诸神缄默不语-个人CSDN博文目录
本文将介绍一些简单的使用Python3实现关键词提取的算法。目前仅整理了一些比较简单的方法,如后期将了解更多、更前沿的算法,会继续更新本文。
文章目录
- 1. 基于TF-IDF算法的中文关键词提取:使用jieba包实现
- 2. 基于TextRank算法的中文关键词提取:使用jieba包实现
- 3. 基于TextRank算法的中文关键词提取(使用textrank_zh包实现)
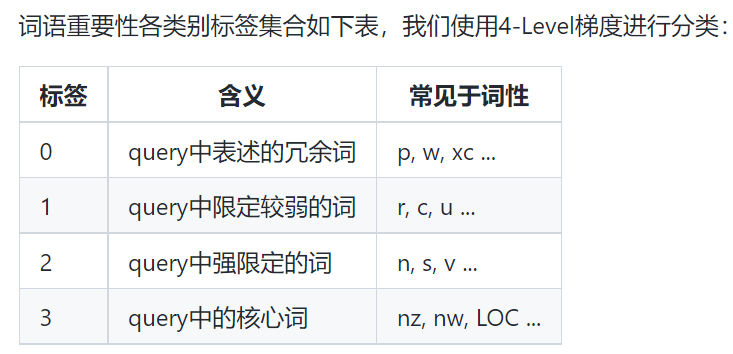
- 3. 没说基于什么算法的中文词语重要性:LAC实现
- 4. KeyBert
1. 基于TF-IDF算法的中文关键词提取:使用jieba包实现
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"import jieba.analyse
print(jieba.analyse.extract_tags(extracted_sentences, topK=20, withWeight=False, allowPOS=()))
输出:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.457 seconds.
Prefix dict has been built successfully.
['预测', '模型', '销量', '降低库存', '企业', 'AI', '规划', '提高', '准确性', '助力', '交货', '算法', '计量', '序列', '较差', '繁多', '过多', '假设', '缩短', '营销']
函数入参:
topK:返回TF-IDF权重最大的关键词的数目(默认值为20)withWeight是否一并返回关键词权重值,默认值为 FalseallowPOS仅包括指定词性的词,默认值为空,即不筛选
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径:
用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/idf.txt.big
用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_idfpath.py
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径:
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_stop_words.py
2. 基于TextRank算法的中文关键词提取:使用jieba包实现
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"import jieba.analyse
print(jieba.analyse.textrank(extracted_sentences, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')))
输出:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.451 seconds.
Prefix dict has been built successfully.
['企业', '预测', '模型', '规划', '提高', '销量', '比如', '时间', '市场', '分析', '降低库存', '成本', '缩短', '交货', '影响', '因素', '情况', '计量', '现实', '数据']
入参和第一节中的入参相同,但allowPOS的默认值不同。
TextRank用固定窗口大小(默认为5,通过span属性调整),以词作为节点,以词之间的共现关系作为边,构建无向带权图。
然后计算图中节点的得分,计算方式类似PageRank。
对PageRank的计算方式和原理的更深入了解可以参考我之前撰写的博文:cs224w(图机器学习)2021冬季课程学习笔记4 Link Analysis: PageRank (Graph as Matrix)_诸神缄默不语的博客-CSDN博客
3. 基于TextRank算法的中文关键词提取(使用textrank_zh包实现)
待补。
3. 没说基于什么算法的中文词语重要性:LAC实现
最后输出的数值就是对应词语的重要性得分。
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"from LAC import LAC
lac=LAC(mode='rank')
seg_result=lac.run(extracted_sentences) #以Unicode字符串为入参
print(seg_result)
输出:
W0625 20:13:22.369424 33363 init.cc:157] AVX is available, Please re-compile on local machine
W0625 20:13:22.455566 33363 analysis_predictor.cc:518] - GLOG's LOG(INFO) is disabled.
W0625 20:13:22.455617 33363 init.cc:157] AVX is available, Please re-compile on local machine
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [fc_lstm_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
W0625 20:13:22.561131 33363 analysis_predictor.cc:518] - GLOG's LOG(INFO) is disabled.
W0625 20:13:22.561169 33363 init.cc:157] AVX is available, Please re-compile on local machine
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [fc_lstm_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
[['随着', '企业', '持续', '产生', '的', '商品', '销量', ',', '其', '数据', '对于', '自身', '营销', '规划', '、', '市场分析', '、', '物流', '规划', '都', '有', '重要', '意义', '。', '但是', '销量', '预测', '的', '影响', '因素', '繁多', ',', '传统', '的', '基于', '统计', '的', '计量', '模型', ',', '比如', '时间', '序列', '模型', '等', '由于', '对', '现实', '的', '假设', '情况', '过多', ',', '导致', '预测', '结果', '较差', '。', '因此', '需要', '更加', '优秀', '的', '智能', 'AI算法', ',', '以', '提高', '预测', '的', '准确性', ',', '从而', '助力', '企业', '降低', '库存', '成本', '、', '缩短', '交货', '周期', '、', '提高', '企业', '抗', '风险', '能力', '。'], ['p', 'n', 'vd', 'v', 'u', 'n', 'n', 'w', 'r', 'n', 'p', 'r', 'vn', 'n', 'w', 'n', 'w', 'n', 'n', 'd', 'v', 'a', 'n', 'w', 'c', 'n', 'vn', 'u', 'vn', 'n', 'a', 'w', 'a', 'u', 'p', 'v', 'u', 'vn', 'n', 'w', 'v', 'n', 'n', 'n', 'u', 'p', 'p', 'n', 'u', 'vn', 'n', 'a', 'w', 'v', 'vn', 'n', 'a', 'w', 'c', 'v', 'd', 'a', 'u', 'n', 'nz', 'w', 'p', 'v', 'vn', 'u', 'n', 'w', 'c', 'v', 'n', 'v', 'n', 'n', 'w', 'v', 'vn', 'n', 'w', 'v', 'n', 'v', 'n', 'n', 'w'], [0, 1, 1, 1, 0, 2, 2, 0, 1, 2, 0, 1, 2, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 0, 0, 2, 2, 0, 2, 1, 2, 0, 2, 0, 0, 2, 0, 2, 1, 0, 1, 2, 2, 1, 0, 0, 0, 2, 0, 2, 1, 2, 0, 1, 2, 2, 2, 0, 0, 1, 1, 2, 0, 2, 2, 0, 0, 2, 2, 0, 2, 0, 0, 2, 1, 1, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 2, 2, 0]]
4. KeyBert
(待补)

![[转]NLP关键词提取方法总结及实现](https://img-blog.csdnimg.cn/img_convert/93ef9b5a6f6c5a39c46ed8a4e2532df3.png)

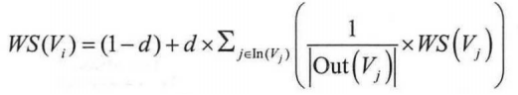





![[问题已处理]-阿里云与本地机房中挖矿病毒处理,又又又中毒了](https://img-blog.csdnimg.cn/img_convert/aa047e10a3f553cae57ca00e96957f81.png)
