微信公众号:运维开发故事,作者:夏老师
Part1架构概述
从系统架构来看,目前的商用服务器大体可以分为三类
-
对称多处理器结构(SMP:Symmetric Multi-Processor)
-
非一致存储访问结构(NUMA:Non-Uniform Memory Access)
-
海量并行处理结构(MPP:Massive Parallel Processing)。
共享存储型多处理机有两种模型
-
均匀存储器存取(Uniform-Memory-Access,简称UMA)模型
-
非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型
多核系统的存储结构
根据多核处理器内的cache配置情况,可以把多核处理器的组织结构分成以下四种:
- 片内私有L1 cache结构:简单的多核计算机的cache结构由L1和L2两级组成。处理器片内的多个核各自有自己私有的L1 cache,一般被划分为指令L1(L1-I)cache和数据L1(L1-D)cache。而多核共享的L2 cache则存在于处理器芯片之外。
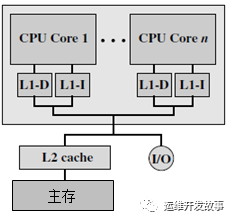
image.png
- 片内私有L2 cache结构:处理器片内的多个核仍然保留自己私有的指令L1 cache和数据L1 cache,但L2 cache被移至处理器片内,且L2 cache为各个核私有。多核共享处理器芯片之外的主存。
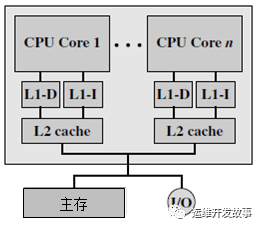
image.png
- 片内共享L2 cache结构:结构与片内私有L2 cache的多核结构相似,都是片上两级cache结构。不同之处在于处理器片内的私有L2 cache变为多核共享L2 cache。多核仍然共享处理器芯片之外的主存。对处理器的每个核而言,片内私有L2 cache的访问速度更高。但在处理器片内使用共享的L2 cache取代各个核私有的L2 cache能够获得系统整体性能的提升。
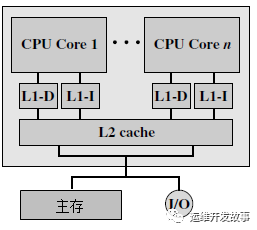
image.png
- 片内共享L3 cache结构:随着处理器芯片上的可用存储器资源的增长,高性能的处理器甚至把L3 cache也从处理器片外移至片内。在片内私有L2 cache结构的基础上增加片内多核共享L3 cache使存储系统的性能有了较大提高。下图给出了这种结构的示意。
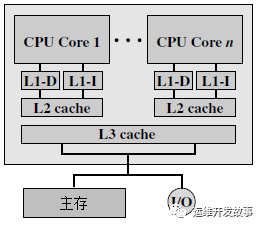
image.png
存取速度比较:L1缓分成两种,一种是指令缓存,一种是数据缓存。L2缓存和L3缓存不分指令和数据。L1和L2缓存在第一个CPU核中,L3则是所有CPU核心共享的内存。L1、L2、L3的越离CPU近就越小,速度也越快,越离CPU远,速度也越慢。再往后面就是内存,内存的后面就是硬盘。我们来看一些他们的速度:
-
L1 的存取速度:4 个CPU时钟周期
-
L2 的存取速度:11 个CPU时钟周期
-
L3 的存取速度:39 个CPU时钟周期
-
RAM内存的存取速度 :107 个CPU时钟周期
多核处理器的核间通信机制
多核处理器片内的多个处理器内核虽然各自执行各自的代码,但是处理器内核之间需要进行数据的共享和同步,因此多核处理器硬件结构必须支持高效的核间通信,片上通信结构的性能也将直接影响处理器的性能
1)总线共享Cache结构
-
总线共享Cache结构是指多核处理器内核共享L2 Cache或L3 Cache,片上处理器内核、输入/输出接口以及主存储器接口通过连接各处理器内核的总线进行通信。
-
这种方式的优点是结构简单、易于设计实现、通信速度高,但缺点是总线结构的可扩展性较差,只适用于处理器核心数较少的情况。
2)交叉开关互连结构
-
传统的总线结构采用分时复用的工作模式,因而在同一总线上同时只能进行一个相互通信的过程。而交叉开关(Crossbar Switch)互连结构则能够有效提高数据交换的带宽。
-
交叉开关是在传统电话交换机中沿用数十年的经典技术,它可以按照任意的次序把输入线路和输出线路连接起来。
3)片上网络结构
-
片上网络(Network on a Chip,NoC;On-chip Network)技术借鉴了并行计算机的互连网络结构,在单芯片上集成大量的计算资源以及连接这些资源的片上通信网络。每个处理器内核具有独立的处理单元及其私有的Cache,并通过片上通信网络连接在一起,处理器内核之间采用消息通信机制,用路由和分组交换技术替代传统的片上总线来完成通信任务,从而解决由总线互连所带来的各种瓶颈问题。
-
片上网络与传统分布式计算机网络有很多相似之处,但限于片上资源有限,设计时要考虑更多的开销限制,针对延时、功耗、面积等性能指标进行优化设计,为实现高性能片上系统提供高效的通信支持。
多核处理器的Cache一致性
在多核系统设计时必须考虑多级Cache的一致性(Cache Coherency)问题。对内存的基本操作包括读操作和写操作。Cache一致性问题产生的原因是:
-
在一个处理器系统中,不同的Cache和主存空间中可能存放着同一个数据的多个副本,在写操作时,这些副本存在着潜在的不一致的可能性。
-
在单处理器系统中,Cache一致性问题主要表现为在内存写操作过程中如何保持各级Cache中的数据副本和主存内容的一致,即使有I/O通道共享Cache,也可以通过全写法较好地解决Cache一致性问题。
-
而在多核系统中,多个核都能够对内存进行写操作,而Cache级数更多,同一数据的多个副本可能同时存放在多个Cache存储器中,某个核的私有Cache又只能被该核自身访问。即使采用全写法,也只能维持一个Cache和主存之间的一致性,不能自动更新其他处理器内核的私有Cache中的相同副本。这些因素无疑加大了Cache一致性问题的复杂度,同时又影响着多核系统的存储系统整体设计。
维护Cache一致性的关键在于跟踪每一个Cache块的状态,并根据处理器的读写操作及总线上的相应事件及时更新Cache块的状态。一般来说,导致多核处理器系统中Cache内容不一致的原因如下:(1)可写数据的共享:某个处理器采用全写法或写回法修改某一个数据块时,会引起其他处理器的Cache中同一副本的不一致。(2)I/O活动:如果I/O设备直接连接在系统总线上,I/O活动也会导致Cache不一致。(3)核间线程迁移:核间线程迁移就是把一个尚未执行完的线程调度到另一个空闲的处理器内核中去执行。为提高整个系统的效率,有的系统允许线程核间迁移,使系统负载平衡。但这有可能引起Cache的不一致。对于I/O活动和核间线程迁移而导致的Cache不一致,可以分别通过禁止I/O通道与处理器共享Cache以及禁止核间线程迁移简单解决。因而多处理器中的Cache一致性问题主要是针对可写数据的共享。
UMA(Uniform-Memory-Access)与 SMP (Symmetric Multi-Processor)
所谓对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此UMA也被称为对称多处理器结构(SMP:Symmetric Multi-Processor)。对UMA服务器进行扩展的方式包括增加内存、使用更快的CPU、增加CPU、扩充I/O(槽口数与总线数)以及添加更多的外部设备(通常是磁盘存储)。
在对称多处理器架构下,系统中的每个处理器内核地位相同,其看到的存储器和共享硬件也都是相同的。在UMA架构的多处理器系统中,所有的处理器都访问一个统一的存储器空间,这些存储器往往以多通道的方式组织。在UMA架构下,所有的内存访问都被传递到相同的共享内存总线上,不同的处理器访问存储器的延迟时间相同,任何一个进程或线程都可以被分配到任何一个处理器上运行。每个处理器还可以配备私有的Cache,外围设备也可以通过某种形式共享。因而UMA架构可以在操作系统的支持下达到非常好的负载均衡效果,让整个系统的性能、吞吐量有较大提升。
但从存储器访问的角度看,对称多处理器架构的缺点是可伸缩性较差。这是因为多个核使用相同的总线访问内存,随着处理器内核数的增加,总线将成为系统性能提升的瓶颈。因而UMA架构只适用于处理器内核数量相对较少的情况,不适用于系统中配置数十个甚至数百个处理器内核的情况。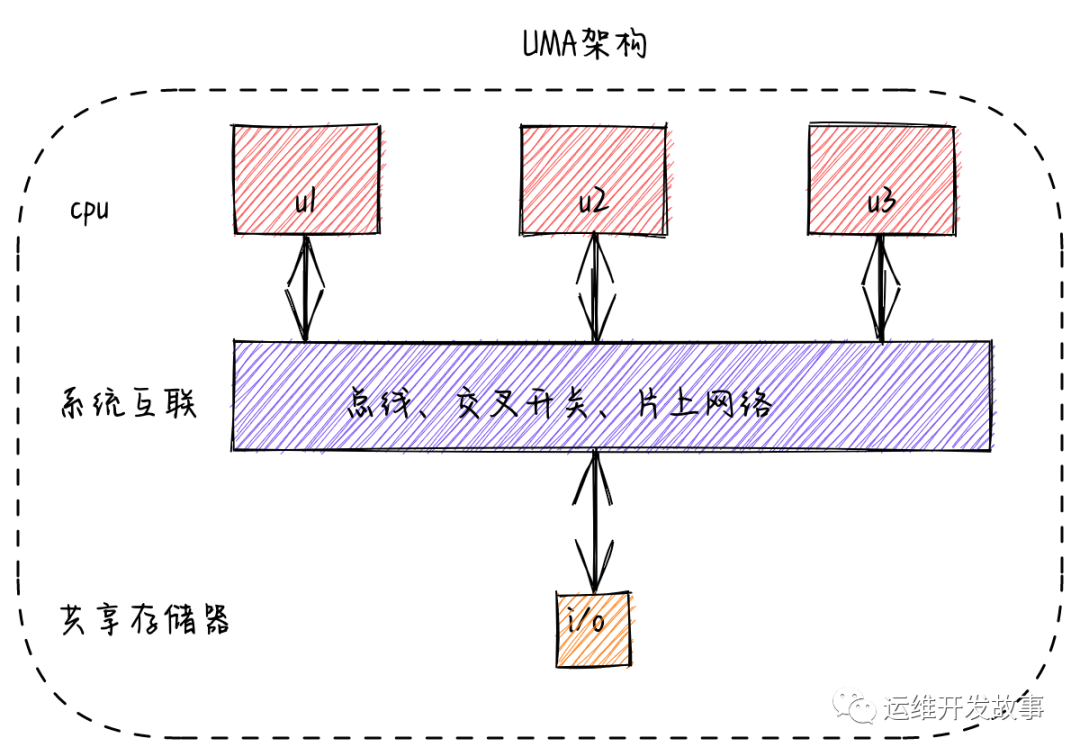
NUMA(Non-Uniform Memory Access)
NUMA 的主要优点是伸缩性。NUMA 体系结构在设计上已超越了 SMP 体系结构在伸缩性上的限制。通过 SMP,所有的内存访问都传递到相同的共享内存总线。这种方式非常适用于 CPU 数量相对较少的情况,但不适用于具有几十个甚至几百个 CPU 的情况,因为这些 CPU 会相互竞争对共享内存总线的访问。NUMA 通过限制任何一条内存总线上的 CPU 数量并依靠高速互连来连接各个节点,从而缓解了这些瓶颈状况。
系统内的存储器访问延时从高到低依次为:跨CPU访存、不跨CPU但跨NUMA域访存、NUMA域内访存。因此,在应用程序运行时应尽可能避免跨NUMA域访问存储器,这可以通过设置线程的CPU亲和性(affinity)来实现。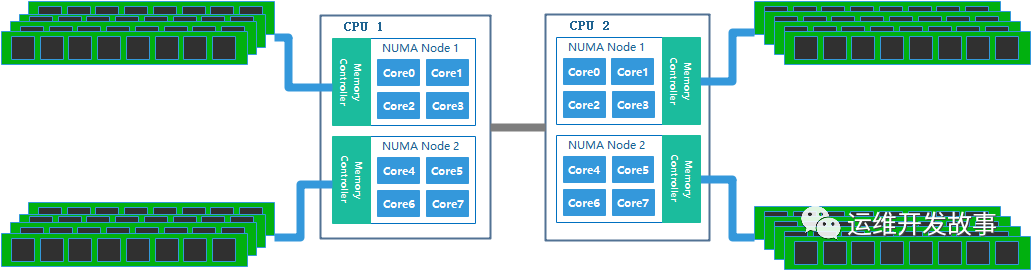
NUMA架构既可以保持对称多处理器架构的单一操作系统、简便的应用程序编程模式及易于管理的特点,又可以有效地扩充系统的规模。NUMA架构能够为处理器访问本地存储器单元提供高速互连机制,同时为处理器访问远程存储器单元提供较为经济但延迟时间更高的连接通道,因而NUMA架构的系统通常比UMA架构的系统更加经济且性能更强大。
CC-NUMA(CacheCoherentNon-UniformMemoryAccess)
在NUMA架构中,有一种类型应用特别普遍,即CC-NUMA(Cache Coherent Non-Uniform Memory Access,缓存一致性非统一内存访问)系统。缓存一致性问题是由于多个处理器共享同一个存储空间而引起的,而CC-NUMA是指通过专门的硬件保持Cache中的数据和共享内存中的数据的一致性,不需要软件来保持多个数据副本之间的一致性。当某个存储单元的内容被某个处理器改写后,系统可以很快地通过专用硬件部件发现并通知其他各个处理器。因此。在CC-NUMA系统中,分布式内存储器被连接为单一内存空间,多个处理器可以在单一操作系统下使用与对称多处理器架构中一样的方式完全在硬件层次实现管理。
- Directory 协议 。这种方法的典型实现是要设计一个集中式控制器,它是主存储器控制器的一部分。其中有一个目录存储在主存储器中,其中包含有关各种本地缓存内容的全局状态信息。当单个CPU Cache 发出读写请求时,这个集中式控制器会检查并发出必要的命令,以在主存和CPU Cache之间或在CPU Cache自身之间进行数据同步和传输。
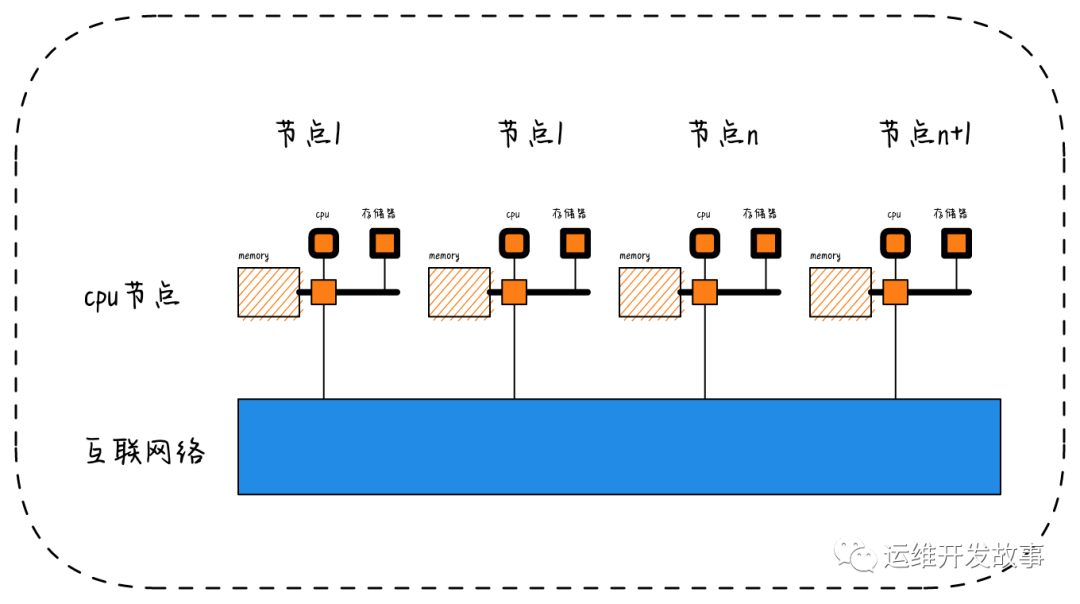
numa.png
- Snoopy 协议 。这种协议更像是一种数据通知的总线型的技术。CPU Cache通过这个协议可以识别其它Cache上的数据状态。如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它CPU Cache。这个协议要求每个CPU Cache 都可以 “窥探” 数据事件的通知并做出相应的反应。
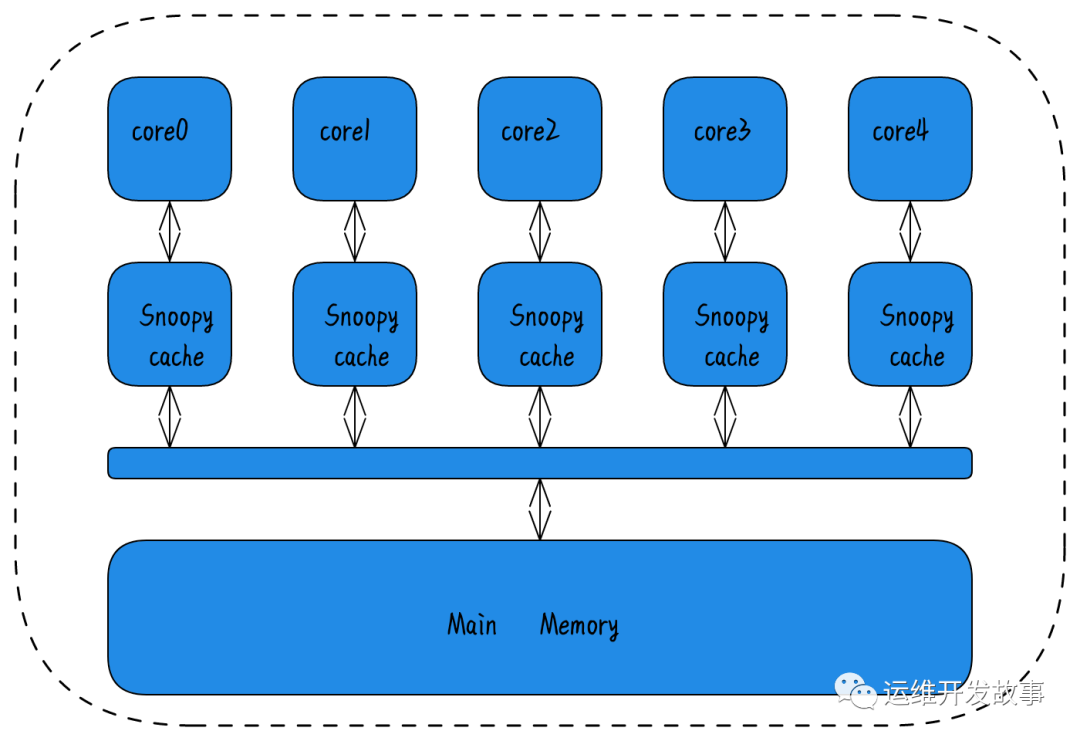 由于 snooping 使用了广播会占用总线带宽,一般认为 snooping 扩展性不如 directory-based,但是在带宽足够的前提下,snooping 会更快。
由于 snooping 使用了广播会占用总线带宽,一般认为 snooping 扩展性不如 directory-based,但是在带宽足够的前提下,snooping 会更快。
预告
下一节,我们将聊聊linux上numa架构的一些知识。