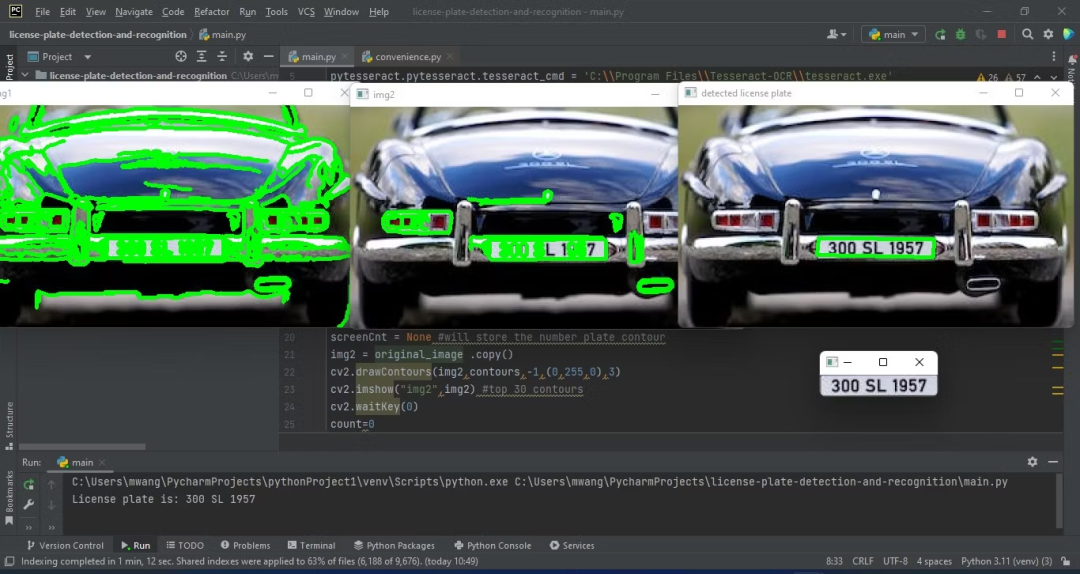
20221126 新增 首先说一下这个工程的思路,很多朋友妄想直接拿着工程用,那是不可能的,自己学去叭,我是先将车牌号预处理之后,整个图片干净一点之后,进行每个字符的切割,但是是很投机取巧的方法,是先切好第一个字符,再根据切割坐标,切割下一个字符,直到将所有字符切割好(所以采用你们自己的图片的时候,可能在这一步就出错了,甚至出现好几个字符在一起,就是因为切割原理就是根据字符的宽度来的,请明白这一点),切割完之后,就进行字符和字符模板的匹配,这一步我虽然忘了当时的想法,但确实用的是一种很简单的算法,我当时也查过,有很多很复杂的方法,但确实我不是做这方面的,确实只是为了完成作业而已,所以可能你们切割好了,也可能识别不是很成功。请自己去学习叭!当时就是觉得可以记录一下我的学习过程而已,因为平时自己找资料,很多也是要钱的,所以才建了一个qq群,上传我的一些经验,请需要的朋友自取,但也请尊重别人的劳动成果,注意自己的言论!
------------------------------------------------------------正文开始---------------------------------------------------------
系统设计
MATLAB中的设计
一个完整的车牌号识别系统要完成从图像采集到字符识别输出,过程相当复杂,基本可以分成硬件部分跟软件部分,硬件部分包括系统触发、图像采集,软件部分包括图像预处理、车牌定位、字符分割、字符识别四大部分,一个车牌识别系统的基本结构如图:

图形预处理:扫描原始图像,并得出其对应的hsv图片
车牌定位:根据hsv算法,对图像像素点进行遍历,取出蓝色部分
字符分割:根据二值图像对字符进行分割
字符识别:根据字符模板,对分割后的字符进行匹配
I=imread('E:\matlab\matlab2016b\exercise\car_find\车牌.jpg'); %读入车牌照片
figure(1);subplot(2,1,1);imshow(I);
title('原图');%%%%第一步根据hsv色彩定位法定位车牌%%%%
Image=im2double(I); %把图像数据类型转换为double类型
Image=rgb2hsv(Image); %将RGB图像转化为hsv模型,H色相,S饱和度,V亮度
figure(1);subplot(2,1,2);imshow(Image);
title('hsv图');
%%%%%%%%%%进行上下剪切%%%%%%%%%%%
[y,x,~]=size(Image); %得出图片的像素点横纵坐标
Blue_y = zeros(y, 1); %生成一个y*1的零矩阵
p=[0.56 0.71 0.4 1 0.3 1 0]; %蓝色的h s v范围
for i = 1 : y for j = 1 : x hij = Image(i, j, 1); %取出每个像素点的H、S、V值sij = Image(i, j, 2); vij = Image(i, j, 3); if (hij>=p(1) && hij<=p(2)) &&( sij >=p(3)&& sij<=p(4))&&(vij>=p(5)&&vij<=p(6)) %若像素点的HSV处于蓝色的HSV范围 Blue_y(i, 1) = Blue_y(i, 1) + 1;%统计每行的蓝色像素点数目 end end
end
[~, MaxY] = max(Blue_y);%得到Blue_y数最大的列数
Th = p(7); %Th=0
PY1 = MaxY; %获取蓝色像素点最多的行号
while ((Blue_y(PY1,1)>Th) && (PY1>0))%找到车牌上边界(将蓝色像素点逐次减一,直至有一个蓝色像素点的地方) PY1 = PY1 - 1;
end
PY2 = MaxY;
while ((Blue_y(PY2,1)>Th) && (PY2<y))%找到车牌下边界(将蓝色像素点逐次加一,直至上边界只有一个蓝色像素点的地方)PY2 = PY2 + 1;
end
PY1 = PY1 - 10; %上下边界校正(扩大)
PY2 = PY2 + 10;
if PY1 < 1 %如果图像内容只有车牌,上述校正可能会使得边界值超出合理范围,此处防止边界值超出图像范围PY1 = 1;
end
if PY2 > y PY2 = y;
end
It=I(PY1:PY2,:,:);%Y方向获取原图的车牌区域
figure(2);subplot(3,1,1),imshow(It);
title('hsv色彩分割法车牌定位结果');
%%%%%%%%%进行左右剪切%%%%%%%
IY = Image(PY1:PY2, :, :); %对HSV模型图像Image在Y方向进行截取
figure(2);subplot(3,1,2);imshow(IY);
title('HSV模型图像Image在Y方向进行截取');
[y1,x1,z1]=size(IY); %得出HSV模型图像Image在Y方向截取图片的像素点横纵坐标
Blue_x=zeros(1,x1); %生成一个1*x1的零矩阵
for j = 1 : x1 for i = 1 : y1 hij = IY(i, j, 1); %获取每个像素点的HSV sij = IY(i, j, 2); vij = IY(i, j, 3); if (hij>=p(1) && hij<=p(2)) &&( sij >=p(3)&& sij<=p(4))&&(vij>=p(5)&&vij<=p(6))%若为蓝色像素点 Blue_x(1, j) = Blue_x(1, j) + 1; %记录每一列蓝色像素数目end end
end
PX1=1;PX2=x1;%找到左右边界
while Blue_x(1, PX1)==0PX1=PX1+1;
end
while Blue_x(1, PX2)==0PX2=PX2-1;
end
I1=I(PY1:PY2,PX1:PX2,:);%车牌剪裁
figure(2),subplot(3,1,3),imshow(I1),title('hsv色彩分割法车牌定位结果');
I2=rgb2gray(I1); %将图转化为灰度图
figure(3),subplot(3,1,1),imshow(I2),title('灰度图');
%%%%第二步字符分割前的图像处理(对剪切后的车牌进行处理)%%%%
%%%%边界校正%%%%%
[y,x,z]=size(I2);%I2有y行x列
PX1=round(x*5/440);%根据实际车牌比例,将边框部分去除
PX2=x-round(x*5/440);
PY1=round(y*16/350); %140
PY2=y-round(y*16/120);%140
fprintf('校正后 左边界=%d、右边界=%d、上边界=%d、下边界=%d',PX1,PX2,PY1,PY2);
%彩色图像车牌部分截取
dw=I1(PY1:PY2,PX1:PX2,:);%对边界进行截取
figure(3),subplot(3,1,2),imshow(dw),title('边界校正结果');
imwrite(dw,'dw.jpg');%把截取后的彩色图像新创建一张图片,命名为dw
a=imread('dw.jpg');
b=rgb2gray(a);%将截取后的图片变为灰度图
figure(3),subplot(3,1,3),imshow(b),title('边界校正结果灰度图');
imwrite(b,'1.车牌灰度图像.jpg');
g_max=double(max(max(b)));%得出剪裁后灰度图矩阵的最大值,并变成双精度浮点型
g_min=double(min(min(b)));%得出剪裁后灰度图矩阵的最小值,并变成双精度浮点型
T=round((g_max-(g_max-g_min)/2)-20); % T为二值化的阈值,round用于取整(阈值大小可根据实际图像进行更改)
d=(double(b)>=T); % d:二值图像
imwrite(d,'2.车牌二值图像.jpg');
figure(4),subplot(3,1,1),imshow(d),title('二值图像');
%%%%%%第三步滤波%%%%%%%
h=fspecial('average',3);%创建一个二维滤波器,average是类型,3是参数
d=im2bw(round(filter2(h,d)));%filter2进行滤波处理,im2bw使用阈值变换法把灰度图像转换成二值图像
imwrite(d,'4.均值滤波后.jpg');
figure(4),subplot(3,1,2),imshow(d),title('均值滤波后的图像');
%去点处理
[m,n]=size(d);
d(:,round(n*122/430):round(n*137/430))=0;%去除中间的点
d=bwareaopen(d,65);%用于删除二值图像中面积小于一个定值(此处为65)的对象,默认情况下使用8邻域
figure(4),subplot(3,1,3),imshow(d),title('去点处理');%上下边框处理,找到上下边界处像素值小于20的行,并将整行设为零
s=zeros(1,m);%生成一个1*m的零矩阵
i=1;
while i<=ms(i)=sum(d(i,:));%是求矩阵的一行和i=i+1;
end
j=0;c=zeros(1,m);%c矩阵用于记录下边框处像素值小于20的行,用于确定边框与字符间空隙的位置
while j<mwhile s(j+1)>20&&j<m-1j=j+1;endif j<round(m*12/140) %如果是上边框d((1:j),:)=0;else j>round(m*115/140)%如果是下边框c(j)=j;%将下边界处理中像素值小于20的行记录下来d(j,:)=0;endj=j+1;
end
jj=round(m/2);%这里是为了找到下边界处理中,被记录下来的最小行(即边框和字符间空隙的上沿),所以从中间开始往下找,直到找到的第一个非零数
while c(jj)==0jj=jj+1;
end
d((jj:m),:)=0;%将这一行以下皆设为0
d=imcrop(d,[1 1 n jj]); %1 1为顶点坐标 n为宽,jj为高
figure(5),subplot(3,1,1),imshow(d),title('上下边框处理');
imwrite(d,'5.分割前.jpg');%车牌字符分割
[H,L]=size(d);
w1=0;
while sum(d(:,w1+1))==0 && w1<L %判断出第一个字符的起始位置(因为起始位前面都是黑色 都为0)w1=w1+1;%当前面列和为0时,就将列坐标加一
end
w2=w1;
while sum(d(:,w2+1))~=0 && w2<L %判断出第一个字符的最后位置(因为有字符的地方都是白色 不为0)w2=w2+1;
end
w3=w2;
while (w3-w1)<(L/ 8)%但因为像“川”字,就有中间部分为黑色,故必须让有白色部分的区域大于整个车牌的八等份w3=w3+1;
end
e1=imcrop(d,[w1 1 w3-w1 H]);%w1 1为顶点坐标 w3-w1为宽,H为高
figure(5),subplot(3,1,2),imshow(e1);
title('第一个字符分割');
d=imcrop(d,[w3 1 L-w3 H]); %1 1为顶点坐标 n为宽,jj为高
figure(5),subplot(3,1,3),imshow(d);
title('分割一个字符后的图片');% 分割出第二个字符
[H,L]=size(d);
w1=0;
while sum(d(:,w1+1))==0 && w1<L %判断出第一个字符的起始位置(因为起始位前面都是黑色 都为0)w1=w1+1;%当前面列和为0时,就将列坐标加一
end
w2=w1;
while sum(d(:,w2+1))~=0 && w2<L w2=w2+1;
end
w3=w2;
while (w3-w1)<(L/6)w3=w3+1;
end
e2=imcrop(d,[w1 1 w3-w1 H]);%w1 1为顶点坐标 w3-w1为宽,H为高
figure(6),subplot(4,1,1),imshow(e2);
title('第二个字符分割');
d=imcrop(d,[w3 1 L-w3 H]); %1 1为顶点坐标 n为宽,jj为高
figure(6),subplot(4,1,2),imshow(d);
title('分割两个字符后的图片');
% 分割出第三个字符
[H,L]=size(d);
w1=0;
while sum(d(:,w1+1))==0 && w1<L %判断出第一个字符的起始位置(因为起始位前面都是黑色 都为0)w1=w1+1;%当前面列和为0时,就将列坐标加一
end
w2=w1;
while sum(d(:,w2+1))~=0 && w2<L %判断出第一个字符的最后位置(因为有字符的地方都是白色 不为0)w2=w2+1;
end
w3=w2;
while (w3-w1)<(L/8)w3=w3+1;
end
e3=imcrop(d,[w1 1 w3-w1 H]);%w1 1为顶点坐标 w3-w1为宽,H为高
figure(6),subplot(4,1,3),imshow(e3);
title('第三个字符分割');
d=imcrop(d,[w3 1 L-w3 H]); %1 1为顶点坐标 n为宽,jj为高
figure(6),subplot(4,1,4),imshow(d);
title('分割三个字符后的图片');% 分割出第四个字符
[H,L]=size(d);
w1=0;
while sum(d(:,w1+1))==0 && w1<L %判断出第一个字符的起始位置(因为起始位前面都是黑色 都为0)w1=w1+1;%当前面列和为0时,就将列坐标加一
end
w2=w1;
while sum(d(:,w2+1))~=0 && w2<L w2=w2+1;
end
w3=w2;
while (w3-w1)<(L/4)w3=w3+1;
end
e4=imcrop(d,[w1 1 w3-w1 H]);%w1 1为顶点坐标 w3-w1为宽,H为高
figure(7),subplot(4,1,1),imshow(e4);
title('第四个字符分割');
d=imcrop(d,[w3 1 L-w3 H]); %1 1为顶点坐标 n为宽,jj为高
figure(7),subplot(4,1,2),imshow(d);
title('分割四个字符后的图片');
% 分割出第五个字符
[H,L]=size(d);
w1=0;
while sum(d(:,w1+1))==0 && w1<L %判断出第一个字符的起始位置(因为起始位前面都是黑色 都为0)w1=w1+1;%当前面列和为0时,就将列坐标加一
end
w2=w1;
while sum(d(:,w2+1))~=0 && w2<L %判断出第一个字符的最后位置(因为有字符的地方都是白色 不为0)w2=w2+1;
end
w3=w2;
while (w3-w1)<(L/3)w3=w3+1;
end
e5=imcrop(d,[w1 1 w3-w1 H]);%w1 1为顶点坐标 w3-w1为宽,H为高
figure(7),subplot(4,1,3),imshow(e5);
title('第五个字符分割');
d=imcrop(d,[w3 1 L-w3 H]); %1 1为顶点坐标 n为宽,jj为高
figure(7),subplot(4,1,4),imshow(d);
title('分割五个字符后的图片');% 分割出第六个字符
[H,L]=size(d);
w1=0;
while sum(d(:,w1+1))==0 && w1<L %判断出第一个字符的起始位置(因为起始位前面都是黑色 都为0)w1=w1+1;%当前面列和为0时,就将列坐标加一
end
w2=w1;
while sum(d(:,w2+1))~=0 && w2<L w2=w2+1;
end
w3=w2;
while (w3-w1)<(L/2)w3=w3+1;
end
e6=imcrop(d,[w1 1 w3-w1 H]);%w1 1为顶点坐标 w3-w1为宽,H为高
figure(8),subplot(4,1,1),imshow(e6);
title('第六个字符分割');
e7=imcrop(d,[w3 1 L-w3 H]); %1 1为顶点坐标 n为宽,jj为高
figure(8),subplot(4,1,2),imshow(e7);
title('第七个字符分割');%归一化大小为 40*20
e1=imresize(e1,[40 20]);
e2=imresize(e2,[40 20]);
e3=imresize(e3,[40 20]);
e4=imresize(e4,[40 20]);
e5=imresize(e5,[40 20]);
e6=imresize(e6,[40 20]);
e7=imresize(e7,[40 20]);
%将切割下来短的字符保存为图片
imwrite(e1,'1.jpg');
imwrite(e2,'2.jpg');
imwrite(e3,'3.jpg');
imwrite(e4,'4.jpg');
imwrite(e5,'5.jpg');
imwrite(e6,'6.jpg');
imwrite(e7,'7.jpg');chars={e1,e2,e3,e4,e5,e6,e7};
character=['藏','川','鄂','甘','赣','桂','贵','黑','沪','吉','冀','津','晋','京','辽','鲁','蒙','闽','宁','青','琼','陕','苏','皖','湘','新','渝','豫','粤','云','浙'];
numberAlphabet=['0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F','G','H','K','M','N','L','S','W','J','N','U','Q'];
result=[];
index=ones(1,7);
Num1=length(character);
Num2=length(numberAlphabet);
error=zeros(1,Num1);
error1=zeros(1,Num1);
error2=zeros(1,Num1);error3=zeros(1,Num1);error4=zeros(1,Num1);
Error=zeros(1,Num2);
for i=1:7e=(chars(i));e=cell2mat(e);%转换为二值型g_max=double(max(max(e)));g_min=double(min(min(e)));T=round(g_max-(g_max-g_min)/2); % T为二值化的阈值e=(double(e)>=T); % SegBw2切割下来的字符的二值图像
% [count1,I1] = GetRgbHist(e);% E1=imcrop(e,[1 1 5 20]); %1 1为顶点坐标 n为宽,jj为高
% E2=imcrop(e,[5 1 5 20]);
% E3=imcrop(e,[10 1 5 20]);
% E4=imcrop(e,[15 1 5 20]);
% E5=imcrop(e,[1 20 5 40]); %1 1为顶点坐标 n为宽,jj为高
% E6=imcrop(e,[5 20 5 40]);
% E7=imcrop(e,[10 20 5 40]);
% E8=imcrop(e,[15 20 5 40]);if i==1 for j=1:Num1fname=strcat('标准车牌字符模板\',character(j),'.jpg');%获取模板文件名model=imread(fname);%读取模板图片model=im2bw(model);%转为二值图像im2bwmodel=imresize(model,[40 20]);%规整大小g_max=double(max(max(model)));g_min=double(min(min(model)));T=round(g_max-(g_max-g_min)/2); % T为二值化的阈值model=(double(model)>=T); % SegBw2切割下来的字符的二值图像
% [count2,I2] = GetRgbHist(model);
%
% error(j) = imsimilar(count1,count2,2);
% M1=imcrop(model,[1 1 5 20]); %1 1为顶点坐标 n为宽,jj为高
% M2=imcrop(model,[5 1 5 20]);
% M3=imcrop(model,[10 1 5 20]);
% M4=imcrop(model,[15 1 5 20]);
% M5=imcrop(model,[1 20 5 40]); %1 1为顶点坐标 n为宽,jj为高
% M6=imcrop(model,[5 20 5 40]);
% M7=imcrop(model,[10 20 5 40]);
% M8=imcrop(model,[15 20 5 40]);
% error1(j)=sum(sum(abs(E1-M1)));
% error2(j)=sum(sum(abs(E2-M2)));
% error3(j)=sum(sum(abs(E3-M3)));
% error4(j)=sum(sum(abs(E4-M4)));
% error5(j)=sum(sum(abs(E5-M5)));
% error6(j)=sum(sum(abs(E6-M6)));
% error7(j)=sum(sum(abs(E7-M7)));
% error8(j)=sum(sum(abs(E8-M8)));
% % error1(j)=abs((corr2(E1,M1))-1);
% % error2(j)=abs((corr2(E2,M2))-1);
% % error3(j)=abs((corr2(E3,M3))-1);
% % error4(j)=abs((corr2(E4,M4))-1);
% error(j)=0.05*error1(j)+0.2*error2(j)+0.2*error3(j)+0.05*error4(j)+0.2*error6(j)+0.2*error7(j)+0.05*error7(j)+0.05*error8(j);error(j)=sum(sum(abs(e-model)));%计算当前图片与模板图差值
% error(j)=abs((corr2(e,model))-1);endbest=min(error);%差值最小的作为匹配结果保存index(i)=find(error==best);%获取匹配模板索引,找到error中等于best值的位置result=character(index(i));%输出匹配结果字符elsefor j=1:Num2fname=strcat('标准车牌字符模板\',numberAlphabet(j),'.jpg');model=imread(fname);model=im2bw(model);model=imresize(model,[40 20]);%规整大小g_max=double(max(max(model)));g_min=double(min(min(model)));T=round(g_max-(g_max-g_min)/2); % T为二值化的阈值model=(double(model)>=T); % SegBw2切割下来的字符的二值图像Error(j)=sum(sum(abs(e-model)));
% Error(j)=abs((corr2(e,model))-1);endbest=min(Error);index(i)=find(Error==best);result=[result,numberAlphabet(index(i))];end
end% %%%%字符识别%%%%
% %建立自动识别字符代码表
% liccode=char(['0':'9' 'A':'H' 'J':'N' 'P':'Z' '藏川鄂甘赣桂贵黑沪吉冀津晋京辽鲁蒙闽宁青琼陕苏皖湘新渝豫粤云浙']); %建立自动识别字符代码表
% SubBw2=zeros(40,20);
% l=1;
% for I=1:7
% ii=int2str(I);%将整形变成字符串
% t=imread([ii,'.jpg']);
% SegBw2=imresize(t,[40 20],'nearest');
% %进行二值化,方便比较
% g_max=double(max(max(SegBw2)));
% g_min=double(min(min(SegBw2)));
% T=round(g_max-(g_max-g_min)/2); % T为二值化的阈值
% SegBw2=(double(SegBw2)>=T); % SegBw2切割下来的字符的二值图像
%
% if l==1 %第一位汉字识别
% kmin=35;
% kmax=65;
% elseif l==2 %第二位 A~Z 字母识别
% kmin=11;
% kmax=34;
% else l>=3; %第三位以后是字母或数字识别
% kmin=1;
% kmax=34;
%
% end
%
% %在每一位对应区间按顺序提取字符模板
% for k2=1:65
% fname=strcat('标准车牌字符模板\',liccode(k2),'.jpg');
% SamBw2 = imread(fname);
% SamBw2=im2bw(SamBw2);
% % if(k2~=2)
% % SamBw2=rgb2gray(SamBw2);
% % end
% g_max=double(max(max(SamBw2)));%二值化处理字符模板
% g_min=double(min(min(SamBw2)));
% T=round(g_max-(g_max-g_min)/2); % T为二值化的阈值
% SamBw2=(double(SamBw2)>=T); % SamBw2为字符模板的二值图像
%
% %字符图像与模板进行比较
% a1(k2)=corr2(SegBw2,SamBw2);
% end
%
% A1=a1(kmin:kmax);%将比较结果放入矩阵A1
% MaxA1=max(A1);%找到比较结果最大值
% findc=find(A1==MaxA1);%获取最大值所在位置
% Code(I*2-1)=liccode(findc+kmin-1);
% Code(I*2)=' ';
% I=I+1;%进行下一字符的提取和比较
% end
figure(9),subplot(2,7,1:7),imshow(dw),title('车牌定位结果'),
xlabel({'','车牌切割结果'});
subplot(2,7,8),imshow(e1);
subplot(2,7,9),imshow(e2);
subplot(2,7,10),imshow(e3);
subplot(2,7,11),imshow(e4);
xlabel(['识别结果为: ', result]);
subplot(2,7,12),imshow(e5);
subplot(2,7,13),imshow(e6);
subplot(2,7,14),imshow(e7);测试结果图如下:





不要再问为什么用的同样的程序 同样的图片 也识别不出来了 那么多中文注释 仔细看看叭 上面这些图片结果也不是我编出来的把
工程文件上传至qq群:868412045