上周末写ddp,常常遇到中途退出的问题,解决中途遇到了很多CPU线程数和核心数的问题,记录如下
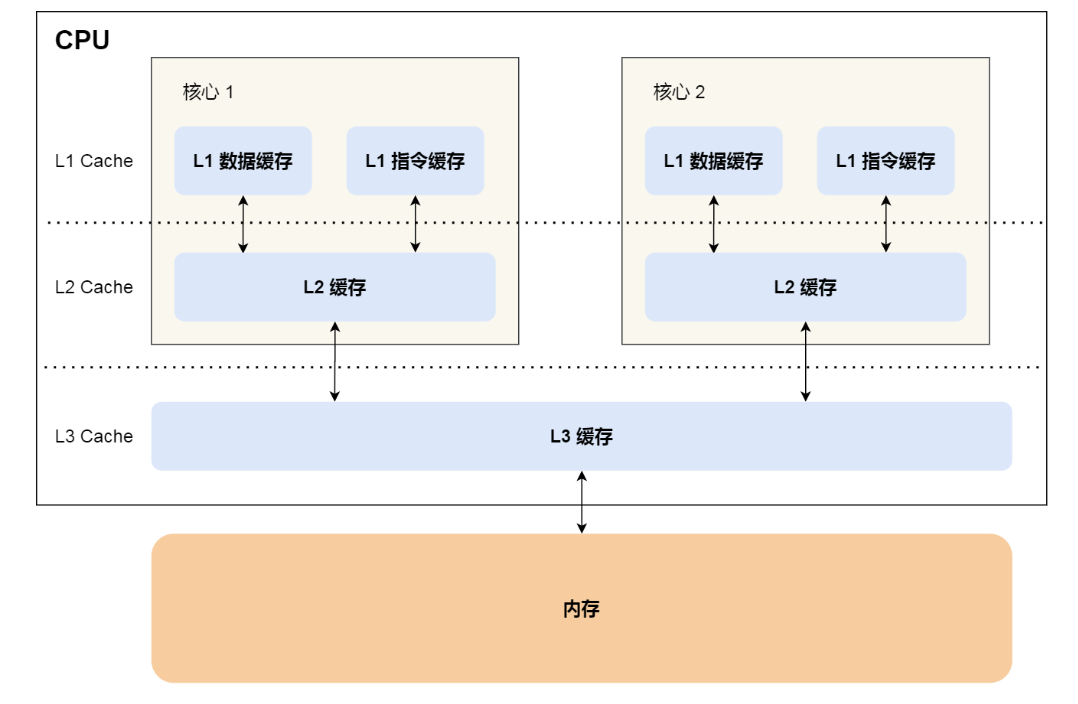
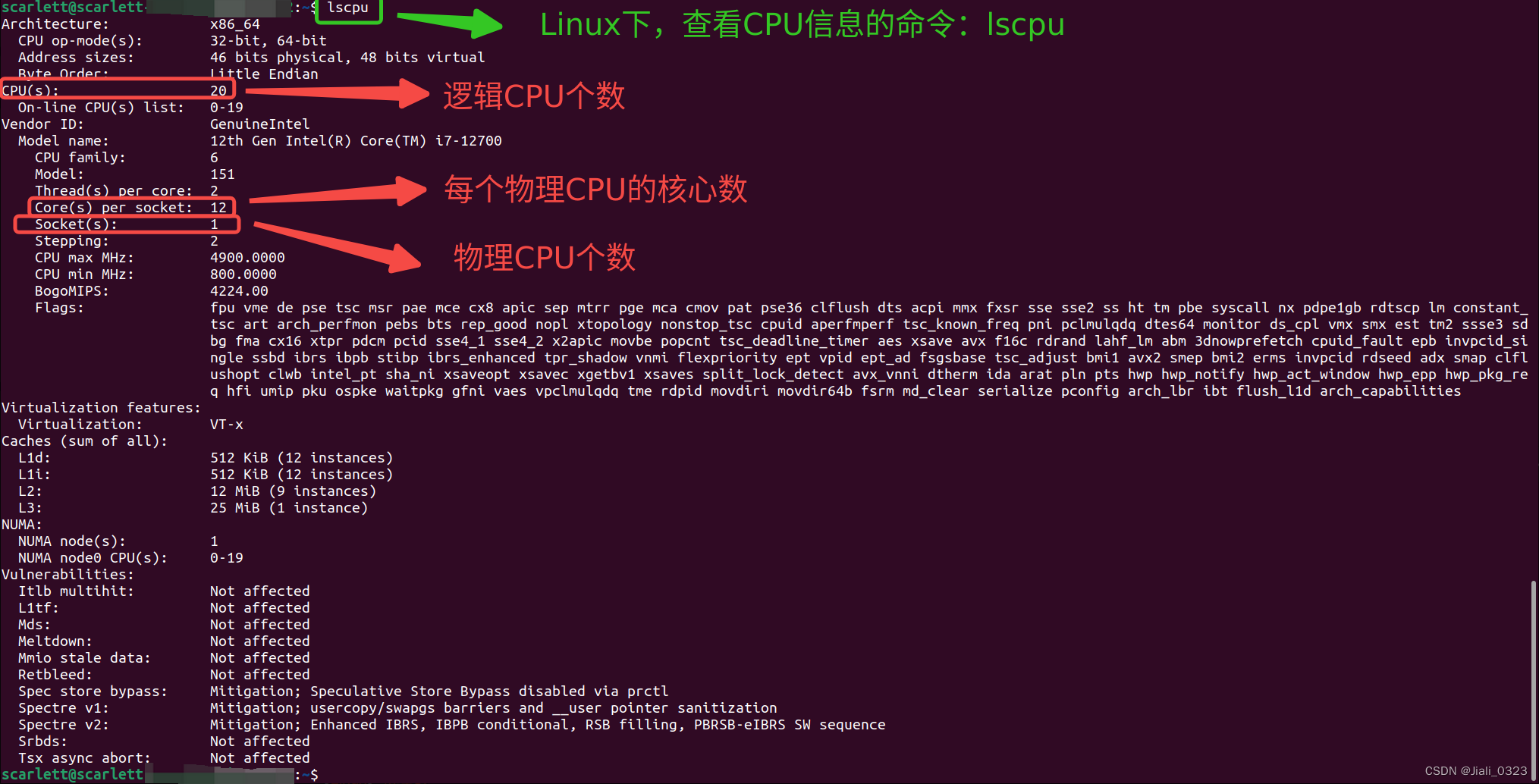
1. 物理cpu、逻辑cpu、cpu核数、超线程
这一部分主要来自什么是物理cpu,什么是逻辑cpu,什么cpu核数,什么是超线程?
a. 物理CPU
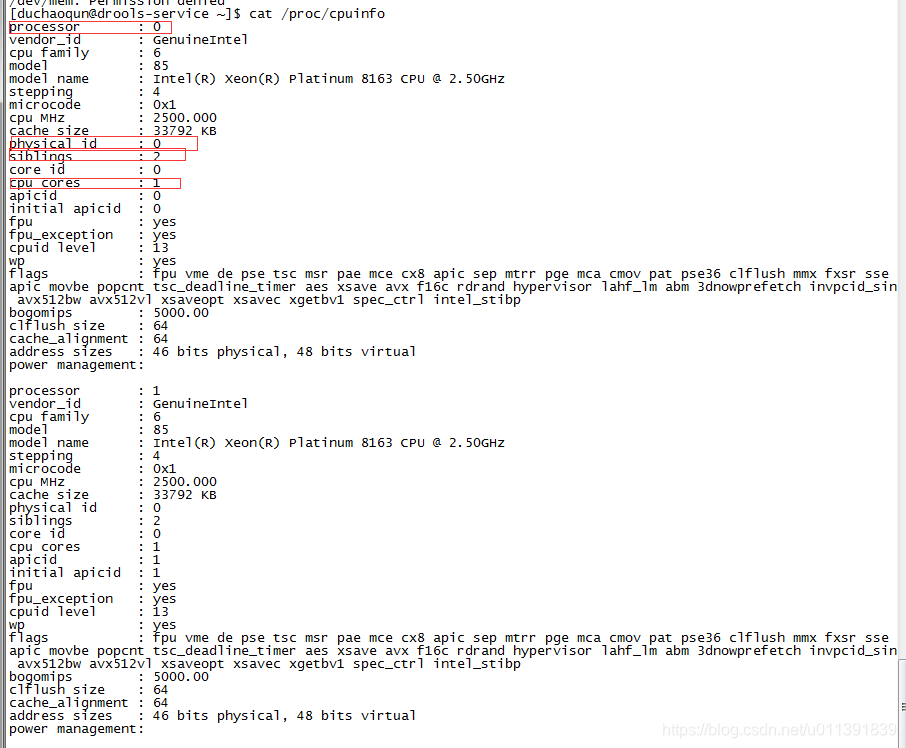
就是实实在在插在主机上看得见摸得着那块CPU硬件,可通过如下命令来查看物理CPU个数:
cat /proc/cpuinfo | grep 'physical id' | sort | uniq | wc -l
下图代表服务器有两块cpu

b.cpu核数
一块物理CPU上能处理数据的芯片组数量。也就是说一个物理CPU上可能会有多个核心,日常中说的双核,四核就是指的CPU核心。可通过如下命令来查看CPU核心数:
cat /proc/cpuinfo | grep 'core id' | sort | uniq | wc -l
下图代表一块cpu有10个核心

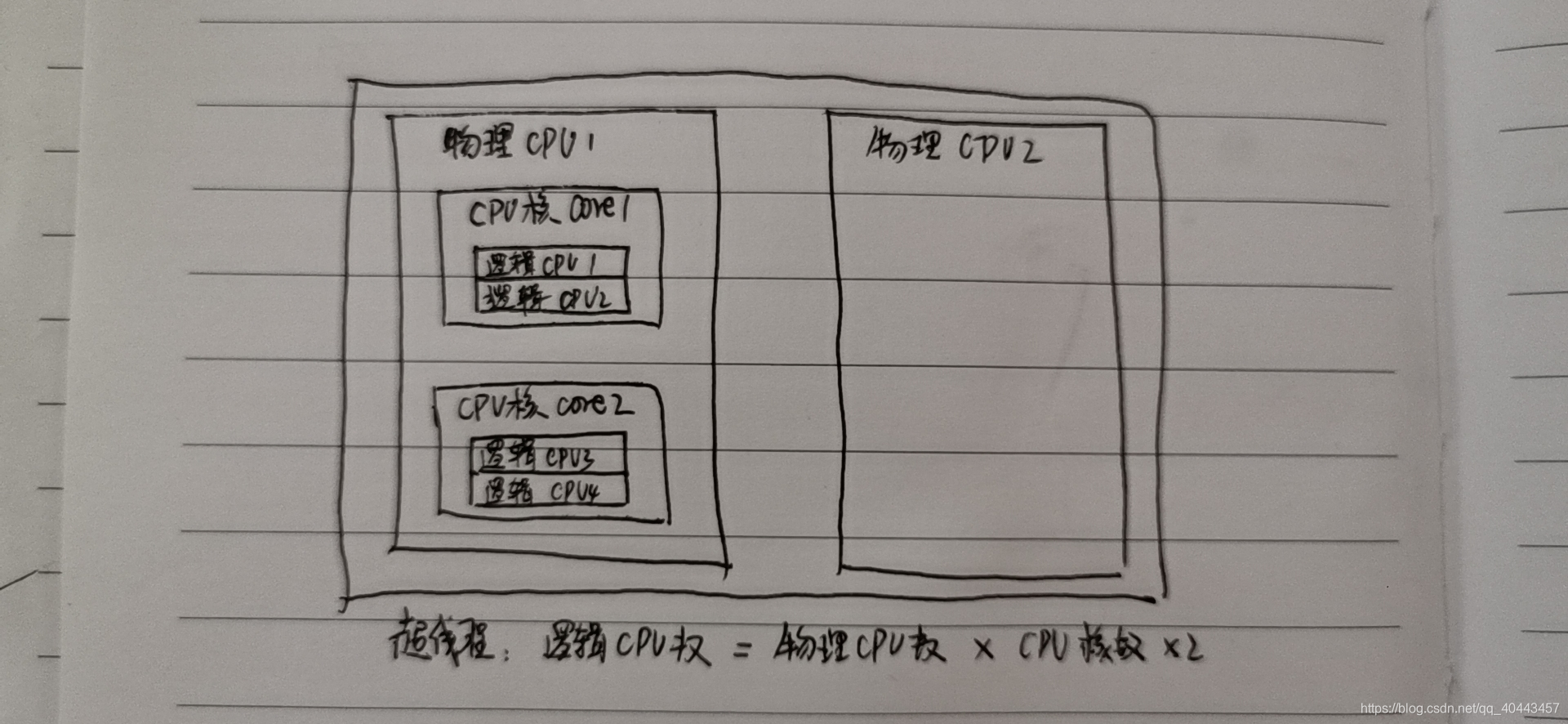
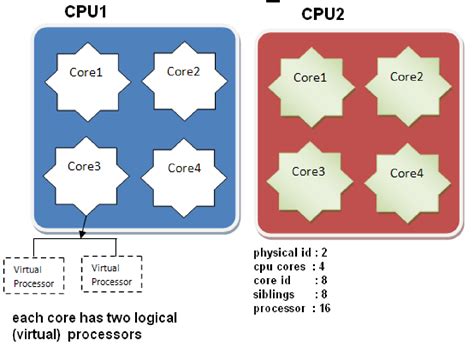
c.超线程
一个CPU核就是一个物理线程,由英特尔开发超线程技术可以把一个物理线程模拟出两个线程来使用,使得单个核心用起来像两个核一样,以充分发挥CPU的性能。
d.逻辑cpu
逻辑CPU的概念比较抽象,可简单理解为一个处理单元,通常来说,总的逻辑CPU数对应总的CPU核数,但借助超线程技术,一个核用起来像两个核,这时逻辑CPU数就是核心数的两倍了。可通过如下命令来查看逻辑CPU数:
cat /proc/cpuinfo | grep 'processor' | sort | uniq | wc -l
下图代表服务器逻辑cpu数为40,显然开启了超线程

总核数 = 物理CPU个数 X 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
top指令中的%cpu就是占用的逻辑cpu数,如下图为占用一个逻辑cpu

2. Pytorch设置线程数
a. torch.set_num_threads
这一部分来自Set the Number of Threads to Use in PyTorch
Pytorch使用CPU计算op时默认使用OpenMP进行并行计算,一般默认使用全部CPU线程(即逻辑cpu数)的一半
set_num_threads()用于设置CPU上用于内部操作(intra operations)的线程数。 根据这里的讨论,内部操作大致是指在一个操作中执行的操作,例如矩阵乘法。 默认情况下,pytorch将使用计算机上所有可用的内核(比如我这里是2*10=20),为了验证这一点,我们可以使用torch.get_num_threads()获取默认线程数。
import timeimport torch
import numpy as np
import os
#torch.set_num_threads(8) 这里有注释!
while True:arr= np.zeros((100,3, 300, 300), dtype=np.float32)start=time.time()aaa=torch.from_numpy(arr)start = time.time()aaa.add_(-0.406)print('time2',time.time() - start)print("hello")print("num_threads: %d" % torch.get_num_threads())
输出如下,可以看到用了一半的逻辑cpu数

取消上面对torch.set_num_threads(8)的注释

下图可以看到占用了约8个线程

对于支持并行性的操作,增加线程的数量通常会使CPU上的执行速度更快。 除了通过pytorch设置线程数,还可以设置环境变量OMP_NUM_THREADS或MKL_NUM_THREADS来设置线程数。
b. torch.set_num_threads 和’MKL_NUM_THREADS’ 'OMP_NUM_THREADS’三个的区别是什么?
先贴pytorch官方解释两图


以下部分参考pytorch模型在multiprocessing下前馈速度明显降低的原因是什么?
Pytorch使用CPU计算op时默认使用OpenMP进行并行计算。每次模型进行inference的时候,pytorch的核心会fork出多个线程进行Inter-op的并行计算,在每个op计算的内部(Intra-op)又会使用ATen,MKL,MKL-DNN等矩阵加速库进行加速,并使用OpenMP(默认)或TBB进行多线程计算。
标题提到的torch.set_num_threads 和’MKL_NUM_THREADS’ 'OMP_NUM_THREADS’,其实我也分不太清楚。记住有优先级并且’MKL_NUM_THREADS’ 'OMP_NUM_THREADS’一起设置为torch.set_num_threads的数目好了即三个设置成一样的,怕出错就按如下顺序设置。
torch.set_num_threads(1)os.environ["OMP_NUM_THREADS"] = "1" # 设置OpenMP计算库的线程数os.environ["MKL_NUM_THREADS"] = "1" # 设置MKL-DNN CPU加速库的线程数。
c.ddp下的线程设置
pytorch下的DistributedDataParallel(即ddp),推荐每个进程的OMP_NUM_THREADS设置为1,防止系统过载。(但这样挺低效的,根据自己的子进程数来看叭)
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variabl
e for optimal performance in your application as needed.
它推荐的设置法(亲测环境变量加在这里比代码中有效)
OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python -m torch.distributed.launch --nproc_per_node=2 test.py
d.num_workers下的线程数
关于DataLoader num_workers 和 torch.set_num_threads
The num_workers for the DataLoader specifies how many parallel workers to use to load the data and run all the transformations. If you are loading large images or have expensive transformations then you can be in situation where GPU is fast to process your data and your DataLoader is too slow to continuously feed the GPU. In that case setting higher number of workers helps. I typically increase this number until my epoch step is fast enough. Also, a side tip: if you are using docker, usually you want to set shm to 1X to 2X number of workers in GB for large dataset like ImageNet.
The torch.set_num_threads specifies how many threads to use for parallelizing CPU-bound tensor operations. If you are using GPU for most of your tensor operations then this setting doesn’t matter too much. However, if you have tensors that you keep on cpu and you are doing lot of operations on them then you might benefit from setting this. Pytorch docs, unfortunately, don’t specify which operations will benefit from this so see your CPU utilization and adjust this number until you can max it out.
总结就是这两没有关系,num_workers是独立于程序单独开出来的torch.set_num_threads是pytorch给cpu做并行的。
如果我使用
OMP_NUM_THREADS=10 MKL_NUM_THREADS=10 python -m torch.distributed.launch --nproc_per_node=2 test.py
会得到下面的结果,十个线程。两个是ddp给的进程(前两个),后面八个是4*2即两个进程分别的num_workers用于读取数据。

3. torch.set_num_threads没用?
个人觉得三个原因(可能)
A. 刚刚的图片展示了,其实我每个进程都是torch.set_num_threads(10),但是cpu的进程7010和7006才分别用了不到200%。很大可能是cpu上进行的数据操作不多,时间很短也用不不着这么多线程就结束了,这个是最有可能的
B. 要把num_workers 也设置不为零
来自https://github.com/pytorch/pytorch/issues/19213
This only happens when num_workers is set for the dataloader. If num_workers is not set, torch.set_num_threads works correctly. I’d say it’s like set_num_threads is not inherited by the dataloader workers, which fall back to the default.
C. opencv中也用了openmp做加速,有时出现死锁。可以设置
cv2.setNumThreads(0)
cv2.ocl.setUseOpenCL(False)
个人不推荐使用
参考链接
1.什么是物理cpu,什么是逻辑cpu,什么cpu核数,什么是超线程?
2. Linux下确认CPU是否开启超线程
3. Linux OS下,你真的读懂了cat /proc/cpuinfo 吗?
4. torch.set_num_threads
5. Set the Number of Threads to Use in PyTorch
6. DataLoader num_workers vs torch.set_num_threads
7.pytorch锁死在dataloader(训练时卡死)




![[转]物理CPU、CPU核数、逻辑CPU、超线程](https://images2017.cnblogs.com/blog/1225554/201802/1225554-20180207112903232-661620709.png)