深拷贝和浅拷贝
这两个概念是在项目中比较常见的,在很多时候,都会遇到拷贝的问题,我们总是需要将一个对象赋值到另一个对象上,但可能会在改变新赋值对象的时候,忽略掉我是否之后还需要用到原来的对象,那么就会出现当改变新赋值对象的某一个属性时,也同时改变了原对象,此时我们就需要用到拷贝这个概念了。
深拷贝和浅拷贝的区别
1.浅拷贝: 将原对象或原数组的引用直接赋给新对象,新数组,新对象/数组只是原对象的一个引用
2.深拷贝: 创建一个新的对象和数组,将原对象的各项属性的“值”(数组的所有元素)拷贝过来,是“值”而不是“引用”
在这里,我们需要注意一点,那就是"引用"和"值"是什么,在学c的时候,涉及到了一个指针的概念,指针(Pointer)是编程语言中的一个对象,利用地址,它的值直接指向(points to)存在电脑存储器中另一个地方的值。由于通过地址能找到所需的变量单元,可以说,地址指向该变量单元。所以,这里的值就是对象的值,而引用就是指向存储这个值的地址。
那么这里我觉得稍微需要说一下堆栈和指针的关系了
当变量复制引用类型值的时候,同样和基本类型值一样会将变量的值复制到新变量上,不同的是对于变量的值,它是一个指针,指向存储在堆内存中的对象(JS规定放在堆内存中的对象无法直接访问,必须要访问这个对象在堆内存中的地址,然后再按照这个地址去获得这个对象中的值,所以引用类型的值是按引用访问)
图文说明:
1.基本类型---存储
2.基本类型---复制
3.引用类型---存储
如上图,引用类型在栈里面存储的是地址指针
4.引用类型---赋值
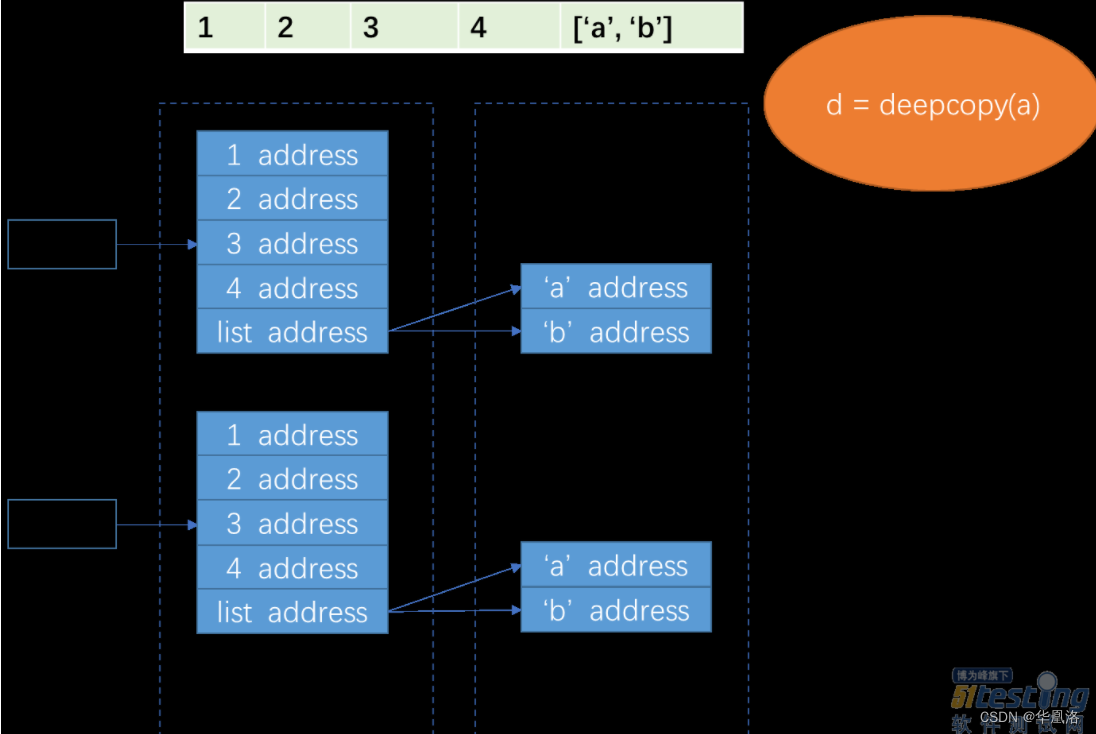
5.引用类型---拷贝
接下来说一下浅拷贝和深拷贝的方法(注意需要把拷贝和赋值区分开来,网上很多文章中都把赋值和浅拷贝混为一谈,那么这里理解起来是会自我矛盾的)
浅拷贝
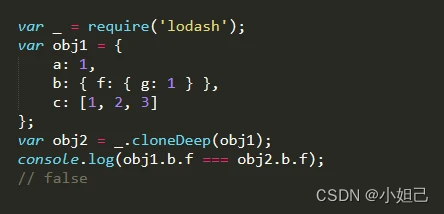
概念:创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址 ,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
思路:浅拷贝可以想做把引用类型的第一子级当作是每一个数据类型来赋值。例如:
let obj = {a: 1,b: {c: 2,}
} 那么obj的浅拷贝就可以看作是a赋值,b赋值。结合上图,那么当target浅拷贝obj时,那么target中的a会在栈内存中重新开辟空间存储值,由于b是引用类型,那么b还是存储地址,指向obj的b的值。
方法:
1.Object.assign()
定义:用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。
用法: Object.assign(target, ...sourceObj)
注意:
不会拷贝对象继承的属性、
不可枚举的属性、
属性的数据属性/访问器属性、
可以拷贝Symbol类型
2.拓展运算符(...)
用法:...object 3.Array.prototype.slice和Array.prototype.concat
用法:arrayObject.slice(start,end)、arrayObject.concat(arrayX,...,arrayX)
arrayObject.slice(start,end)
arrayObject.concat(arrayX,...,arrayX)
4.遍历
function deepClone(source) {if (!source || typeof source !== 'object') {return source;}const targetObj = source.constructor === Array ? [] : {};for (const keys in source) {if (source.hasOwnProperty(keys)) {targetObj[keys] = source[keys];}}return targetObj;
}
深拷贝:
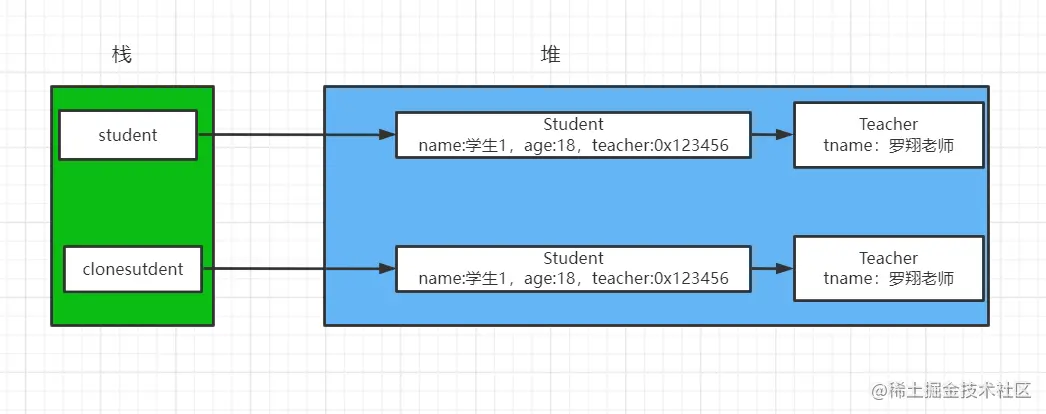
概念:将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放新对象,且修改新对象不会影响原对象
思路:通过上述浅拷贝的示例,可以看出,这些方法都只实现了对对象的第一层元素的拷贝,但是之后层的元素还是共享的,那么我们还是结合浅拷贝的思路,参考基本类型的赋值过程,来解决这个问题。
方法:
1.递归遍历
在浅拷贝的遍历方法上多加一层判断,进而对所有层级的元素进行遍历赋值
function deepClone(source) {if (!source || typeof source !== 'object') {return source;}const targetObj = source.constructor === Array ? [] : {};for (const keys in source) {if (source.hasOwnProperty(keys)) {if (source[keys] && typeof source[keys] === 'object') {targetObj[keys] = source[keys].constructor === Array ? [] : {};targetObj[keys] = deepClone(source[keys]);} else {targetObj[keys] = source[keys];}}}return targetObj;
}
2.JSON.parse(JSON.stringify(XXXX))
JSON.stringify方法是把对象转成字符串,返回新生成的字符串,这一步可以看作是,把目标对象转化成基础类型后,重新开辟一个新的区域存放转化后的字符串,然后在通过JSON.parse转成JSON格式,在赋给新的对象,这样操作新的对象就和目标对象毫无关系了
注意:
1.拷贝的对象的值中如果有函数,undefined,symbol类型,不会转换,而是丢弃
2.无法拷贝不可枚举的属性,无法拷贝对象的原型链
3.拷贝Date引用类型会变成字符串
4.拷贝RegExp引用类型会变成空对象
5.对象中含有NaN、Infinity和-Infinity,则序列化的结果会变成null
6.无法拷贝对象的循环应用(即obj[key] = obj)
参考文章:
https://www.jianshu.com/p/c651aeabf582
https://blog.csdn.net/weixin_41910848/article/details/82144671