深拷贝和浅拷贝(copy和deepcopy)详解
- 详细解释
- 存储方式
- 列表的增删改
- 列表修改已有值
- 列表新增一个值
- 列表整体重新赋值
- copy与deepcopy的区别
- 不可变类型
- 可变类型
浅拷贝指的是创建一个新对象,其中包含原始对象的引用(指针),并没有真正将原始对象的数据复制到新对象中,因此新对象与原始对象共享部分或全部数据。
深拷贝指的是创建一个新对象,并递归地将原始对象的数据复制到新对象中,因此新对象与原始对象之间不存在数据共享。
区别:
- 对于不可变对象,浅拷贝和深拷贝没有区别,因为不可变对象的数据是无法被修改的,因此不存在共享数据的问题;
- 对于可变对象,浅拷贝会创建一个新对象,其中包含原始对象的引用,因此新对象与原始对象共享数据;而深拷贝会递归地创建新对象,并将原始对象的数据复制到新对象中,因此新对象与原始对象之间不存在数据共享。
import copy# a = () # 不可变类型
a = [] # 可变类型
print(id(a))
aa = copy.copy(a)
print(id(aa))
aaa = copy.deepcopy(a)
print(id(aaa))
详细解释
存储方式
首先了解一下Python的变量在内存中的存储方式。在基本数据类型中(包括set、list(tuple, str)、dict)都是采用引用的方式。
也就是说,每个变量都存储的是这个变量的地址,而不是值本身,就算更复杂的嵌套结构,也是存储是每个元素的地址而已,用一幅图来表示。
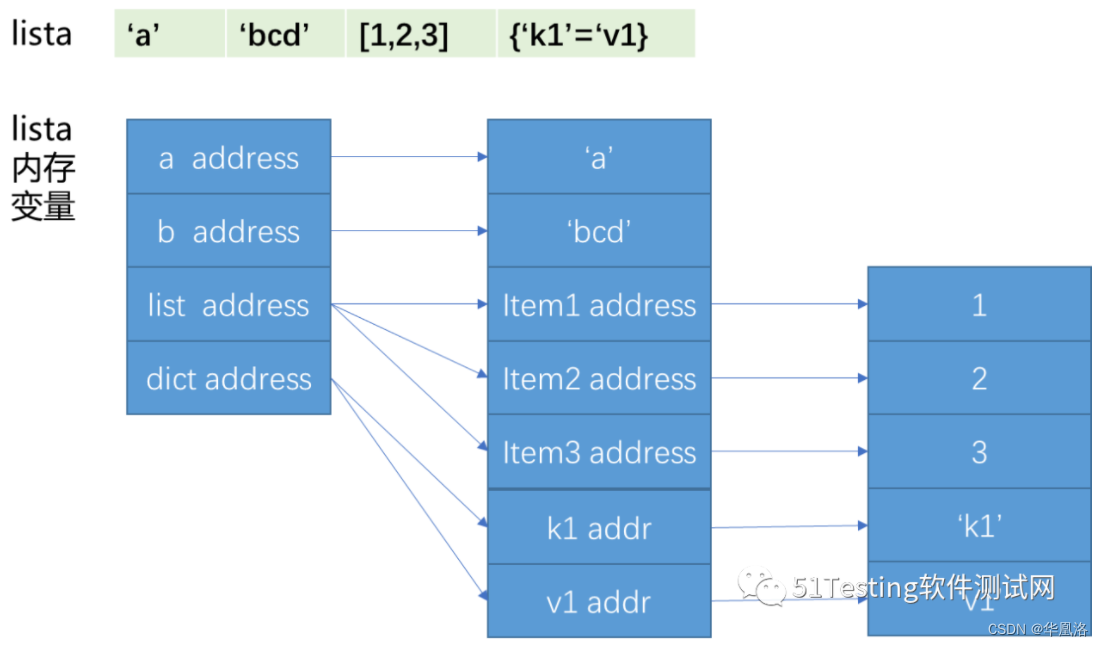
如上图所示,用户看到的是 lista的4个元素值,但是内存中保存的却是4个元素地址。
当元素是列表时,第一层保存的是列表的地址,第二层保存的是列表元素的地址,第三层才是列表的值。当元素是字典的时候,与列表类似。
列表的增删改
在明白了变量存储方式后,继续看下内存下的增删改是怎么变化的。
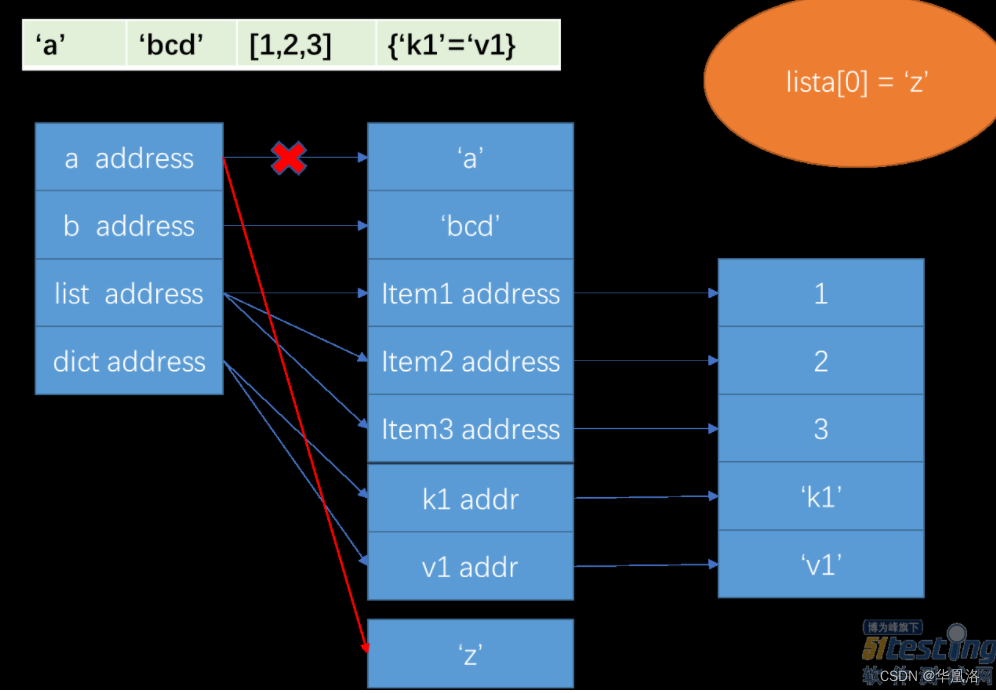
列表修改已有值
新增一个内存块,再将引用的地址修改为新内存块的地址。
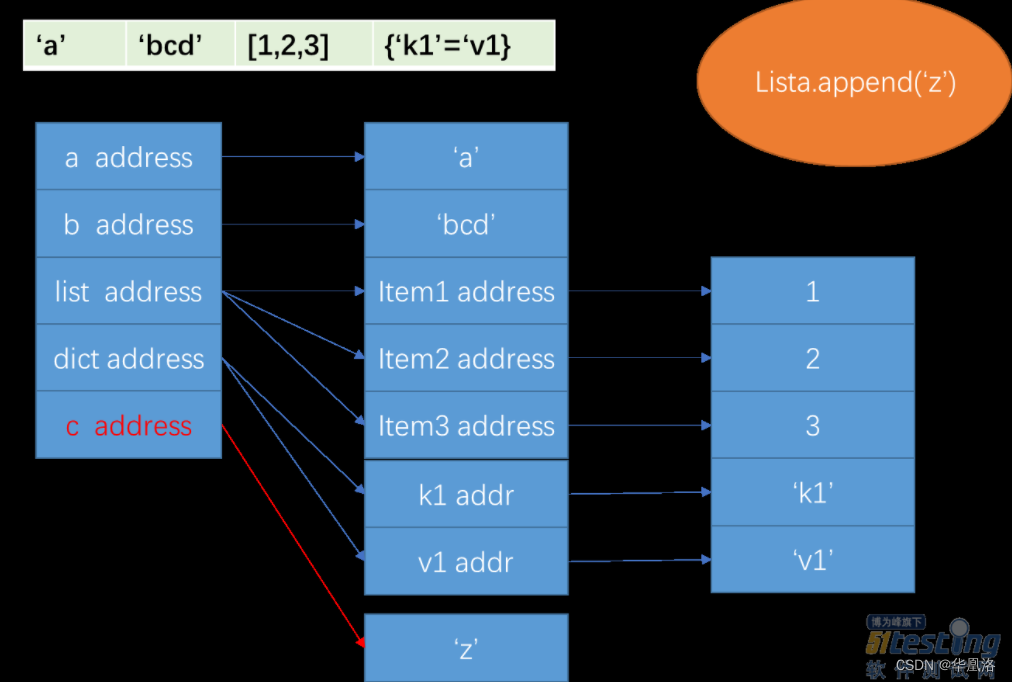
列表新增一个值
新增一个内存块,新增一个地址引用。
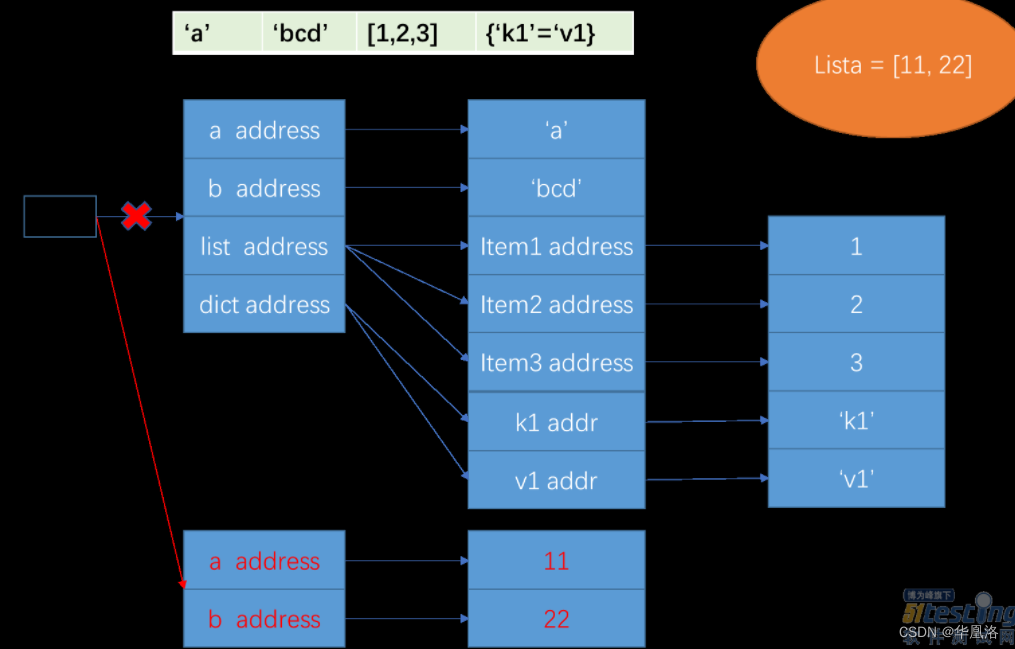
列表整体重新赋值
删除变量地址和引用的值,新增地址和引用值的内存块。
copy与deepcopy的区别
- copy:不管多么复杂的数据结构,浅拷贝都只会copy第一层。
- deepcopy:拷贝全部数据,将整个变量内存全部复制一遍,新变量与原变量没有任何关系。
举例:
import copya = [1, 2, 3, 4, ['a', 'b']]
b = a
c = copy.copy(a)
d = copy.deepcopy(a)a.append(5)
a[1] = 20
a[4].append('c')
del a[0]print(a) # [20,3,4,['a','b','c'],5]
print(b) # [20,3,4,['a','b','c'],5]
print(c) # [1,2,3,4,['a','b','c']]
print(d) # [1,2,3,4,['a','b']]
列表b:
表示b也引用的a的地址,两者引用的内存地址是一样的。因此b和a的关系是紧密相连的,一模一样。可以通过 id(a) 和id(b)比较,两者是一样的。
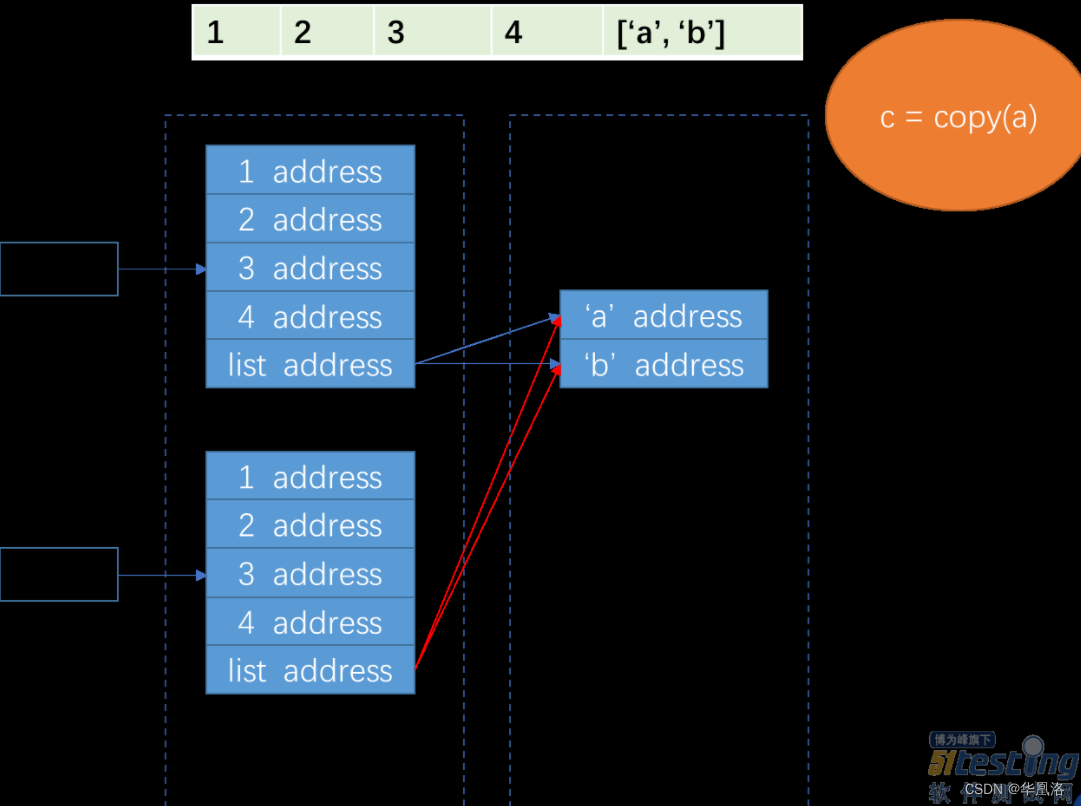
列表c:
由于c是浅拷贝的a列表,因此只copy了第一层,也就是地址层。所以,
- 当a.append(5)时,新增了一个内存块,但是c只有前5个内存块,因此c没有变化。
- 继续a修改了a[1],然而这个值是属于第一层,已经copy给了c,因此c也没有变化。
- 继续a修改了子列表,这个时候a复制给c的只是列表的地址,且a中的子列表地址和c中的子列表地址是指向同一个地方的,因此修改了a中子列表,c中的子列表也会相应的改变。
- 最后删除a[0],与修改a[1]一致,与c无关。可以用图再说明一下。
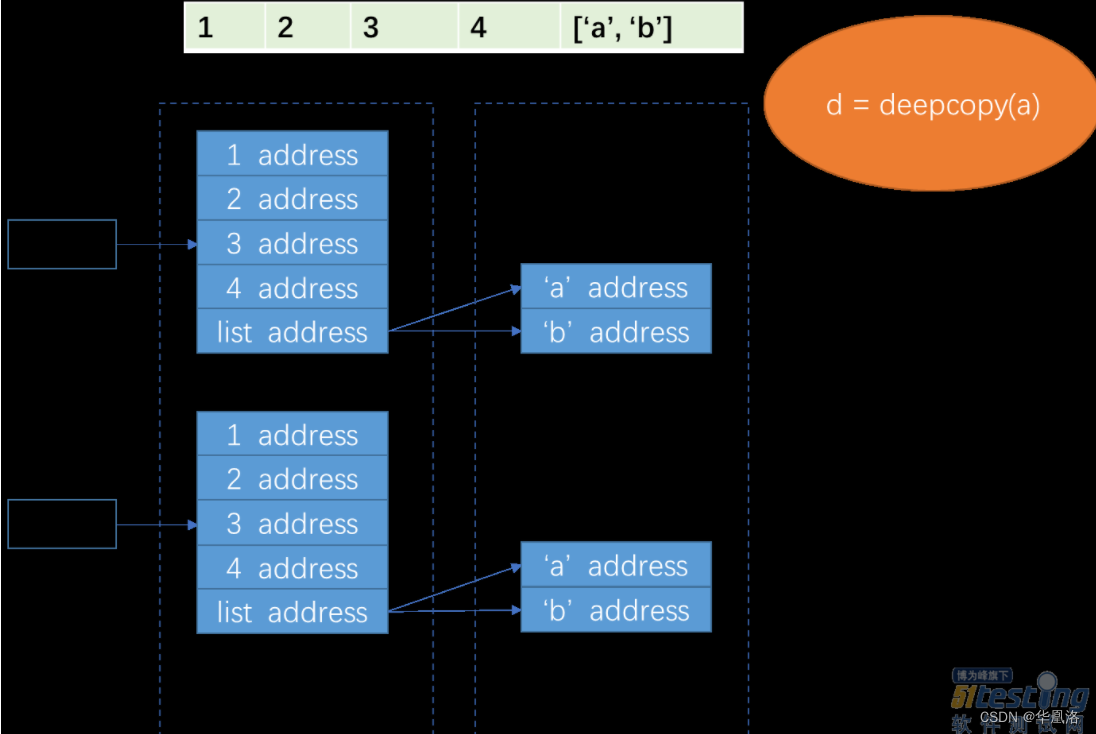
列表d:
由于d是深拷贝的a列表,因此d是将a的地址和值一并复制过来,与a没有半点关系,也就是说d和a是两个完全独立的内存块,没有任何交集。因此,后面a的任意修改都与d无关。
不可变类型
在 Python 中,不可变类型是指一旦创建就不能修改其值的数据类型。Python 中常见的不可变类型包括:
- 数值类型(int、float、complex);
- 字符串类型(str);
- 元组类型(tuple);
- 布尔类型(bool)。
不可变类型的特点是一旦创建,其值就不可被修改。因此,对于不可变类型的操作通常都是创建新的对象,并返回其引用,而不是修改原来的对象。
可变类型
在 Python 中,可变类型是指其值可以被修改的数据类型。Python 中常见的可变类型包括:
- 列表类型(list);
- 字典类型(dict);
- 集合类型(set)。
可变类型的特点是其值可以被修改。因此,对于可变类型的操作通常都是在原对象上进行修改,而不是创建新的对象。
参考: