目录
数据结构中的堆、栈和队列
内存申请中的堆和栈
一个C/C++程序占用的内存如下:
申请内存后的响应
申请大小的限制
申请效率的比较
堆和栈中的存储内容
数据结构中的堆、栈和队列
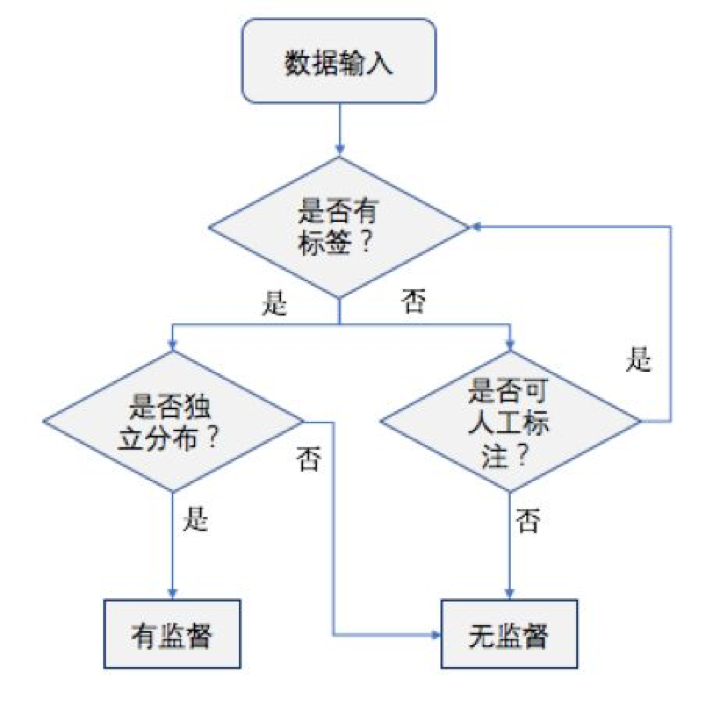
堆:堆是一种经过排序的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。由于堆的这个特性,常用来实现优先队列,堆的存取是随意,这就如同我们在图书馆的书架上取书,虽然书的摆放是有顺序的,但是我们想取任意一本时不必像栈一样,先取出前面所有的书,书架这种机制不同于箱子,我们可以直接取出我们想要的书。
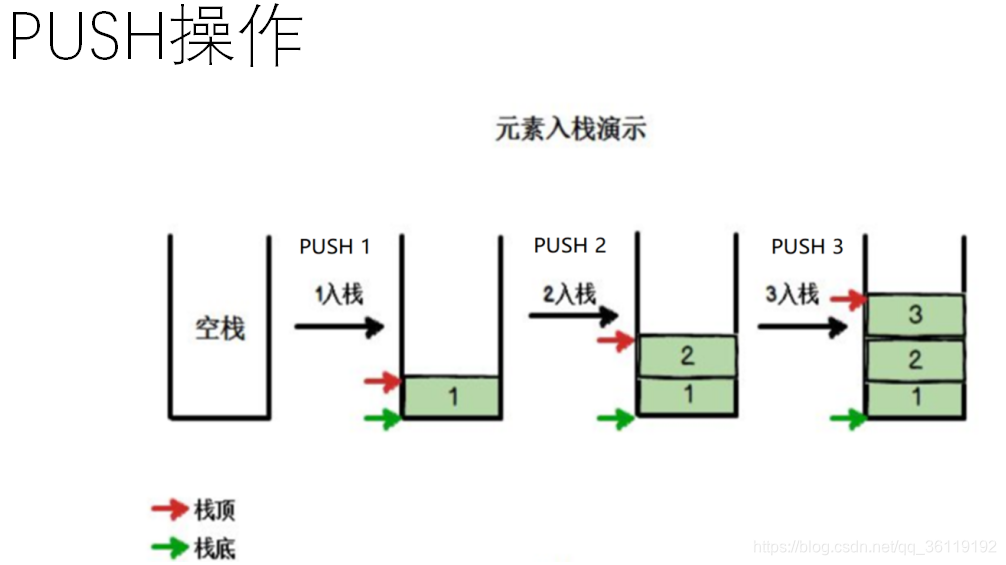
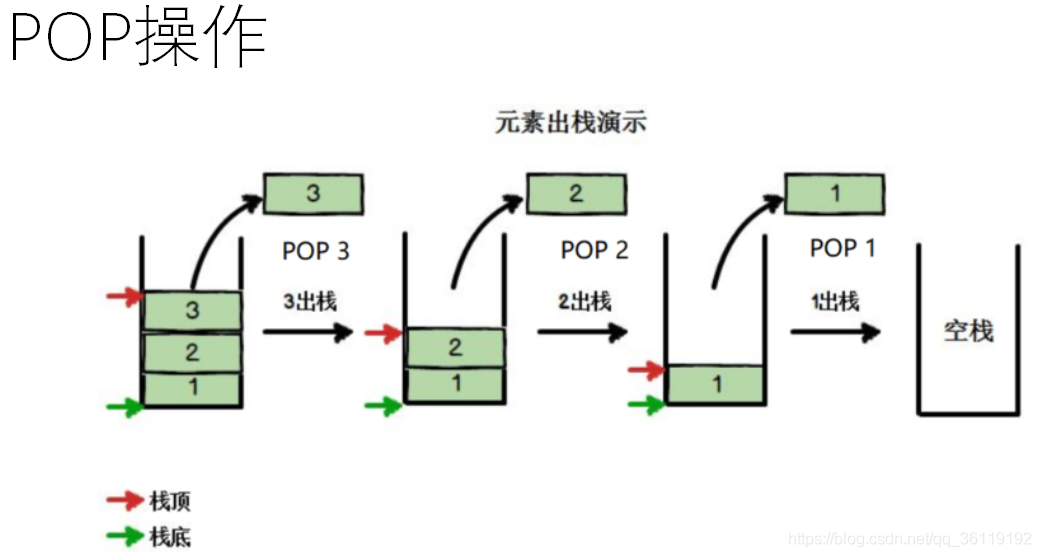
栈:又名堆栈,是一种运算受限的线性表。只允许在栈顶插入和删除元素。栈顶是低位,栈底是高位。栈中没有元素时称为空栈,栈符合先进后出原则(LIFO,last in first out)。
实质:线性表
操作: push 、pop
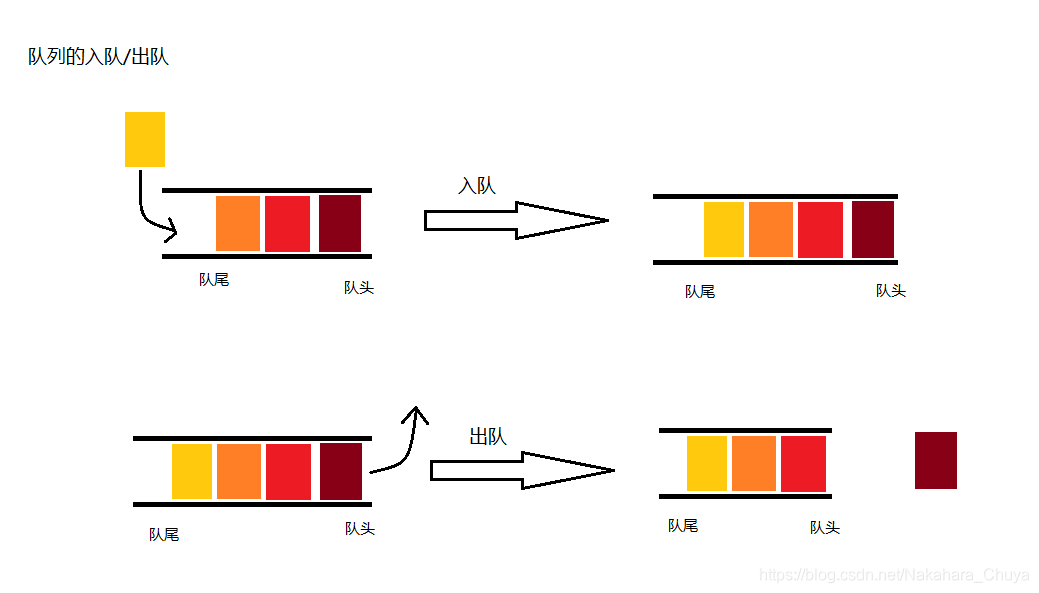
队列:也是一种运算受限的线性表。 特殊之处在于它只允许在队列的前端(front,队头)进行删除操作,而在队列的后端(rear,队尾)进行插入操作。当队列中没有元素时,即front=rear,称为空队列。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。队列符合先进先出(FIFO—first in first out)原则
实质:线性表

内存申请中的堆和栈
堆:堆是在程序运行时,而不是在程序编译时,申请的某个大小的内存空间。即动态分配的内存,对其访问和对一般内存的访问没有区别。堆是应用程序在运行的时候请求操作系统分配给自己的内存,一般是申请/给予的过程,一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收
栈:由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈
作用:暂时存储数据的地方,用来在函数调用的时候存储断点
栈在程序的运行中有着举足轻重的作用。最重要的是栈保存了一个函数调用时所需要的维护信息,这常常称之为堆栈帧或者活动记录。堆栈帧一般包含如下几方面的信息:
1.函数的返回地址和参数
2.临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量。
内存中的栈区处于相对较高的地址。如果以地址的增长方向为上的话,栈地址是向下增长的,栈中分配局部变量空间。而堆区是向上增长的用于分配程序员申请的内存空间。另外还有静态区是分配静态变量,全局变量空间的;只读区是分配常量和程序代码空间的;以及其他一些分区。

一个C/C++程序占用的内存如下:
1、栈区(stack):由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事
3、全局区、静态区(static):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后由系统释放
4、文字常量区:常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区:存放函数体的二进制代码。
#include <stdio.h>
#include <stdlib.h>
int a=0; //可读写区:全局变量
void main(){char*d="123456"; //栈区:系统自动分配的static int e=0; //可读写去:静态变量char*p1=(char*)malloc(10); //堆区:程序员申请的const float PI=3.1415; //只读区:常量
} 申请内存后的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时, 会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
申请大小的限制
栈:在Windows中,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
申请效率的比较
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。