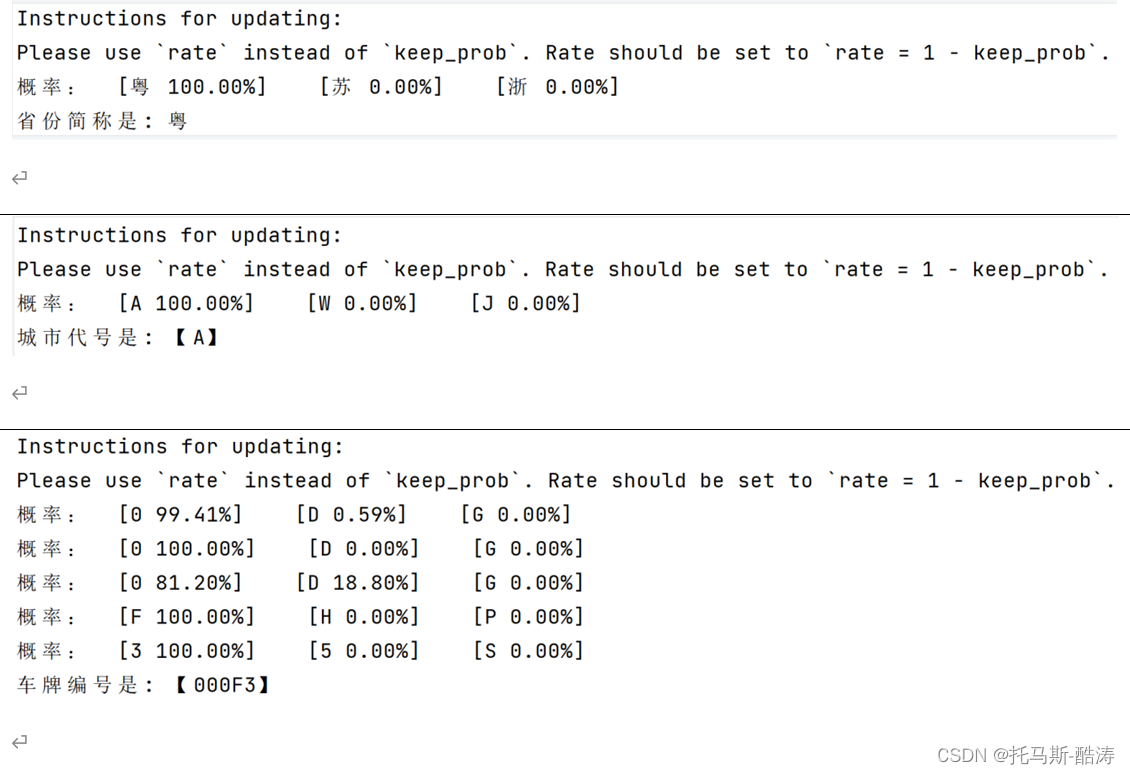
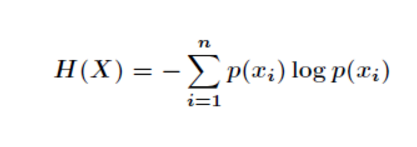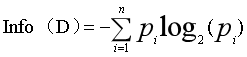1、数学期望
数学期望就是总体的均值,或者各项的加权平均。
先看离散的情况,假设X为离散型随机变量,x1,x2,x3,……,xk为随机变量的所有可能取值,p1,p2,p3,……,pk为随机变量相应取值发生的概率,其中p1+p2+p3+……+pk=1。
那么随机变量X的数学期望为:![]()
再看连续的情况,假设X为连续型随机变量,x表示随机变量在实数范围内的联系取值,f(x)为概率密度函数。
那么随机变量X的数学期望为:![]()
2、信息量
一个事件的信息量与这个事件发生的概率是呈负相关的。举个例子:下雨的时候,天上没有太阳,这基本上是一个必然事件,带给我们的信息很少。再举个例子:国足踢进了世界杯,这是个小概率事件,这里面一定有很多曲折的事情,把它搞清楚所需的信息量就越大。
这个很好理解,就拿生活中的例子来说,越大概率事件所涵盖的信息量越小,如:晴天的早上太阳从东边升起,这可以说是一个必然事件,给我们带来的信息几乎为零。如:国足踢进了世界杯,对于这种几乎不可能的小概率事件,人们估计都会想把它搞清楚,想把他们搞清楚需要的信息很多,比如谁踢进的球,他们赛场上表现如何,犯规了吗等等…变量的不确定性越大,把它搞清楚所需要的信息量也就越大,这很容易理解。
下面对信息量下个定义,假设X为随机变量,X取xi的概率为p(xi),那么xi发生的信息量为![]() ,其中log是以2为底的对数。由于log为递增函数,取负数之后则为递减,那么该公式满足“一个事件的信息量与其发生的概率是呈负相关的”的条件。
,其中log是以2为底的对数。由于log为递增函数,取负数之后则为递减,那么该公式满足“一个事件的信息量与其发生的概率是呈负相关的”的条件。
3、信息熵
信息量度量的是一个具体事件发生所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。
下面对信息熵进行定义,假设X为随机变量,那么X的信息熵表示X的所有取值所带来的信息量的期望,如下公式所示,p(xi)表示xi发生的概率,I(xi)表示xi发生的信息量,乘积累加和则表示了信息量的数学期望。
![]()
4、相对熵
相对熵又称KL散度,用于衡量两个概率分布(如p(X)、Q(X))之间的差异(距离)。
对于随机变量离散的情况,这么定义相对熵,即事件A和B的差别:
![]()
对于随机变量连续的情况,这么定义相对熵,即事件A和B的差别:
![]()
从上面的公式可以看出:
(1)如果PA=PB,那么对数部分为0,则推出整式为0,即D(A-B)=0;
(2)减号左边是事件A的信息熵;
(3)如果改变A和B的顺序,求D(B-A),就要用到B的信息熵,那么结果就不一样了。
5、交叉熵
交叉熵和相对熵(KL散度)的公式非常相近,其实就是KL散度的后半部分。那么交叉熵的定义如下:
![]()