数据同步工具的研究(实时同步):
FlinkCDC、Canal、Maxwell、Debezium
——2023年01月17日
——Yahui Di
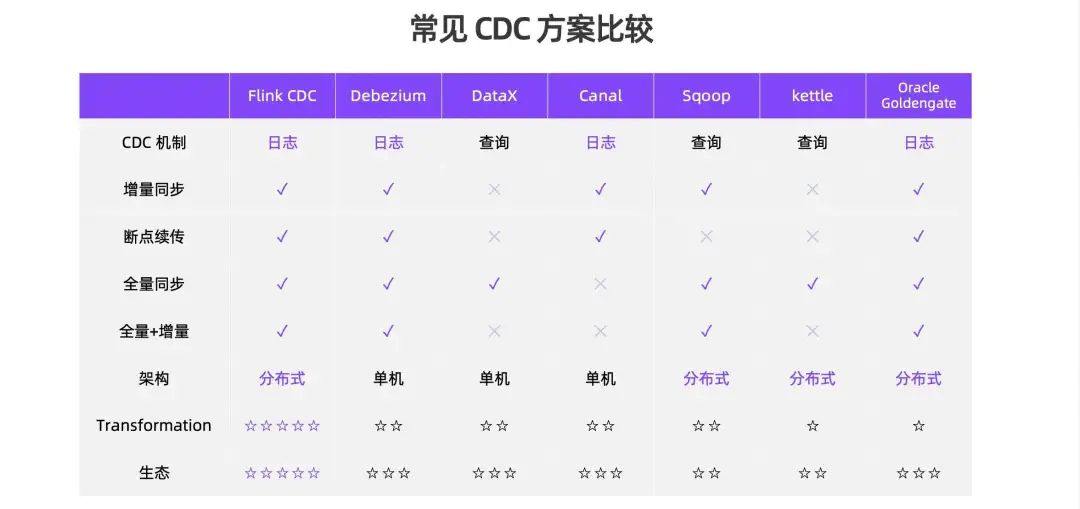
1. 常用CDC方案比较
2. FlinkCDC
FlinkCDC的简介:
Flink CDC 连接器是 Apache Flink 的一组源连接器,使用变更数据捕获 (CDC) 从不同的数据库中获取变更数据。 Flink CDC 连接器集成了 Debezium 作为捕获数据变化的引擎。 所以它可以充分利用 Debezium 的能力。
FlinkCDC的要求和优点:
-
FlinkCDC 2.0版本前同步历史数据是要锁全表的,现在是基于主键的历史数据批次读取,并使用增量快照读取的算法避免了全局读锁。
-
HA方面,支持基于GTID的MySQL的全链路高可用
-
FlinkCDC支持多种多样的connector,最新的2.3版本支持MongoDB、MySQL5.6+、OceanBase、Oracle、Postgres、SQLServer、TiDB、DB2
-
FlinkCDC支持精确一次性,支持断点续传。
-
基于FlinkCDC的数据同步链路,无需多余组件如Kafka等存储CDC-Log,在Datastream API中,目前已支持一个作业同步多个库中多张表的数据变更
-
FlinkCDC仅要求FLink1.12+和Java 8+环境
增量快照的实现:
首先并行读取表的快照,其次但并行度读取表的binlog。
在快照阶段,根据表的主键和表行的大小,将快照切割成多个快照块。 快照块被分配给多个快照读取器。 每个快照读取器使用块读取算法读取其接收到的块,并将读取的数据发送到下游。 Source 管理 chunk 的进程状态(完成或未完成),因此快照阶段的 source 可以支持 chunk 级别的检查点。 如果发生故障,可以恢复源并继续从最后完成的块中读取块。
在所有快照块完成后,源将继续在单个任务中读取 binlog。 为了保证snapshot记录和binlog记录的全局数据顺序,binlog reader会在snapshot chunk结束后开始读取数据,直到有一个完整的checkpoint,确保所有的snapshot数据都被下游消费完。 binlog reader 跟踪消耗的 binlog 在 state 中的位置,因此 binlog 阶段的源可以支持行级的检查点。
Flink 会定期为源执行检查点,在故障转移的情况下,作业将重新启动并从上次成功的检查点状态恢复,并保证 exactly once 语义。
快照的快切分策略:
在执行增量快照读取时,MySQL CDC 源需要一个用于拆分表的标准。 MySQL CDC Source 使用拆分列将表拆分为多个拆分(块)。 默认情况下,MySQL CDC source 会识别表的主键列,并将主键中的第一列作为拆分列。 如果表中没有主键,增量快照读取将失败,您可以禁用 scan.incremental.snapshot.enabled 以回退到旧的快照读取机制。
对于数字和自动增量拆分列,MySQL CDC Source 按固定步长有效地拆分块。 比如你有一张表,主键列id为自增BIGINT类型,最小值为0,最大值为100,表选项scan.incremental.snapshot.chunk.size值为25 ,该表将被分成以下块:
(-∞, 25),
[25, 50],
[50, 75],
[75, 100],
[100, +∞)
对于其他主键列类型,MySQL CDC Source 执行SELECT MAX(STR_ID) AS chunk_high FROM (SELECT * FROM TestTable WHERE STR_ID > 'uuid-001' limit 25)形式的语句,得到每个列的低值和高值 块,拆分块集将是这样的:
(-∞, 'uuid-001'),
['uuid-001', 'uuid-009'),
['uuid-009', 'uuid-abc'],
['uuid-abc', 'uuid-def'),
[uuid-def, +∞).
快照的块读取策略:
对于上面的示例 MyTable,如果 MySQL CDC Source 并行度设置为 4,则 MySQL CDC Source 将运行 4 个读取器,每个读取器执行偏移信号算法以获得快照块的最终一致输出。 偏移信号算法简单描述如下:
(1)记录当前binlog位置为LOW offset
(2) 执行SELECT * FROM MyTable WHERE id > chunk_low AND id <= chunk_high 读取快照chunk记录并缓存
(3)记录当前binlog位置为HIGH offset
(4) 从LOW offset到HIGH offset读取属于snapshot chunk的binlog记录
(5) 将读取到的binlog记录Upsert到buffered chunk records中,并将buffer中的所有记录作为snapshot chunk的最终输出(均为INSERT记录)
(6) 继续读取并发出属于单个binlog reader中HIGH偏移量之后的chunk的binlog记录。
注:
如果主键的实际值在其范围内不均匀分布,这可能会导致增量快照读取时发生数据倾斜。
一个MySQLCDC的示例:
基于SQL Client:
-- creates a mysql cdc table source
CREATE TABLE mysql_binlog (
id INT NOT NULL,
name STRING,
description STRING,
weight DECIMAL(10,3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'flinkuser',
'password' = 'xxxxxx',
'database-name' = 'inventory',
'table-name' = 'products'
);
-- read snapshot and binlog data from mysql, and do some transformation, and show on the client
SELECT id, UPPER(name), description, weight FROM mysql_binlog;
基于DataStream API:
<dependency>
<groupId>com.ververica</groupId>
<!-- add the dependency matching your database -->
<artifactId>flink-connector-mysql-cdc</artifactId>
<!-- The dependency is available only for stable releases, SNAPSHOT dependency need build by yourself. -->
<version>2.3-SNAPSHOT</version>
</dependency>
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // set captured database
.tableList("yourDatabaseName.yourTableName") // set captured table
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}
}
FlinkCDC官方文档:
https://github.com/ververica/flink-cdc-connectors/blob/release-2.1/docs/content/connectors/mysql-cdc.md
3. Canal
Canal简介:
Canal意为管道/水渠,主要用途是提供MySQL数据库增量日志解析,以及增量数据订阅和消费。
主要针对场景:
1)数据库镜像
2)数据库实时备份
3)索引构建和实时维护(如拆分异构索引或倒排索引)
4)业务cache刷新
5)带有业务逻辑的增量ETL
当前支持的版本:
MySQL 5.1,5.5,5.6+
工作原理:
MySQL主从复制原理:
伪装成MySQL Server的Slave来获取权限并读取Binlog日志,以支持后续的操作。
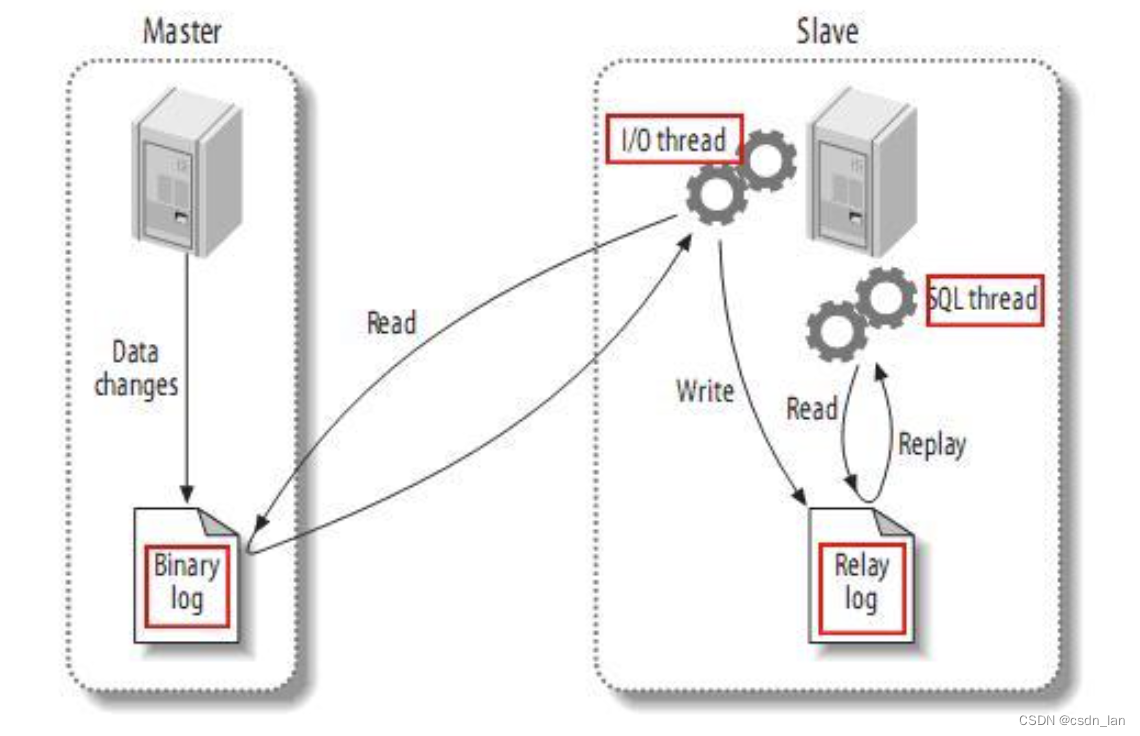
1)MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
2)MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
Canal工作原理:
1)canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
2)MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
3)canal 解析 binary log 对象(原始为 byte 流)
Canal官方文档:
https://github.com/zendesk/maxwell
4. Maxwell
Maxwell简介:
这是 Maxwell 的守护进程,一个读取 MySQL 二进制日志并将行更新作为 JSON 写入 Kafka、Kinesis 或其他流平台的应用程序。 Maxwell 的操作开销很低,只需要 mysql 和一个可以写入的地方。 它的常见用例包括 ETL、缓存构建/过期、指标收集、搜索索引和服务间通信。 Maxwell 为您提供了事件溯源的一些好处,而无需重新构建整个平台。
Maxwell与Canal的区别:
Canal可自定义数据格式,Maxwell只支持JSON;
Maxwell 没有 Canal那种server+client模式,只有一个server把数据发送到消息队列或redis;
Maxwell支持数据断点续传,有bootstrap功能,可以直接引导出完整的历史数据用于初始化,但Canal只能抓取最新数据,对已存在的历史数据没有办法处理,没有自己的bootstrap,因此不支持数据断点续传;
Maxwell简单部署的话,仅需要Kafka即可,对于需要快速迭代的项目比较友好,
Canal需要用户自行实现客户端用来消费数据。整体来说部署更为复杂,较适合中大型的项目。
对于一次增删改变更,Canal会记录集合的数据,但Maxwell会产生多表数据。
Canal的CDC数据会带入数据结构,Maxwell不会。
Maxwell官方文档:
GitHub - zendesk/maxwell: Maxwell's daemon, a mysql-to-json kafka producer
5. Debezium
Debezium简介:
Debezium是一个开源项目,为捕获数据更改(change data capture,CDC)提供了一个低延迟的流式处理平台。你可以安装并且配置Debezium去监控你的数据库,然后你的应用就可以消费对数据库的每一个行级别(row-level)的更改。只有已提交的更改才是可见的,所以你的应用不用担心事务(transaction)或者更改被回滚(roll back)。Debezium为所有的数据库更改事件提供了一个统一的模型,所以你的应用不用担心每一种数据库管理系统的错综复杂性。另外,由于Debezium用持久化的、有副本备份的日志来记录数据库数据变化的历史,因此,你的应用可以随时停止再重启,而不会错过它停止运行时发生的事件,保证了所有的事件都能被正确地、完全地处理掉。
Debezium基础架构:
Debezium是一个捕获数据更改(CDC)平台,并且利用Kafka和Kafka Connect实现了自己的持久性、可靠性和容错性。每一个部署在Kafka Connect分布式的、可扩展的、容错性的服务中的connector监控一个上游数据库服务器,捕获所有的数据库更改,然后记录到一个或者多个Kafka topic(通常一个数据库表对应一个kafka topic)。Kafka确保所有这些数据更改事件都能够多副本并且总体上有序(Kafka只能保证一个topic的单个分区内有序),这样,更多的客户端可以独立消费同样的数据更改事件而对上游数据库系统造成的影响降到很小(如果N个应用都直接去监控数据库更改,对数据库的压力为N,而用debezium汇报数据库更改事件到kafka,所有的应用都去消费kafka中的消息,可以把对数据库的压力降到1)。另外,客户端可以随时停止消费,然后重启,从上次停止消费的地方接着消费。每个客户端可以自行决定他们是否需要exactly-once或者at-least-once消息交付语义保证,并且所有的数据库或者表的更改事件是按照上游数据库发生的顺序被交付的。
对于不需要或者不想要这种容错级别、性能、可扩展性、可靠性的应用,他们可以使用内嵌的Debezium connector引擎来直接在应用内部运行connector。这种应用仍需要消费数据库更改事件,但更希望connector直接传递给它,而不是持久化到Kafka里。
常见使用场景:
缓存失效(Cache invalidation)
在缓存中缓存的条目(entry)在源头被更改或者被删除的时候立即让缓存中的条目失效。如果缓存在一个独立的进程中运行(例如Redis,Memcache,Infinispan或者其他的),那么简单的缓存失效逻辑可以放在独立的进程或服务中,从而简化主应用的逻辑。在一些场景中,缓存失效逻辑可以更复杂一点,让它利用更改事件中的更新数据去更新缓存中受影响的条目。
简化单体应用(Simplifying monolithic applications)
许多应用更新数据库,然后在数据库中的更改被提交后,做一些额外的工作:更新搜索索引,更新缓存,发送通知,运行业务逻辑,等等。这种情况通常称为双写(dual-writes),因为应用没有在一个事务内写多个系统。这样不仅应用逻辑复杂难以维护,而且双写容易丢失数据或者在一些系统更新成功而另一些系统没有更新成功的时候造成不同系统之间的状态不一致。使用捕获更改数据技术(change data capture,CDC),在源数据库的数据更改提交后,这些额外的工作可以被放在独立的线程或者进程(服务)中完成。这种实现方式的容错性更好,不会丢失事件,容易扩展,并且更容易支持升级。
共享数据库(Sharing databases)
当多个应用共用同一个数据库的时候,一个应用提交的更改通常要被另一个应用感知到。一种实现方式是使用消息总线,尽管非事务性(non-transactional)的消息总线总会受上面提到的双写(dual-writes)影响。但是,另一种实现方式,即Debezium,变得很直接:每个应用可以直接监控数据库的更改,并且响应更改。
数据集成(Data integration)
数据通常被存储在多个地方,尤其是当数据被用于不同的目的的时候,会有不同的形式。保持多系统的同步是很有挑战性的,但是可以通过使用Debezium加上简单的事件处理逻辑来实现简单的ETL类型的解决方案。
命令查询职责分离(CQRS)
在命令查询职责分离 Command Query Responsibility Separation (CQRS) 架构模式中,更新数据使用了一种数据模型,读数据使用了一种或者多种数据模型。由于数据更改被记录在更新侧(update-side),这些更改将被处理以更新各种读展示。所以CQRS应用通常更复杂,尤其是他们需要保证可靠性和全序(totally-ordered)处理。Debezium和CDC可以使这种方式更可行:写操作被正常记录,但是Debezium捕获数据更改,并且持久化到全序流里,然后供那些需要异步更新只读视图的服务消费。写侧(write-side)表可以表示面向领域的实体(domain-oriented entities),或者当CQRS和 Event Sourcing 结合的时候,写侧表仅仅用做追加操作命令事件的日志。
Debezium支持的数据库:
MySQL 5.7+、MongoDB、Postgres、Oracle、SQLServer、Cassandra、DB2、Vitess、Spanner
Debezium官方文档:
https://github.com/debezium/debezium
https://debezium.io/documentation/reference/2.1/tutorial.html