python垃圾回收机制
现在的高级语言如java,c#等,都采用了垃圾收集机制,而不再是c,c++里用户自己管理维护内存的方式。自己管理内存极其自由,可以任意申请内存,但如同一把双刃剑,为大量内存泄露,悬空指针等bug埋下隐患。
对于一个字符串、列表、类甚至数值都是对象,且定位简单易用的语言,自然不会让用户去处理如何分配回收内存的问题。
python里也同java一样采用了垃圾收集机制,不过不一样的是:
python采用的是引用计数机制为主,标记-清除和分代收集(隔代回收)两种机制为辅的策略。
一、引用计数器
1.1环状的双向链表(Refchain)
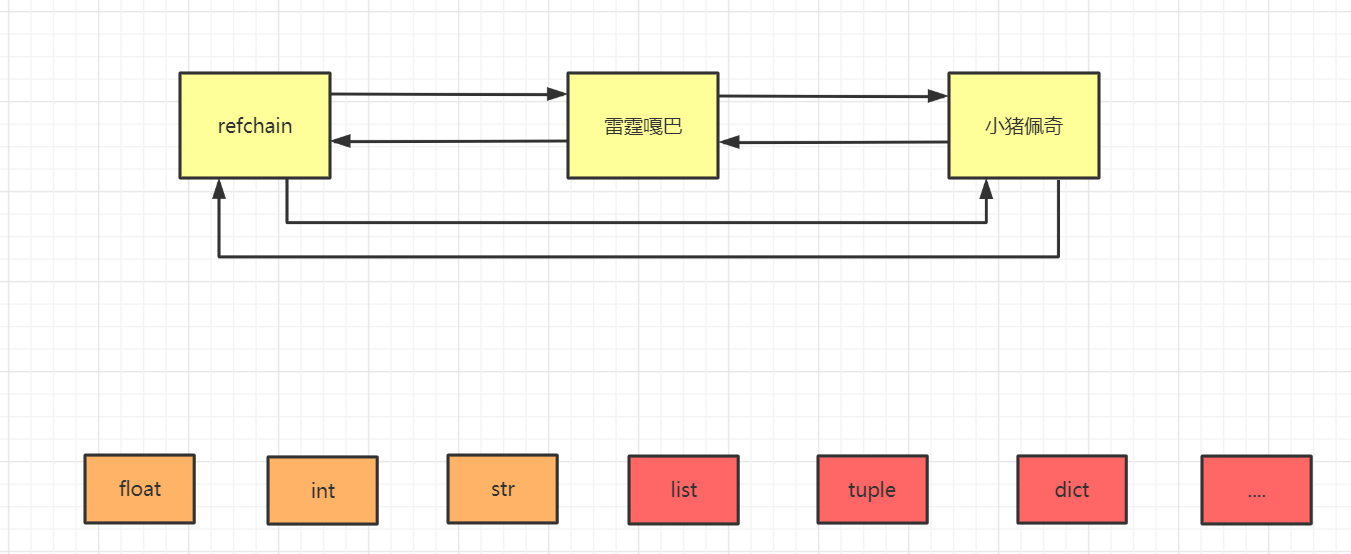
在python程序中,创建的任何对象都会放在refchain的双向链表中
例如:
name = "小猪佩奇" # 字符串对象
age = 18 # 整形对象
hobby = ["吸烟","喝酒","烫头"] # 列表对象
这些对象都会放到这些双向链表当中,也就是帮忙维护了python中所有的对象。
也就是说如果你得到了refchain,也就得到了python程序中的所有对象。
1.2不同类型对象的存放形式
刚刚提到了所有的对象都存放在环状的双向链表中,而不同类型的对象存放在双向链表中既有一些共性特征也有一些不同特征。
# name = "小猪佩奇"
# 创建这个对象时,内部会创建一些数据,并且打包在一起
# 哪些数据:【指向上一个对象的指针、指向下一个对象的指针、类型(这里为字符串)、引用的个数】
"""
引用的个数:比如 name = '小猪佩奇' ,会给“小猪佩奇”开辟一个内存空间用来存放到双向链表中。这时候如果有 new = name,不会创建两个“小猪佩奇”,而是将new指向之前的那个小猪佩奇,而引用的个数变为2,也就是"小猪佩奇"这个对象被引用了两次。
"""
- 相同点:刚刚讲到的四个种数据每个对象都包含有。
# 内部会创建一些数据,【指向上一个对象的指针、指向下一个对象的指针、类型、引用的个数】
age = 18 # 整形对象
# 内部会创建一些数据,【指向上一个对象的指针、指向下一个对象的指针、类型、引用的个数】
hobby = ["吸烟","喝酒","烫头"] # 列表对象
- 不同点:
不同的数据类型还会创建不同的值:
# 内部会创建一些数据,【指向上一个对象的指针、指向下一个对象的指针、类型、引用的个数、val=18】
age = 18 # 整形对象
# 内部会创建一些数据,【指向上一个对象的指针、指向下一个对象的指针、类型、引用的个数、items=元素、元素的个数】
hobby = ["抽烟","喝酒","烫头"] # 列表对象
所以在python中创建的对象会加到环形双向链表中,但是每一种类型的数据对象在存到链表中时,所存放的数据个数可能是不同的(有相同点有不同点)。
两个重要的结构体
Python解释器由c语言开发完成,py中所有的操作最终都由底层的c语言来实现并完成,所以想要了解底层内存管理需要结合python源码来进行解释。
#define PyObject_HEAD PyObject ob_base ;
#define PyObject_VAR_HEAD PyVarObject ob_base;
//宏定义,包含上一个、下一个,用于构造双向链表用。(放到refchain链表中时,要用到)
#define _PyObject_HEAD_EXTRA \struct _object *_ob_next; \struct _object *_ob_prev;
typedef struct _object {_PyObject_HEAD_EXTRA //用于构造双向链表Py_ssize_t ob_refcnt; //引用计数器struct _typeobject *ob_type; //数据类型
} PyObject;
typedef struct {PyObject ob_base; // PyObject对象Py_ssize_t ob_size; /* Number of items in variable part, 即:元素个数*/
} PyVarObject;
在C源码中如何体现每个对象中都有的相同的值:PyObject结构体(4个值:_ob_next、_ob_prev、ob_refcnt、*ob_type)
9-13行 定义了一个结构体,第10行实际上就是6,7两行,用来存放前一个对象,和后一个对象的位置。
这个结构体可以存贮四个值(这四个值是对象都具有的)。
在C源码中如何体现由多个元素组成的对象:PyObject + ob_size(元素个数)
15-18行又定义了一个结构体,第16行相当于代指了9-13行中的四个数据。
而17行又多了一个数据字段,叫做元素个数,这个结构体。
以上源码是Python内存管理中的基石,其中包含了:
- 2个结构体
- PyObject,此结构体中包含3个元素。
- PyObject_HEAD_EXTRA,用于构造双向链表。
- ob_refcnt,引用计数器。
- *ob_type,数据类型。
- PyVarObject,次结构体中包含4个元素(ob_base中包含3个元素)
- ob_base,PyObject结构体对象,即:包含PyObject结构体中的三个元素。
- ob_size,内部元素个数。
类型封装的结构体
在我们了解了这两个结构体,现在我们来看看每一个数据类型都封装了哪些值:
- flaot类型
float结构体:
typedef struct {PyObject_HEAD # 这里相当于代表基础的4个值double ob_fval;
} PyFloatObject;
例:
data = 3.14
内部会创建:_ob_next = refchain中的上一个对象_ob_prev = refchain中的后一个对象ob_refcnt = 1 引用个数ob_type= float 数据类型ob_fval = 3.14
- int类型
int结构体:
struct _longobject {PyObject_VAR_HEADdigit ob_digit[1];
};
// longobject.h
/* Long (arbitrary precision) integer object interface */
typedef struct _longobject PyLongObject; /* Revealed in longintrepr.h */
道理都是相同的,第2行代指第二个重要的结构体,第三行是int形特有的值,总结下来就是这个结构体中有几个值,那么创建这个类型对象的时候内部就会创建几个值。
- list类型
list结构体:
typedef struct {PyObject_VAR_HEAD/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */PyObject **ob_item;/* ob_item contains space for 'allocated' elements. The number* currently in use is ob_size.* Invariants:* 0 <= ob_size <= allocated* len(list) == ob_size* ob_item == NULL implies ob_size == allocated == 0* list.sort() temporarily sets allocated to -1 to detect mutations.** Items must normally not be NULL, except during construction when* the list is not yet visible outside the function that builds it.*/Py_ssize_t allocated;
} PyListObject;
- tuple类型
tuple结构体:
typedef struct {PyObject_VAR_HEADPyObject *ob_item[1];/* ob_item contains space for 'ob_size' elements.* Items must normally not be NULL, except during construction when* the tuple is not yet visible outside the function that builds it.*/
} PyTupleObject;
- dict类型
dict结构体:
typedef struct {PyObject_HEADPy_ssize_t ma_used;PyDictKeysObject *ma_keys;PyObject **ma_values;
} PyDictObject;
到这里我们就学到了什么是环状双向链表,以及双向链表中存放的每一种数据类型的对象都是怎样的。
1.3引用计数器
v1 = 3.14
v2 = 999
v3 = (1,2,3)
当python程序运行时,会更具数据类型的不同,找到其对应的结构体,根据结构体中的字段,来进行创建相关的数据,然后将对象添加到refchain双向链表中。
为了体现我们看过源码的牛逼之处,我们还可以进一步理解。
在C源码中有两个关键的结构体:PyObject、PyvarObject
- PyObject(存储是上一个对象,下一个对象,类型,引用的个数,是每一个对象都具有的)。
- PyvarObject(存储的是由多个元素组成的类型数据具有的值,例如字符串,int)。
- python3中没有long类型,只有int类型,但py3内部的int是基于long实现。
- python3中对int长度没有限制,其内部使用由多个元素组成的类似于“字符串”的机制来存储的。
每个对象中都有ob_refcnt ,它就是引用计数器,创建时默认是1,当有其他变量重新引用的时候,引用计数器就会发生变化。
计数器增加
当发生以下四种情况的时候,该对象的引用计数器**+1:**
a=14 # 对象被创建
b=a # 对象被引用
func(a) # 对象被作为参数,传到函数中
List=[a,"a","b",2] # 对象作为一个元素,存储在容器中
b = 9999 # 引用计数器的值为1
c = b # 引用计数器的值为2
计数器减小
当发生以下四种情况时,该对象的引用计数器**-1**
当该对象的别名被显式销毁时 del a
当该对象的引别名被赋予新的对象, a=26
一个对象离开它的作用域,例如 func函数执行完毕时,函数里面的局部变量的引用计数器就会减一(但是全局变量不会)
将该元素从容器中删除时,或者容器被销毁时。
a = 999
b = a # 当前计数器为2
del b # 删除变量b:b对应的对象的引用计数器-1 (此时计数器为1)
del a # 删除变量a:a对应的对象的引用计数器-1 (此时引用计数器为0)# 当引用计数器为0 时,意味着没有人再使用这个对象,这个对象就变成垃圾,垃圾回收。
# 回收:1.对象从refchain的链表移除。2.将对象进行销毁,内存归还给操作系统,可用内存就增加。
以上就是引用计数器大体上的机制,但是后面的缓存机制学习完之后我们才会进一步理解,这里不是简单的说计数器等于0就销毁,内部还有一定的缓冲,目前就简单理解成计数器为0,我们就进行垃圾回收。
例子
a = "雷霆嘎巴" # 创建对象并初始话引用计数器为1
b = a # 计数器发生变化
c = a
d = a
e = a f = "小猪佩奇" # 创建对象并初始话引用计数器为1
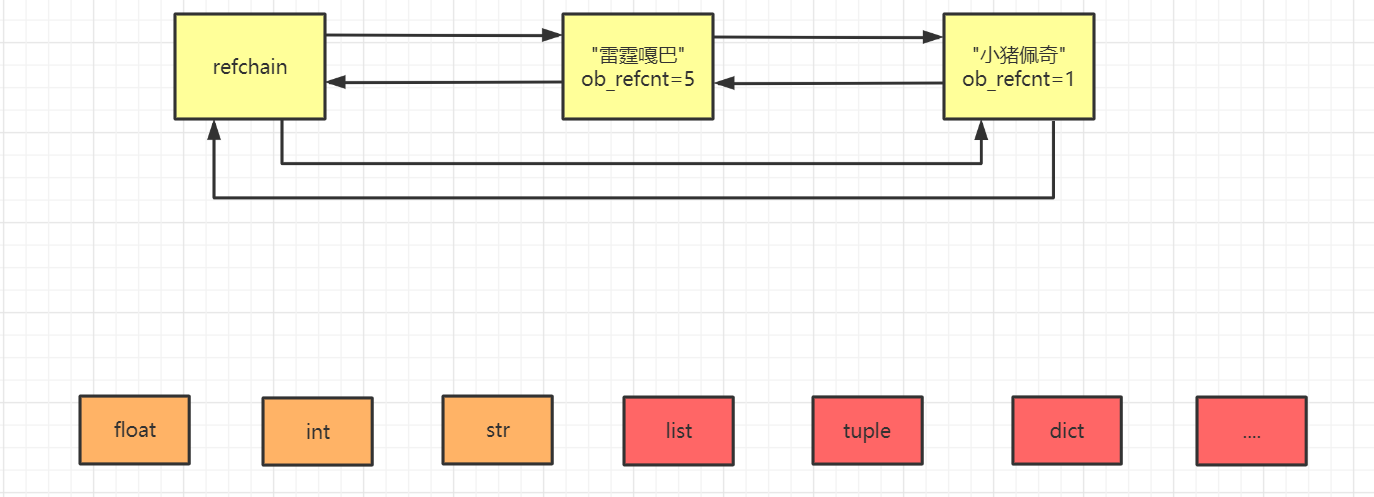
当我们将"雷霆嘎巴"的对象的引用计数器减小至0时,就将其移除,并且相邻两边直接连接。
1.4循环引用问题
一种编程语言利用引用计数器实现垃圾管理和回收,已经是比较完美的了,只要计数器为0就回收,不为0就不回收,即简单明了,又能实现垃圾管理。
但是如果真正这样想就太单纯了,因为,仅仅利用引用计数器实现垃圾管理和回收,就会存在一个BUG,就是循环引用问题。
比如:
v1 = [1,2,3] # refchain中创建一个列表对象,由于v1=对象,所以列表引对象用计数器为1.
v2 = [4,5,6] # refchain中再创建一个列表对象,因v2=对象,所以列表对象引用计数器为1.
v1.append(v2) # 把v2追加到v1中,则v2对应的[4,5,6]对象的引用计数器加1,最终为2.
v2.append(v1) # 把v1追加到v1中,则v1对应的[1,2,3]对象的引用计数器加1,最终为2.del v1 # 引用计数器-1
del v2 # 引用计数器-1最终v1,v2引用计数器都是1
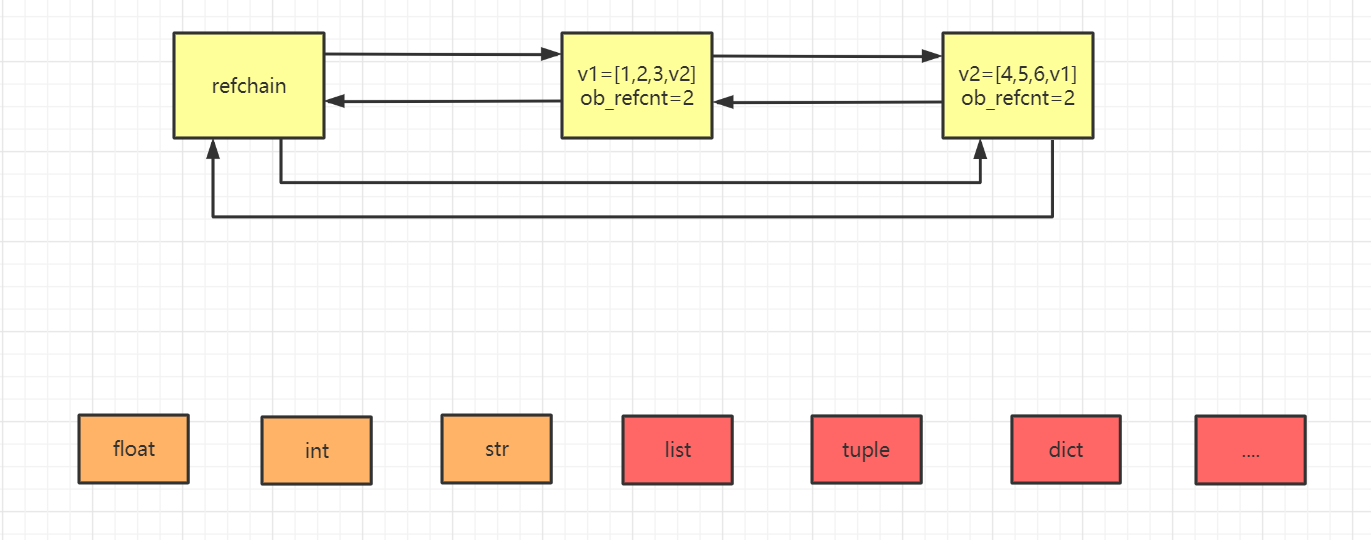
两个引用计数器现在都是1,那么它们都不是垃圾所以都不会被回收,但如果是这样的话,我们的代码就会出现问题。
我们删除了v1和v2,那么就没有任何变量指向这两个列表,那么这两个列表之后程序运行的时候都无法再使用,但是这两个列表的引用计数器都不为0,所以不会被当成垃圾进行回收,所以这两个列表就会一直存在在我们的内存中,永远不会销毁,当这种代码越来越多时,我们的程序一直运行,内存就会一点一点被消耗,然后内存变满,满了之后就爆栈了。这时候如果重新启动程序或者电脑,这时候程序又会正常运行,其实这就是因为循环引用导致数据没有被及时的销毁导致了内存泄漏。
1.5总结
优点
- 简单
- 实时性:一旦没有引用,内存就直接释放了。 不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时
缺点
- 维护引用计数消耗资源
- 循环引用
对于如今的强大硬件,缺点1尚可接受,但是循环引用导致内存泄露,注定python还将引入新的回收机制(标记清除和分代收集)。
二、标记清除
2.1引入目的
为了解决循环引用的不足,python的底层不会单单只用引用计数器,引入了一个机制叫做标记清楚。
2.2实现原理
在python的底层中,再去维护一个链表,这个链表中专门放那些可能存在循环引用的对象。
那么哪些情况可能导致循环引用的情况发生?
就是那些元素里面可以存放其他元素的元素。(list/dict/tuple/set,甚至class)
例如:
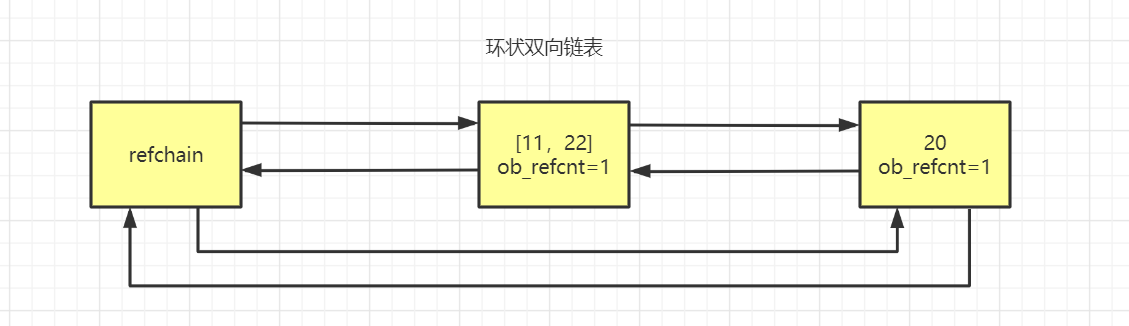
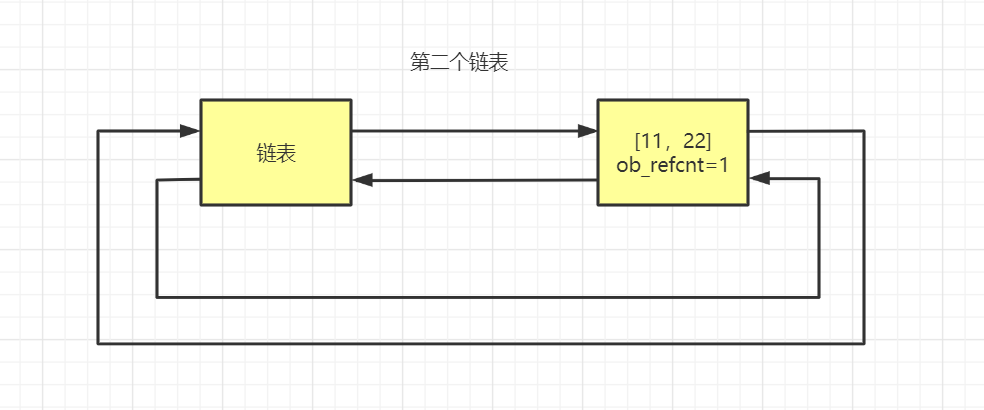
第二个链表 只存储 可能是循环引用的对象。
维护两个链表的作用是,在python内部某种情况下,会去扫描可能存在循环引用的链表中的每个元素,在循环一个列表的元素时,由于内部还有子元素 ,如果存在循环引用(v1 = [1,2,3,v2]和v2 = [4,5,6,v1]),比如从v1的子元素中找到了v2,又从v2的子元素中找到了v1,那么就检查到循环引用,如果有循环引用,就让双方的引用计数器各自-1,如果是0则垃圾回收。
2.3标记清除算法
【标记清除(Mark—Sweep)】算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
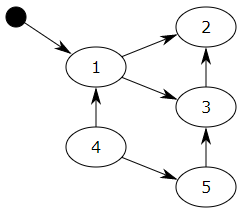
在上图中,我们把小黑点视为全局变量,也就是把它作为root object,从小黑点出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
-
寻找跟对象(root object)的集合作为垃圾检测动作的起点,跟对象也就是一些全局引用和函数栈中的引用,这些引用所指向的对象是不可被删除的。
-
从root object集合出发,沿着root object集合中的每一个引用,如果能够到达某个对象,则说明这个对象是可达的,那么就不会被删除,这个过程就是垃圾检测阶段。
-
当检测阶段结束以后,所有的对象就分成可达和不可达两部分,所有的可达对象都进行保留,其它的不可达对象所占用的内存将会被回收,这就是垃圾回收阶段。(底层采用的是链表将这些集合的对象连接在一起)。
三、分代回收
3.1引入目的
问题:
- 什么时候扫描去检测循环引用?
- 标记和清除的过程效率不高。清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
为了解决上述的问题,python又引入了分代回收。
3.2原理
将第二个链表(可能存在循环引用的链表),维护成3个环状双向的链表:
- 0代: 0代中对象个数达到700个,扫描一次。
- 1代: 0代扫描10次,则1代扫描1次。
- 2代: 1代扫描10次,则2代扫描1次。
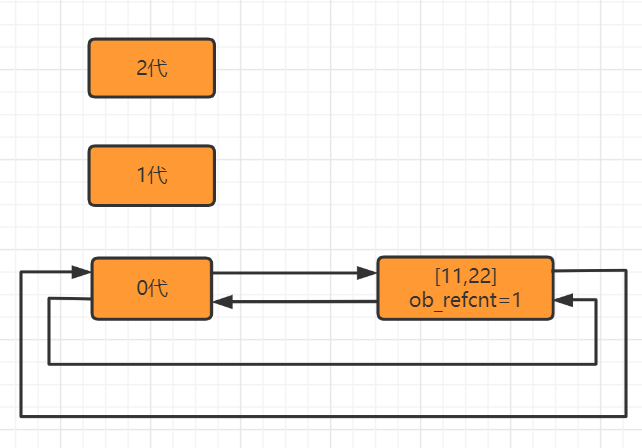
// 分代的C源码
#define NUM_GENERATIONS 3
struct gc_generation generations[NUM_GENERATIONS] = {/* PyGC_Head, threshold, count */{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代
};
例:
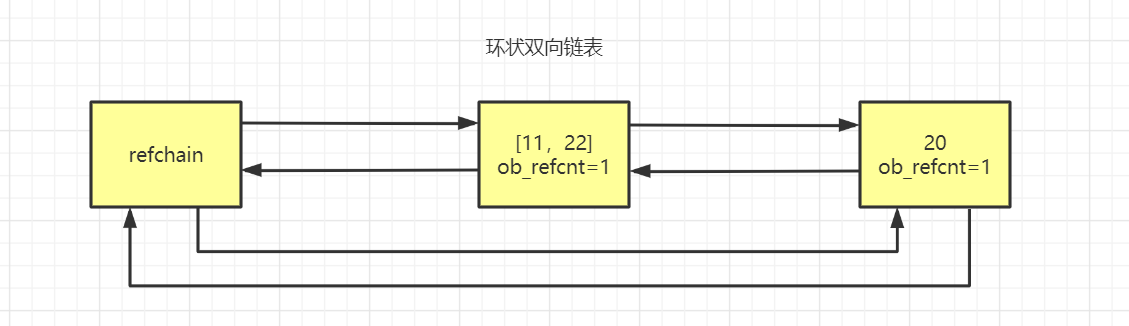
当我们创建一个对象val = 19,那么它只会加到refchain链表中。
当我们创建一个对象v1 = [11,22],除了加到refchain,那么它会加到0代链表中去。
如果再创建一个对象v2 = [33,44],那么它还是往0代添加。
直到0代中的个数达到700之后,就会对0代中的所有元素进行一次扫描,扫描时如果检测出是循环引用那么引用计数器就自动-1,然后判断引用计数器是否为0,如果为0,则为垃圾就进行回收。不是垃圾的话,就对该数据进行升级,从0代升级到1代,这个时候0代就是空,1代就会记录一下0代已经扫描1次,然后再往0代中添加对象直到700再进行一次扫描,不停反复,直到0代扫描了10次,才会对1代进行1次扫描。
分代回收解决了标记清楚时什么时候扫描的问题,并且将扫描的对象分成了3级,以及降低扫描的工作量,提高效率。
3.3弱代假说
为什么要按一定要求进行分代扫描?
这种算法的根源来自于弱代假说(weak generational hypothesis)。
这个假说由两个观点构成:首先是年轻的对象通常死得也快,而老对象则很有可能存活更长的时间。
假定现在我用Python创建一个新对象 n1=“ABC”
根据假说,我的代码很可能仅仅会使用ABC很短的时间。这个对象也许仅仅只是一个方法中的中间结果,并且随着方法的返回这个对象就将变成垃圾了。大部分的新对象都是如此般地很快变成垃圾。然而,偶尔程序会创建一些很重要的,存活时间比较长的对象,例如web应用中的session变量或是配置项。
频繁的处理零代链表中的新对象,可以将让Python的垃圾收集器把时间花在更有意义的地方:它处理那些很快就可能变成垃圾的新对象。同时只在很少的时候,当满足一定的条件,收集器才回去处理那些老变量。
四、总结
在python中维护了refchain的双向环状链表,这个链表中存储创建的所有对象,而每种类型的对象中,都有一个ob_refcnt引用计数器的值,它维护者引用的个数+1,-1,最后当引用计数器变为0时,则进行垃圾回收(对象销毁、refchain中移除)。
但是,在python中对于那些可以有多个元素组成的对象,可能会存在循环引用的问题,并且为了解决这个问题,python又引入了标记清除和分代回收,在其内部维护了4个链表,分别是:
- refchain
- 2代,10次
- 1代,10次
- 0代,700个
在源码内部,当达到各自的条件阈值时,就会触发扫描链表进行标记清除的动作(如果有循环引用,引用计数器就各自-1)。
但是,源码内部在上述的流程中提出了优化机制,就是缓存机制。
五、缓存机制
缓存在python中分为两大类
5.1池
在python中为了避免重复创建和销毁一些常见对象,维护池。
例:
v1 = 7
v2 = 9
v3 = 9# 按理说在python中会创建3个对象,都加入refchain中。
然而python在启动解释器时,python认为-5、-4、…… 、256,bool、一定规则的字符串,这些值都是常用的值,所以就会在内存中帮你先把这些值先创建好,接下来进行验证:
# 启动解释器时,python内部帮我们创建-5、-4、...255、256的整数和一定规则的字符串
v1 = 9 # 内部不会开辟内存,直接去池中获取
v2 = 9 # 同上,都是去数据池里直接拿9,所以v1和v2指向的内存地址是一样的
print(id(v1),id(v2))v3 = 256 # 内部不会开辟内存,直接去池中获取
v4 = 256 # 同上,都是去数据池里直接拿256,所以v3和v4指向的内存地址是一样的
print(id(v3),id(4))v5 = 257
v6 = 257
print(id(v5),id(v6))
排查原因:版本不同,小数据池扩大。
在交互模式下返回得结果符合预期,文件模式的情况下
问题:为什么交互模式和命令模式结果有区别?
答:因为代码块的缓存机制。
- 什么是代码块?
一个模块、一个函数、一个类、一个文件等都是一个代码块;交互式命令下,一行就是一个代码块。
-
同一个代码块内的缓存机制(字符串驻留机制)
- 机制内容:Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用,即将两个变量指向同一个对象。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在用命令模式执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。
- 适用对象: int(float),str,bool。
-
对象的具体细则:(了解)
-
int(float):任何数字在同一代码块下都会复用。
-
bool:True和False在字典中会以1,0方式存在,并且复用。
-
str:几乎所有的字符串都会符合字符串驻留机制
-
# 同一个代码块内的缓存机制————任何数字在同一代码块下都会复用
i1 = 1000
i2 = 1000
print(id(i1))
print(id(i2))
输出结果:# 同一个代码块内的缓存机制————几乎所有的字符串都会符合缓存机制
s1 = 'hfdjka6757fdslslgaj@!#fkdjlsafjdskl;fjds中国'
s2 = 'hfdjka6757fdslslgaj@!#fkdjlsafjdskl;fjds中国'
print(id(s1))
print(id(s2))
输出结果:# 同一个代码块内的缓存机制————非数字、str、bool类型数据,指向的内存地址一定不同
t1 = (1,2,3)
t2 = (1,2,3)
l1 = [1,2,3]
l2 = [1,2,3]
print(id(t1))
print(id(t2))
print(id(l1))
print(id(l2))
输出结果:
- 不同代码块间的缓存机制(小数据池、小整数缓存机制、小整数驻留机制)
- 适用对象: int(float),str,bool
-
- 具体细则:-5~256数字,bool,满足一定规则的字符串。
- 优点:提升性能,节省内存。
- Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
- python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
- 其实,无论是缓存还是字符串驻留池,都是python做的一个优化,就是将~5-256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中之创建一个。
# 创建文件1: file1
def A():b = 1print(id(b))# 创建文件2: file2
from file1 import A
a = 1
print(id(a))
A()
总结一下就是,**同一个代码块中(交互模式中的)因为字符串驻留机制,int(float),str,bool这些数据类型,只要对象相同,那么内存地址共享。
而不同代码块中只有引用对象为-5~256整数,bool,满足一定规则的字符串,**才会有内存共享,即id相同。
并且这些python编辑器初始化的数据,他们的引用计数器永远不会为0,在初始化的时候就会将引用计数器默认设置为1。
5.2 free_list
当一个对象的引用计数器为0的时候,按理说应该回收,但是在python内部为了优化,不会去回收,而是将对象添加到free_list链表中当作缓存。以后再去创建对象时就不再重新开辟内存,而是直接使用free_list。
v1 = 3.14 # 创建float型对象,加入refchain,并且引用计数器的值为1
del v1 #refchain中移除,按理说应该销毁,但是python会将对象添加到free_list中。v2 = 9.999 # 就不会重新开辟内存,去free_list中获取对象,对象内部数据初始化,再放到refchain中。
但是free_list也是有容量的,不是无限收纳, 假设默认数量为80,只有当free_list满的时候,才会直接去销毁。
代表性的有float/list/tuple/dict,这些数据类型都是以free_list方式来进行回收的。
缓存列表对象的创建源码:
总结一下,就是引用计数器为0的时候,有的是直接销毁,而有些需要先加入缓存当中的。
C源码分析
arena是 CPython 的内存管理结构之一。代码在Python/pyarena.c中其中包含了 C 的内存分配和解除分配的方法。
https://github.com/python/cpython/blob/master/Python/pyarena.c
Modules/gcmodule.c,该文件包含垃圾收集器算法的实现。
https://github.com/python/cpython/blob/master/Modules/gcmodule.c










![mysql初学——“[ERROR] [MY-012271] [InnoDB] The innodb_system data file 'ibdata1' must be writable”](https://img-blog.csdnimg.cn/20190519095607202.png)



![【无标题】1.[ERROR] InnoDB: The innodb_system data file ‘ibdata1‘ must be writable](https://img-blog.csdnimg.cn/71a19315ee044822a672a7d140c1e1c0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aSq6Ziz6bmP,size_20,color_FFFFFF,t_70,g_se,x_16)
