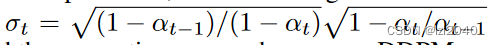前言
在训练VAE模型时,当我们使用过于过于强大的decoder时,尤其是自回归式的decoder比如LSTM时,存在一个非常大的问题就是,decoder倾向于不从latent variable z中学习,而是独立地重构数据,这个时候,同时伴随着的就是KL(p(z|x)‖q(z))倾向于0。先不考虑说,从损失函数的角度来说,这种情况不是模型的全局最优解这个问题(可以将其理解为一个局部最优解)。单单从VAE模型的意义上来说,这种情况也是我们不愿意看到的。VAE模型的最重要的一点就是其通过无监督的方法构建数据的编码向量(即隐变量z)的能力。而如果出现posterior collapse的情况,就意味着后验概率退化为与先验概率一致,即N(0,1)。此时encoder的输出近似于一个常数向量,不再能充分利用输入x的信息。decoder则变为了一个普通的language model,尽管它依然很强。
因此,不管从哪个方面来看,解决它都是必须要面临的课题,事实上,从2016年开始就有很多文章提出了不同的解决方案,这里重点介绍一下使用Batch Normalization来解决这个问题的思路。这篇文章全名A Batch Normalized Inference Network Keeps the KL Vanishing Away发表于2020年,还算是一篇比较新的文章。下面我们开始。
方法介绍
Expectation of the KL’s Distribution
首先基于隐变量空间为高维高斯分布的假设,对于一个mini-batch的数据来说,我们可以计算KL divergence的表达式如下:

其中b代表的是mini-batch的样本个数,n代表的隐变量z的维度。同时作者还假设对于每个不同的维度,其都遵循某个特定的分布,各个维度可以不同。
假设我们认为上述的样本均值可以近似等于总体期望,那么我们可以将上述的样本均值用期望来代替,又因为我们有如下基本等式

最终我们可以得到KL divergence的期望表达式如下。

上述不等式是因为e^x-x>=1恒成立。那么这么一来,我们就有关于KL divergence的一个lower bound。这个lower bound只与隐变量的维度n和μi的分布有关。
Normalizing Parameters of the Posterior
接下来,我们要考虑的问题就是如何来构建每个μi的分布,使其保证这个lower bound的值恒为正,也就间接保证了KL divergence不会变为0。这里用到的方法就是Batch Normalization。
我们熟知的Batch Normalization往往用在神经网络模型中,通过控制每个隐藏层的数据的分布使得训练更加平稳。
但是在这里我们使用它来转换μi的分布,将其控制在一个合理的范围内,从而保证lower bound的值为正。具体如下

其中μBi 和 σBi 分别表示通过mini-batch计算的 μi的均值和标准差。γ 和 β分别是scale和shift参数。通过合理地控制这两个参数,我们可以将lower bound近似地转换为如下式子。

下面是完整的算法流程。

在原文中还有涉及到对参数设置的进一步拓展,大家可以参考苏剑林老师的这篇博客
Torch 实现
在苏剑林老师的博客中,他用keras实现了文章中的关键内容,在这里,我用torch实现了一下,供大家参考。
import torch
import torch.nn as nn# reference paper:https://arxiv.org/abs/2004.12585
class BN_Layer(nn.Module):def __init__(self,dim_z,tau,mu=True):super(BN_Layer,self).__init__()self.dim_z=dim_zself.tau=torch.tensor(tau) # tau : float in range (0,1)self.theta=torch.tensor(0.5,requires_grad=True)self.gamma1=torch.sqrt(self.tau+(1-self.tau)*torch.sigmoid(self.theta)) # for muself.gamma2=torch.sqrt((1-self.tau)*torch.sigmoid((-1)*self.theta)) # for varself.bn=nn.BatchNorm1d(dim_z)self.bn.bias.requires_grad=Falseself.bn.weight.requires_grad=Trueif mu:with torch.no_grad():self.bn.weight.fill_(self.gamma1)else:with torch.no_grad():self.bn.weight.fill_(self.gamma2)def forward(self,x): # x:(batch_size,dim_z)x=self.bn(x)return x参考
A Batch Normalized Inference Network Keeps the KL Vanishing Away
变分自编码器(五):VAE + BN = 更好的VAE