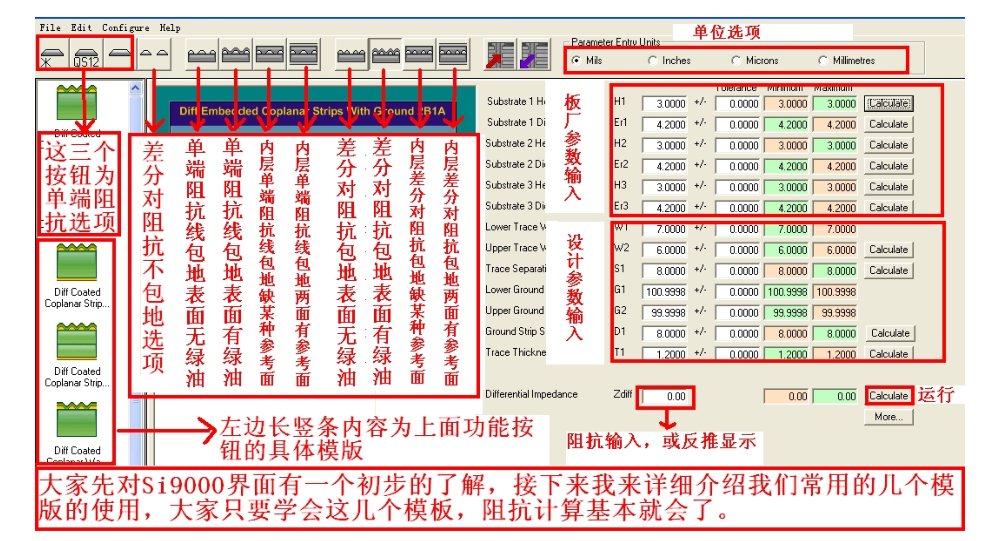
特征阻抗和阻抗匹配
过去十年来,ORM的许多批评都错了这一点,因为它不准确。 到本文结尾,我们将得出以下结论:
关系(数据)模型和面向对象的模型之间没有显着差异
如何得出这个结论? 继续阅读!
我们如何相信这种谬论
许多流行的博客作者和意见领袖都没有机会抨击ORM,因为它们与关系世界的“明显”阻抗不匹配。 N + 1 , 效率低下的查询 , 库的复杂性 , 抽象的泄漏 ,各种流行语已被用来消除ORM,尽管没有提供可行的替代方案,但它们通常包含很多真相。
但是这些文章是否真的在批评正确的事情?
上面的文章中很少有人会认识到一个中心事实,这是Erik Meijer和Gavin Bierman在其非常有趣的论文“ 大型共享数据银行的数据的关联模型 ”中雄辩地幽默地提出的:
与流行的看法相反,SQL和noSQL实际上只是同一枚硬币的两个方面。
换句话说:“分层”对象世界和“关系”数据库世界为完全相同的事物建模。 唯一的区别是在图中绘制箭头的方向。
让它沉入。
- 在关系模型中,孩子指向父母。
- 在分层模型中,父母指向孩子。
这里的所有都是它的。
什么是ORM?
ORM填补了两个世界之间的桥梁。 如果您愿意,它们就是箭头的逆变器 。 他们将确保RDBMS中的每个“关系”都可以在“分层”世界中实现为“聚合”或“组合”(这适用于对象,XML,JSON和任何其他格式)。 他们确保正确实现此类实现。 可以正确地跟踪对单个属性或关系(聚合,组成)属性所做的更改,并将其清除回持久模型的主模型数据库中。 各个ORM 除了将各个实体映射到各个类型之外 ,在提供的功能以及它们提供多少映射逻辑方面也有所不同。
- 一些ORM可能会帮助您实现锁定
- 有些可以帮助您修补模型不匹配的问题
- 有些人可能只专注于这些类和表之间的1:1映射
但是所有ORM都做一件非常简单的事情。 最终,它们从表中获取行,并将其具体化为类模型中的对象,反之亦然。
顺便说一下,最近在Vertabelo博客上对不同的ORM进行了很好的概述 。
表和类是同一回事
给出或采用1-2个实现细节,RDBMS的表和OO语言的类是同一回事。 一组分组属性的规范,每个属性及其关联的类型。 考虑以下使用SQL和Java的示例:
SQL
CREATE TABLE author (first_name VARCHAR(50),last_name VARCHAR(50)
);Java
class Author {String firstName;String lastName;
}两者之间绝对没有概念上的区别-映射很简单。 当您考虑不同实体/类型之间的“关系” /“组成”时,映射甚至非常简单:
SQL(为简单起见,我们省略了约束)
CREATE TABLE author (id BIGINT,first_name VARCHAR(50),last_name VARCHAR(50)
);CREATE TABLE book (id BIGINT,author_id BIGINT,title VARCHAR(50),
);Java
class Author {Long id;String firstName;String lastName;Set<Book> books;
}class Book {Long id;Author author;String title;
}省略了实现细节(可能占批评的一半)。 但是,由于省略了更多细节,因此可以将数据库中的各个行直接进行1:1映射,而不会感到惊讶。 大多数ORM(尤其是在Java生态系统Hibernate中)已经很好地实现了上述想法,而隐藏了在RDBMS和Java之间实际进行这种模型转换的所有技术细节。
换一种说法:
这种映射方法绝对没有错!
然而:某处存在* IS *阻抗不匹配
许多博客作者批评的“问题”并非源于两种模型表示形式之间不存在的不匹配(“关系”与“分层”)。 问题来自SQL,它是关系代数的一种不错的实现。
实际上,在以下情况之间也存在着每个人都批评的不匹配现象:
- 关系模型
- 关系代数
已经定义了关系代数,以便能够查询关系并形成新的特殊关系作为此类查询的输出。 根据所应用的操作和转换,结果元组可能与查询中涉及的各个实体完全无关 。 换句话说,关系代数,尤其是SQL的乘积没有用,因为ORM不再可以对其进行进一步处理,更不用说将其持久化回到数据库了。
为了使事情变得“更糟”,如今SQL是关系代数所提供功能的大型超集。 它比起初设想时有用得多。
为什么这种不匹配仍然会影响现代ORM
前面的段落概述了ORM受到真正批评的唯一主要原因,即使此类批评通常没有提及确切原因:
SQL /关系代数并不是真正适合将关系部分实现到客户端/将更改存储回数据库。 但是,大多数RDBMS只能为该工作提供SQL。
回到作者/书籍示例。 当您想要将作者及其书籍加载并显示给Web应用程序的用户时,您只想简单地获取该作者及其书籍,就可以调用诸如author.add(book)以及author.remove(book)类的简单方法。然后让魔术将您的数据刷新回存储系统。
考虑为这样一个简单的CRUD任务编写SQL代码量会让每个人尖叫。
人生苦短,无法花时间去CRUD
也许QUEL对于CRUD可能是更好的语言 ,但是那艘船已经航行了。 不幸的是,由于SQL是不适合该工作的语言,您不能忽略这种“魔术”,而必须充分了解幕后发生的事情,例如通过调整Hibernate的获取策略 。
转换为SQL后,可以通过几种方式实现:
1.使用JOIN获取
使用外部联接,可以一次性查询所有涉及的实体:
SELECT author.*, book.*
FROM author
LEFT JOIN book ON author.id = book.author_id
WHERE author.id = ?优点:
- 可以发出单个查询,并且可以一次传输所有数据
缺点:
- 作者属性在每个元组中重复。 客户端(ORM)必须先删除作者的重复数据,然后再填充作者与书籍的关系。 当您有多个嵌套关系应立即获取时,这可能特别糟糕。
2.使用SELECT获取
为每个实体发出一个查询:
SELECT *
FROM author
WHERE id = ?SELECT *
FROM book
WHERE author_id = ?优点:
- 要传输的数据量很小:每行仅传输一次。
缺点:
- 发出的查询数量可能会爆发成众所周知的N + 1问题 。
Hibernate尤其了解其他类型的获取策略,尽管它们本质上是上述方法之一的变体/优化。
为什么不使用SQL MULTISET?
在这种情况下,使用高级SQL来获取所有数据的理想方法是使用MULTISET :
SELECT author.*, MULTISET (SELECT book.*FROM bookWHERE book.author_id = author.id
) AS books
FROM author
WHERE id = ?上面的代码实际上将为每个作者创建一个嵌套的集合:
first_name last_name books (nested collection)
--------------------------------------------------Leonard Cohen title--------------------------Book of MercyStranger MusicBook of LongingErnest Hemingway title--------------------------For Whom the Bell TollsThe Old Man and the Sea 如果添加另一个嵌套实体,则很容易看到另一个MULTISET如何允许附加嵌套数据:
SELECT author.*, MULTISET (SELECT book.*, MULTISET (SELECT c.*FROM language AS tJOIN book_language AS blON c.id = bc.language_idAND book.id = bc.book_id) AS languagesFROM bookWHERE book.author_id = author.id
) AS books
FROM author
WHERE id = ?现在的结果是:
first_name last_name books
-----------------------------------------------------Leonard Cohen title languages-----------------------------Book of Mercy language------------enStranger Music language------------endeBook of Longing language------------enfres优点:
- 单个查询可以以最小的带宽使用来实现所有渴望加载的行。
缺点:
- 没有。
不幸的是,RDBMS对MULTISET的支持很差。
MULTISET SQL:2003起 , MULTISET (以及数组和其他集合类型)已正式引入SQL标准中,这是将OO功能嵌入SQL语言的一项举措。 例如,Oracle已经实现了大部分功能,就像Informix一样,或者鲜为人知的CUBRID(尽管使用了特定于供应商的语法) 。
其他数据库(例如PostgreSQL)允许将嵌套的行聚合到类型化数组中 ,尽管需要更多的语法工作,但其工作方式相同。
MULTISET和其他ORDBMS SQL功能是完美的折衷方案,可以将“关系”模型的MULTISET与“分层”模型的MULTISET相结合。 允许一次性将CRUD操作与查询结合在一起,无需复杂的ORM,因为SQL语言可以直接用于将所有数据从(关系)数据库映射到(分层)客户端表示形式,而不会产生摩擦。
结论并号召行动!
我们正在行业中度过激动人心的时代。 房间里的大象(SQL)仍然在这里 , 一直在学习新的技巧。 关系模型为我们提供了很好的服务,并且在各种实现中都丰富了分层模型。 函数式编程越来越受关注,以非常有用的方式补充了面向对象的功能。
想一想胶水,将所有这些伟大的技术概念放在一起,就可以:
- 在关系模型中存储数据
- 在分层模型中实现数据
- 使用功能编程处理数据
如此出色的技术组合很难被击败- 我们已经展示了SQL和函数式编程如何与jOOQ一起使用 。 我们认为,所缺少的只是更好地支持RDBMS供应商提供的MULTISET和其他ORDBMS功能。
因此,我们敦促PostgreSQL开发人员:您正在创建最创新的数据库之一。 Oracle在该领域领先于您-但它们的实现与PL / SQL紧密联系在一起,这使其笨拙。 但是,您错过了最出色SQL功能集之一。 构造嵌套集合(不仅是数组)并有效查询它们的能力。 如果您带路,其他RDBMS也将随之而来。
我们终于可以停止浪费时间谈论对象关系阻抗非匹配问题。
翻译自: https://www.javacodegeeks.com/2015/08/there-is-no-such-thing-as-object-relational-impedance-mismatch.html
特征阻抗和阻抗匹配