@创建于:20210708
@修改于:20210708, 20221104
文章目录
- 1 概述
- 2 方法介绍
- 2.1 安装
- 2.2 KeyBERT(model)
- 2.3 extract_keywords参数介绍
- 3、代码实践
- 3.1 英文示例
- 3.2 中文示例
- 4、加载不同的模型库
- 4.1 SentenceTransformers模型调用
- 4.2 Transformers模型调用
- 4.3 Flair模型调用
- 5、ZhKeyBERT的使用
- 5.1 安装
- 5.2 使用
- 6、参考链接
1 概述
KeyBERT 是一种最小且易于使用的关键字提取技术,它利用 BERT 嵌入来创建与文档最相似的关键字和关键短语。可以在此处找到相应的媒
虽然已经有很多方法可用于关键字生成(例如,Rake、YAKE!、TF-IDF 等),但我想创建一个非常基本但功能强大的方法来提取关键字和关键短语。这就是 KeyBERT 的用武之地!它使用 BERT 嵌入和简单余弦相似度来查找文档中与文档本身最相似的子短语。
首先,使用 BERT 提取文档嵌入以获得文档级表示。然后,然后使用词嵌入模型来提取N-gram 词/短语。最后,使用余弦相似度来找到与文档最相似的单词/短语。然后可以将最相似的词识别为最能描述整个文档的词。
KeyBERT 绝不是独一无二的,它是作为创建关键字和关键短语的一种快速简便的方法而创建的。尽管有很多优秀的论文和解决方案使用了 BERT 嵌入(例如 BERT-keyphrase-extraction, BERT-Keyword-Extractor ),但我找不到一个基于 BERT 的解决方案,它不需要从头开始训练并且可以用于初学者(如我错了请纠正我!)。因此,目标是 pip install keybert 和最多使用 3 行代码。
2 方法介绍
2.1 安装
pip install keybert
2.2 KeyBERT(model)
# 该模型只有一个参数,model,默认为 'paraphrase-MiniLM-L6-v2'
__init__(self, model='paraphrase-MiniLM-L6-v2')
# 可以自己设定具体的模型名称
kw_model = KeyBERT(model="paraphrase-multilingual-MiniLM-L12-v2")KeyBERT的参数只有一个,即预训练好的模型。
KeyBERT 0.4.0中,model默认的是 paraphrase-MiniLM-L6-v2,
KeyBERT 0.6.0中,model默认的是 all-MiniLM-L6-v2
Transformers库中的模型,在 keybert==0.6.0版本支持,0.4.0中不支持。
def __init__(self, model="all-MiniLM-L6-v2"):"""KeyBERT initializationArguments:model: Use a custom embedding model.The following backends are currently supported:* SentenceTransformers* 🤗 Transformers* Flair* Spacy* Gensim* USE (TF-Hub)You can also pass in a string that points to one of the followingsentence-transformers models:* https://www.sbert.net/docs/pretrained_models.html"""
2.3 extract_keywords参数介绍
extract_keywords(self,docs: Union[str, List[str]],candidates: List[str] = None,keyphrase_ngram_range: Tuple[int, int] = (1, 1),stop_words: Union[str, List[str]] = 'english',top_n: int = 5,min_df: int = 1,use_maxsum: bool = False,use_mmr: bool = False,diversity: float = 0.5,nr_candidates: int = 20,vectorizer: CountVectorizer = None,highlight: bool = False)
提示:
建议迭代单个文档,因为它们需要最少的内存。即使速度较慢,您也不太可能遇到内存错误。
多个文件:
有一个选项可以为多个文档提取关键字,这比提取多个单个文档要快。但是,这种方法假设您可以将词汇表中所有单词的词嵌入保留在内存中,这可能会很麻烦。如果您的硬件有限,我建议不要使用此选项并简单地迭代文档。
参数:
- docs:要提取关键字/关键短语的文档
- candidates:要使用的候选关键字/关键短语,而不是从文档中提取它们
- keyphrase_ngram_range:提取的关键字/关键短语的长度(以字为单位)
- stop_words:要从文档中删除的停用词
- top_n:返回前 n 个关键字/关键短语
- min_df:如果需要提取多个文档的关键字,则一个单词在所有文档中的最小文档频率
- use_maxsum: 是否使用 Max Sum Similarity 来选择keywords/keyphrases
- use_mmr:是否使用最大边际相关性(MMR)进行关键字/关键短语的选择
- diversity:如果 use_mmr 设置为 True,结果的多样性在 0 和 1 之间
- nr_candidates:如果 use_maxsum 设置为 True,要考虑的候选数
- vectorizer:从 scikit-learn 传入你自己的 CountVectorizer
- highlight:是否打印文档并突出显示其关键字/关键短语。注意:如果传递了多个文档,这将不起作用。
返回:
关键字:文档的前 n 个关键字及其各自的距离到输入文件
3、代码实践
3.1 英文示例
from keybert import KeyBERTdoc = """Supervised learning is the machine learning task of learning a function thatmaps an input to an output based on example input-output pairs. It infers afunction from labeled training data consisting of a set of training examples.In supervised learning, each example is a pair consisting of an input object(typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a 'reasonable' way (see inductive bias)."""kw_model = KeyBERT(model='paraphrase-MiniLM-L6-v2')print("naive ...")
keywords = kw_model.extract_keywords(doc)
print(keywords)print("\nkeyphrase_ngram_range ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(1, 2), stop_words=None)
print(keywords)print("\nhighlight ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(1, 2), highlight=True)
print(keywords)# 为了使结果多样化,我们将 2 x top_n 与文档最相似的词/短语。
# 然后,我们从 2 x top_n 单词中取出所有 top_n 组合,并通过余弦相似度提取彼此最不相似的组合。
print("\nuse_maxsum ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(1, 3), stop_words='english',use_maxsum=True, nr_candidates=20, top_n=5)
print(keywords)# 为了使结果多样化,我们可以使用最大边界相关算法(MMR)
# 来创建同样基于余弦相似度的关键字/关键短语。 具有高度多样性的结果:
print("\nhight diversity ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(3, 3), stop_words='english',use_mmr=True, diversity=0.7)
print(keywords)# 低多样性的结果
print("\nlow diversity ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(3, 3), stop_words='english',use_mmr=True, diversity=0.2)
print(keywords)
输出
naive ...
[('supervised', 0.5864), ('learning', 0.4431), ('analyzes', 0.3552), ('algorithm', 0.3514), ('training', 0.3099)]keyphrase_ngram_range ...
[('supervised learning', 0.7035), ('in supervised', 0.6108), ('supervised', 0.5864), ('machine learning', 0.5707), ('learning algorithm', 0.525)]highlight ...
Supervised learning the machine learning of learning a function that maps an
input to an output based on example input-output pairs. It infers a function
from labeled training data consisting of a set of training examples. In
supervised learning, each example is a pair consisting of an input object
(typically a vector) and a desired output value (also called the supervisory
signal). A supervised learning analyzes the training data and produces an
inferred function, which can be used for mapping new examples. An optimal
scenario will allow for the algorithm to correctly determine the class labels
for unseen instances. This requires the learning algorithm to generalize from
the training data to unseen situations in a 'reasonable' way (see inductive
bias).
[('supervised learning', 0.7035), ('examples supervised', 0.5993), ('supervised', 0.5864), ('machine learning', 0.5707), ('learning machine', 0.5437)]use_maxsum ...
[('algorithm generalize training', 0.4019), ('learning machine learning', 0.4859), ('learning function', 0.3978), ('supervised', 0.4374), ('examples supervised', 0.4266)]hight diversity ...
[('supervised learning example', 0.7558), ('input output pairs', 0.1015), ('object typically vector', 0.2502), ('situations reasonable way', 0.1763), ('determine class labels', 0.2358)]low diversity ...
[('supervised learning example', 0.7558), ('supervised learning machine', 0.6989), ('examples supervised learning', 0.7041), ('supervised learning algorithm', 0.6769), ('signal supervised learning', 0.6209)]
3.2 中文示例
from keybert import KeyBERT
import jieba# 中文测试
doc = "刚刚,理论计算机科学家、UT Austin 教授、量子计算先驱 Scott Aaronson 因其「对量子计算的开创性贡献」被授予 2020 年度 ACM 计算奖。在获奖公告中,ACM 表示:「量子计算的意义在于利用量子物理学定律解决传统计算机无法解决或无法在合理时间内解决的难题。Aaronson 的研究展示了计算复杂性理论为量子物理学带来的新视角,并清晰地界定了量子计算机能做什么以及不能做什么。他在推动量子优越性概念发展的过程起到了重要作用,奠定了许多量子优越性实验的理论基础。这些实验最终证明量子计算机可以提供指数级的加速,而无需事先构建完整的容错量子计算机。」 ACM 主席 Gabriele Kotsis 表示:「几乎没有什么技术拥有和量子计算一样的潜力。尽管处于职业生涯的早期,但 Scott Aaronson 因其贡献的广度和深度备受同事推崇。他的研究指导了这一新领域的发展,阐明了它作为领先教育者和卓越传播者的可能性。值得关注的是,他的贡献不仅限于量子计算,同时也在诸如计算复杂性理论和物理学等领域产生了重大影响。」"
doc = " ".join(jieba.cut(doc))
kw_model = KeyBERT(model='paraphrase-multilingual-MiniLM-L12-v2')print("naive ...")
keywords = kw_model.extract_keywords(doc)
print(keywords)print("\nkeyphrase_ngram_range ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(1, 2), stop_words=None)
print(keywords)print("\nhighlight ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(1, 2), highlight=True)
print(keywords)# 为了使结果多样化,我们将 2 x top_n 与文档最相似的词/短语。
# 然后,我们从 2 x top_n 单词中取出所有 top_n 组合,并通过余弦相似度提取彼此最不相似的组合。
print("\nuse_maxsum ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(1, 3), stop_words='english',use_maxsum=True, nr_candidates=20, top_n=5)
print(keywords)# 为了使结果多样化,我们可以使用最大边界相关算法(MMR)
# 来创建同样基于余弦相似度的关键字/关键短语。 具有高度多样性的结果:
print("\nhight diversity ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(3, 3), stop_words='english',use_mmr=True, diversity=0.7)
print(keywords)# 低多样性的结果
print("\nlow diversity ...")
keywords = kw_model.extract_keywords(doc, keyphrase_ngram_range=(3, 3), stop_words='english',use_mmr=True, diversity=0.2)
print(keywords)
输出
naive ...
[('量子', 0.6386), ('科学家', 0.4278), ('物理学', 0.421), ('理论', 0.3901), ('计算', 0.3562)]keyphrase_ngram_range ...
[('容错 量子', 0.7064), ('教授 量子', 0.6979), ('量子 计算', 0.6839), ('量子 物理学', 0.6801), ('量子 计算机', 0.6784)]highlight ...
刚刚 , 理论 计算机 科学家 、 UT Austin 教授 、 量子 计算 Scott Aaronson 因 其
「 对 量子 计算 开创性 贡献 」 被 授予 2020 年度 ACM 计算 奖 。 在 获奖 公告 中
, ACM 表示 : 「 量子 计算 意义 在于 利用 量子 物理学 解决 传统 计算机无法
解决 或 无法 在 合理 时间 内 解决 的 难题 。 Aaronson 的 研究 展示 了 计算
复杂性 理论 为 量子 物理学 的 新视角 , 并 清晰 地 界定 了 量子 计算机 做 什么
以及 不能 做 什么 。 他 在 推动 量子 优越性 概念 发展 的 过程 起到 了 重要 作用
, 奠定 了 许多 量子 优越性 实验 的 理论 基础 。 这些 实验 最终 证明 量子
计算机 提供 指数 级 的 加速 , 而 无需 事先 构建 完整 的 容错 量子 。 」 ACM
主席 Gabriele Kotsis 表示 : 「 几乎 没有 什么 技术 拥有 和 量子 计算 的 潜力
。 尽管 处于 职业生涯 的 早期 , 但 Scott Aaronson 因 其 贡献 的 广度 和 深度
备受 同事 推崇 。 他 的 研究 指导 了 这 一新 领域 的 发展 , 阐明 了 它 作为
领先 教育者 和 卓越 传播者 的 可能性 。 值得 关注 的 是 , 他 的 贡献 不仅 限于
量子 计算 同时 也 在 诸如 计算 复杂性 理论 和 物理学 等 领域 产生 了 重大 影响
。 」
[('容错 量子', 0.7064), ('教授 量子', 0.6979), ('量子 计算', 0.6839), ('量子 物理学', 0.6801), ('量子 计算机', 0.6784)]use_maxsum ...
[('限于 量子 计算', 0.6529), ('aaronson 量子 计算', 0.349), ('austin 教授 量子', 0.3982), ('量子 计算机 acm', 0.4045), ('容错 量子 计算机', 0.4695)]hight diversity ...
[('教授 量子 计算', 0.7387), ('传统 计算机无法 解决', 0.3671), ('2020 年度 acm', 0.3552), ('解决 难题 aaronson', 0.3438), ('加速 无需 事先', 0.1518)]low diversity ...
[('教授 量子 计算', 0.7387), ('量子 计算机 acm', 0.7276), ('容错 量子 计算机', 0.7385), ('aaronson 量子 计算', 0.7096), ('austin 教授 量子', 0.7272)]
hilight怎么才能显示作用呢?
4、加载不同的模型库
4.1 SentenceTransformers模型调用
SentenceTransformers包含一系列模型,具体可参考Pretrained Models页面中的模型内容。
模型的使用方法很简单:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(model='model_name')
model_name 从下面的名称中选择。
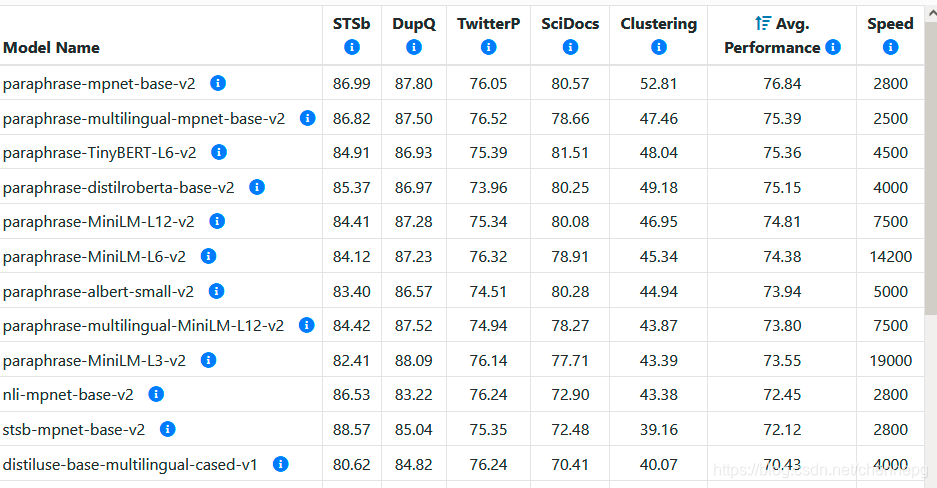
- 众多模型中,使用 paraphrase-mpnet-base-v2 以获得最佳质量,如果您想要高质量的快速模型,请使用 paraphrase-MiniLM-L6-v2。
- 建议对英文文档使用“paraphrase-MiniLM-L6-v2”,或者对多语言文档或任何其他语言使用“paraphrase-multilingual-MiniLM-L12-v2”。
主要的模型名字如下图所示。
4.2 Transformers模型调用
直接使用Transformers库中的模型名称,不需要通过 from transformers import BertModel 加载。
kw_model = KeyBERT(model="uer/chinese_roberta_L-2_H-128")# 在windows 10中,自动下载到 C:\Users\chen_\.cache\torch\sentence_transformers\uer_chinese_roberta_L-2_H-128中,
# 把整这个文件拷贝到本地目录,然后采用下面的方法加载模型import pathlib
cur_folder = pathlib.Path(__file__).parent.resolve()
model = f"{cur_folder}/uer_chinese_roberta_L-2_H-128"
kw_model = KeyBERT(model=model)
4.3 Flair模型调用
Flair 允许您选择几乎所有公开可用的嵌入模型。请从这里查找,模型太多,请按照自己需要选择。
Flair 的使用方式如下:
from keybert import KeyBERT
from flair.embeddings import TransformerDocumentEmbeddingsroberta = TransformerDocumentEmbeddings('roberta-base')
kw_model = KeyBERT(model=roberta)
5、ZhKeyBERT的使用
5.1 安装
git clone https://github.com/deepdialog/ZhKeyBERT
cd ZhKeyBERT
python setup.py install --user
5.2 使用
from zhkeybert import KeyBERT, extract_kws_zhdocs = """时值10月25日抗美援朝纪念日,《长津湖》片方发布了“纪念中国人民志愿军抗美援朝出国作战71周年特别短片”,再次向伟大的志愿军致敬!
电影《长津湖》全情全景地还原了71年前抗美援朝战场上那场史诗战役,志愿军奋不顾身的英勇精神令观众感叹:“岁月峥嵘英雄不灭,丹心铁骨军魂永存!”影片上映以来票房屡创新高,目前突破53亿元,暂列中国影史票房总榜第三名。
值得一提的是,这部影片的很多主创或有军人的血脉,或有当兵的经历,或者家人是军人。提起这些他们也充满自豪,影片总监制黄建新称:“当兵以后会有一种特别能坚持的劲儿。”饰演雷公的胡军透露:“我父亲曾经参加过抗美援朝,还得了一个三等功。”影片历史顾问王树增表示:“我当了五十多年的兵,我的老部队就是上甘岭上下来的,那些老兵都是我的偶像。”
“身先士卒卫华夏家国,血战无畏护山河无恙。”片中饰演七连连长伍千里的吴京感叹:“要永远记住这些先烈们,他们给我们带来今天的和平。感谢他们的付出,才让我们有今天的幸福生活。”饰演新兵伍万里的易烊千玺表示:“战争的残酷、碾压式的伤害,其实我们现在的年轻人几乎很难能体会到,希望大家看完电影后能明白,是那些先辈们的牺牲奉献,换来了我们的现在。”
影片对战争群像的恢弘呈现,对个体命运的深切关怀,令许多观众无法控制自己的眼泪,观众称:“当看到影片中的惊险战斗场面,看到英雄们壮怀激烈的拼杀,为国捐躯的英勇无畏和无悔付出,我明白了为什么说今天的幸福生活来之不易。”(记者 王金跃)"""
kw_model = KeyBERT(model='paraphrase-multilingual-MiniLM-L12-v2')
extract_kws_zh(docs, kw_model)
具体使用,请一步到位下面的官方链接。
- deepdialog/ZhKeyBERT
- zhkeybert 0.1.2
6、参考链接
- keybert 0.4.0 Project description
- Keyword Extraction with BERT
- 【关于 KeyBERT 】 那些你不知道的事
- deepdialog/ZhKeyBERT
- zhkeybert 0.1.2
- keybert做中文文本关键词提取

![[转]NLP关键词提取方法总结及实现](https://img-blog.csdnimg.cn/img_convert/93ef9b5a6f6c5a39c46ed8a4e2532df3.png)






![[问题已处理]-阿里云与本地机房中挖矿病毒处理,又又又中毒了](https://img-blog.csdnimg.cn/img_convert/aa047e10a3f553cae57ca00e96957f81.png)