相邻帧变化不大残差去掉了相同像素点的冗余信息。又由于残差记录的是相邻帧的变化,那么连续的矢量变化是可以预测的,也就是说在残差的基础上只需要保留第一个和最后一个帧的残差,中间的残差可以通过运动预测计算出来。
什么是视觉冗余,如何去除视觉冗余?
人眼睛对于细节不敏感,对轮廓更加敏感,一个图像在去掉高频信息前后感官差别不大。通常在帧内预测或者帧间预测去除冗余信息之后得到一个像素点的残差(大部分是0小部分不是0),然后通过 dct 将高频信息和低频信息划分后,将高频信息也编码为0,这一步就能去除视觉冗余。
什么是编码冗余,如何去除编码冗余?
形如常见的哈夫曼编码,出现概率越大就用出现次数来代替的一种编码形式。在去除了时间、空间、视觉冗余之后得到的是一连串的量化后的数字,编码冗余进行最后一步的压缩。也称为信息熵冗余。
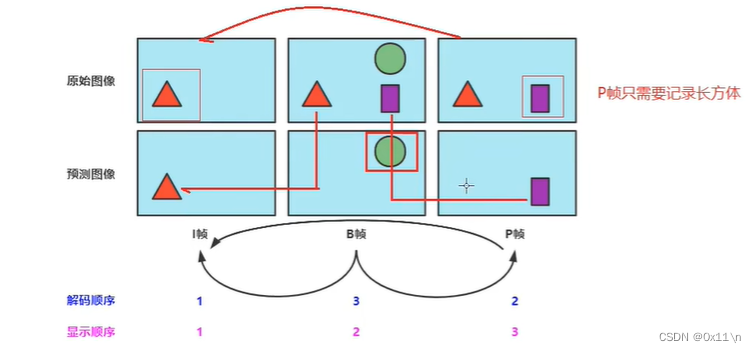
什么是IBP帧?
I帧:帧内编码帧 ,I帧表示关键帧,你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)
P帧:前向预测编码帧。P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。
B帧:双向预测内插编码帧。B帧是双向差别帧,也就是B帧记录的是本帧与前后帧的差别,换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累。
一般来说,I帧的压缩率是7(跟JPG差不多),P帧是20,B帧可以达到50。可见使用B帧能节省大量空间,节省出来的空间可以用来保存多一些I帧,这样在相同码率下,可以提供更好的画质。
I 帧编码的基本流程是什么?
(1) 进行帧内预测,决定所采用的帧内预测模式。
(2) 像素值减去预测值,得到残差。
(3) 对残差进行变换和量化。
(4) 变长编码和算术编码。
(5) 重构图像并滤波,得到的图像作为其它帧的参考帧。
P 帧和 B 帧编码的基本流程是什么?
(1) 进行运动估计,计算采用帧间编码模式的率失真函数(节)值。P帧只参考前面的帧,B 帧可参考后面的帧。
(2) 进行帧内预测,选取率失真函数值最小的帧内模式与帧间模式比较,确定采用哪种编码模式。
(3) 计算实际值和预测值的差值。
(4) 对残差进行变换和量化。
(5) 熵编码,如果是帧间编码模式,编码运动矢量
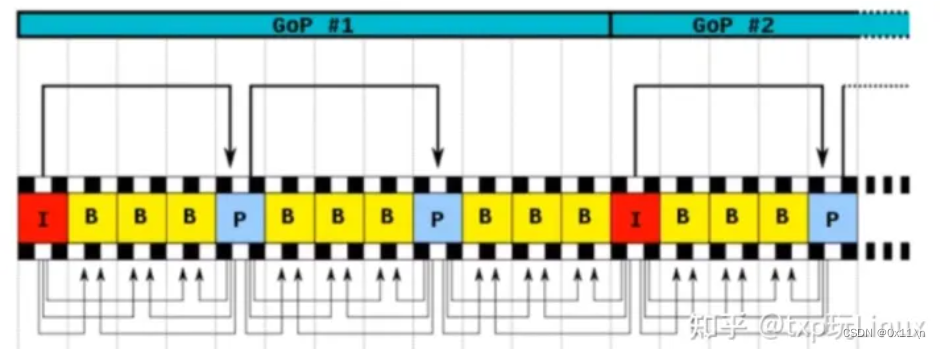
IBP和GOP分组的联系是什么?
所谓GOP,意思是画面组,MPEG格中的帧序列,分为I、P、B三种,如排成IBBPBBPBBPBBPBBP...样式,这种连续的帧图片组合即为GOP(画面群,GROUP OF PICTURE),是MPEG将来存取的最本基本的单位,它的排列顺序将会一直重复到影像结束。一个GOP就是一组连续的IPB画面。GOP设置在直播领域设置为一到两秒。一个GOP的的编解码必须等到一个I帧才能开始解码,同时B帧也会带来编码延迟。
P帧如何根据残差进行图像还原呢?
首先残差就是真实值和预测值的差值。所以计算残差首先需要进行预测。预测就需要根据原始坐标以及终点坐标计算运动矢量。然后根据原始点和运动矢量计算终点的预测值,得到一个预测图像。预测图像减去原始图像得到一个残差。只有残差是不能还原P帧所在帧的图像的,需要先将运动矢量根据参考帧图像得到P帧所在的预测图像,预测图像再加上残差才能得到真实的图像。也就是说P帧保存的是运动矢量、残差两个部分的信息,这两部分进行编码相比原图像编码大大减少了数据量。另外预测得越准确那么残差 越小,残差编码结果就越小。

为什么运动矢量需要计算残差来还原,而不是直接用预测图像来代表原始图像进行显示?
这是因为运动矢量计算出来的预测图像,和真实的图像还是有一定的差别的,宏块的除了运动还有一定比例的旋转、缩放等非平移变换。计算残差一方面可以完美还原,另外一方面数据量也不大。
帧间预测流程:
帧间预测是宏块时间上的移动,有明确的物理意义,可以预测移动来计算残差并且通过残差进行还原。而预测就是运动估计,假设参考帧为P(编码块为B),当前帧为Pr(编码快为Br),B经过运动后到达Br。寻找的过程就是宏快扫描然后求残差,如果两块的残差最小那么表明这两块最有可能是移动变换的前后两块。另外运动估计模型分两种,参数模型(估计参数来得到移动方程)和非参数模型()。
参数模型和非参数模型,以及运动估计得实际应用:
一个运动的物体移动后在二维平面的投影可以通过运动方程来计算,参数模型的运动估计就是估计这个运动方程的参数。而实际应用一般是非参数模型,例如光流方程法、贝叶斯法、像素递归法、块匹配等。而视频编码最使用的运动估计是基于空间域搜索的块匹配法。也就是假设视频划分为m个n*n的宏块,假设块之间是平移变换。实际视频内像素块在划分n*n的像素点内基本是平移变换,就算有一些倾斜和缩放,在实际运用中还会根据估计值和残差一起来还原图像。
运动估计的前向、后向、双向预测的实际应用
前向预测:如果把当前帧所在时序以前的帧作为参考帧进行宏块运动估计。
后向预测:如果把当前帧所在时序以后的帧作为参考帧进行宏块运动估计。
双向预测:同时把前面、后面的帧作为参考帧。并且在两次宏块运动估计之后按照不同的权值求和得到运动矢量。
实际应用中都是前向预测,因为后向预测和双向预测会带来延迟。因为必须等到参考值传过来才能进行工作。
运动估计宏块大小选择,h264的自适应宏块划分:
大部分编码算法以16*16、8*8为宏块大小,因为如果太大比如使用完整一帧计算残差会很大不利于压缩,如果划分太小每个宏块都有运动矢量和残差需要传输光运动矢量就要占用很大的码流也不利于压缩。实际运用是在减少残差、减小运动矢量之间的一个平衡。通常还有自适应的方法,如果画面移动较为平滑自动选择大的宏块、如果画面纹理复杂则选择小的宏块、运动剧烈选择小块、运动少选择大块。h264采用了自适应分块,即先采用大块扫描确定移动后目标大概范围,然后再用小块再此范围内二次搜索找到精确的位置。例如下图先确定一个16*16的大致范围,然后再进行8*8的匹配:

运动估计计算相似度的方法:
SAD:绝对误差和(实际应用最多)
SATD:先Hadamard变换,然后再绝对值求和。
SSD:差值平方和
MAD:平均绝对差值
MSD:平均平方误差
宏块搜索算法,快速搜索:
x264快搜有三种算法,me-dia菱形搜索、me_hex六边形、ne_umh非对称十字形六边形格点搜索。都是先确定一个初始搜索点,然后按照各自的形状进行搜索。
帧内预流程测:
帧内预测并不是计算的宏块的移动,而是在宏观图像上划分的微小宏块都有连续性,颜色是渐变的,不可能在几个像素内颜色突变,所以利用这一部分的相关性来进行预测。宏块周围的其他宏块如果相似度高,则只需要进行一次编码。帧间预测占了大部分冗余,在早期视频编码甚至直接没有做帧内预测,衣蛾帧内预测仅占用较少的冗余。
不同版本编码器中的帧内预测:
帧内预测实际上就是一张图的预测编码,很多时候性能都是和 jpeg 进行对比参考,方法也类似。
h263:采用dct/mc混合编码,也就是帧间预测DPCM和帧内DCT同时进行,也就是说舍弃了帧内预测。
h263+:引入基于频域的帧内预测,利用频域内相邻块的DCT系数 DC和AC的相关性。用当前块DC和AC系数来预测后一块DC和AC系数。不太理想。
h264:改进为空域帧内预测,也就是相邻宏快之间的变换不大,同当前块来预测围绕一圈的相邻块,预测后求残差,对残差(很多0)进行编码。
什么是变换编码,DCT变换?
DCT是离散傅里叶变换。就是将图像转换到频域,去掉高频信息,类似音频的频域高通滤波,在图像领域DCT效果比DFT好。傅里叶变换表明任何信号都可以表示为多个不同振幅和频率的正弦或余弦函数叠加。DCT就是离散余弦变换,也就是输入和离散信号的余弦函数叠加。图像视频领域中,最常用的是DCT-Ⅱ,平常说的DCT一般指的是DTC-Ⅱ。DTC-Ⅲ是 DTC-Ⅱ的反变换,一般说的反DCT指的就是DCT-Ⅲ。由公式可以看出,X(k)就是在频率k下,求序列上各点对应余弦项的累加和。当k=0时,各点的余弦项均为1,此时得到的结果X(0)正比于x(n)的和,被称为直流分量。当k>0时,得到个频率下的X(k)被称为交流分量。

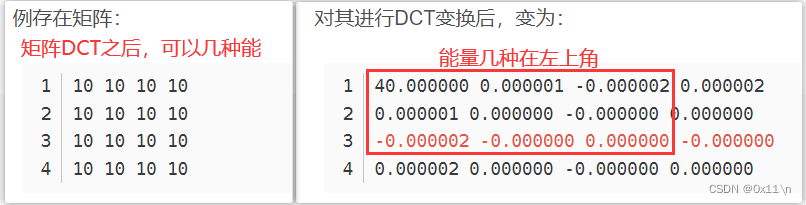
为什么矩阵DCT可以减少信息空间冗余?
因为对图像矩阵存储,一个二维数组进行二维DCT之后,将图像转到频域能量分布图,能量较为集中。
整数DCT:
因为DCT不可避免需要浮点乘法,浮点的经度问题不可避免也就是不能无损压缩。而整数DCT则避免了这个问题。
量化怎么实现?
量化是为了降低比特率,因为编码后的矩阵取值范围大需要过多比特数来表达一个数字。量化需要将某个量强行归一化到某个输出,因为是一对多所以是不可逆过程。视频压缩的亮化过程主要发生在以下过程,在预测、差分、正交变换、之后对这些系数和值的亮化。亮化发生在熵编码之前。例如求残差之后对残差进行DCT变换得到的DCT系数,就需要对系数进行量化以方便后续的熵编码。
标量量化之均匀量化:
指定量化步长,每个标量表示为量化补偿的n个倍数。按照对半的方式,在一个区间内高于步长一半则上取值,低于步长一半则下取值。由此可以知道,一个标量本身小于步长二分之一的话会直接量化为零。
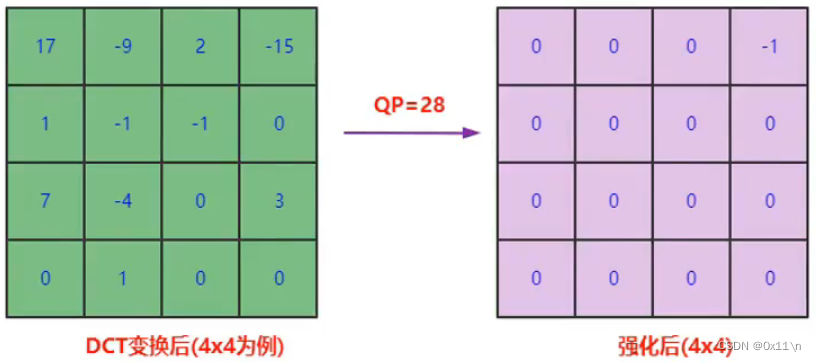
什么是QP量化?
量化就是把信号的连续取值映射成多个离散的幅值的过程,实现了信号取值多对一的映射(参考pcm采样量化)。残差数据进过变换之后,变换系数具有较大的取值范围,量化可以有效减小信号的取值范围,进而获得更好的压缩效果。量化是造成失真的根本原因。在视频编码器中,标量量化操作用(带圆整的)整数除法实现,除数是量化步长(QStep)。举例来说,除 10 再圆整到最近的整数操作会将 量化到 0, 量化到 1。量化步长越大,量化强度与信号损失越高。反量化是由标准规定的,基本上就是量化后的信号乘上量化步长。
动态码率和QP量化的联系?
因为QP量化影响码率,QP越高压缩率越高则视频码率越低视频越模糊。在一些直播场景中,可以根据贷款情况动态设置码率。
矢量量化过程是什么?
矢量是一组量本点,矢量通常通过欧氏距离来求是否近似。会有一个码本库包含很多矢量。矢量量化就是从库中找到一个矢量和当前需要量化的矢量最相似的,然后记录库中的下标。传递时仅仅需要传递下标即可。实际上视频编码的矢量通常是运动矢量也就是2维坐标来描述运动的方向和距离。
锯齿扫描和游程编码:
游程编码类似哈夫曼编码,也就是统计连续出现的个数来进行压缩。在DCT之后还需要系数的量化,量化之后会出现很多0且集中在右下角。通过锯齿扫描出来然后用游程编码进行压缩传递。

熵编码是什么?
熵编码即编码过程中按熵原理不丢失任何信息的编码。信息熵为信源的平均信息量(不确定性的度量)。常见的熵编码有:香农(Shannon)编码、哈夫曼(Huffman)编码和算术编码(arithmetic coding)。
如何评价视频编码质量?
在实际运用中,视频编解码后质量评估,ITU规定了一种主观标志的测试程序,最常用的方法DSC-QS。通过人眼主观打分。而客观的评价标准则是使用 MSE(均方根误差)、SNR(信噪比)、PSNR(峰值信号比) 来判断质量。以输入图像 f(x,y) 为原始图像,g(x,y)为压缩后图像,图像分辨率 m*n,则f和g的质量评估公式为,注意需要在YUV三个分量上分别计算mse、snr、psnr。