首先声明,这只是本人自己对HyperLPR代码的看法解析可能会有错还请多多谅解。
先贴上HyperLPR源码的链接HyperLPR
其中最有用的其实就是HyperLPRLite.py这个代码文件,原来Github上的使用教程可能有点老了不太适用,这边附上一个简单的demo使用,创建一个新的文件夹然后把HyperLPRLite.py放进文件夹,再在新文件夹里面创建一个demo.py文件,如下(记得要把xml,两个h5文件一起放进去)
import sys
from PIL import ImageFont
from PIL import Image
from PIL import ImageDraw
import HyperLPRLite as pr
import cv2
import numpy as np
import time
import importlibdef visual_draw_position(grr):max=0model = pr.LPR("model/cascade.xml","model/model12.h5","model/ocr_plate_all_gru.h5")for pstr,confidence,rect in model.SimpleRecognizePlateByE2E(grr):if 1:max=confidencegrr = drawRectBox(grr, rect, pstr+" "+str(round(confidence,3)))print("车牌号:")print(pstr)print("置信度")print(confidence)cv2.imshow("image",grr)cv2.waitKey(0)test_image = cv2.imread("C://Users//dell//Desktop//Cars//30.jpg")
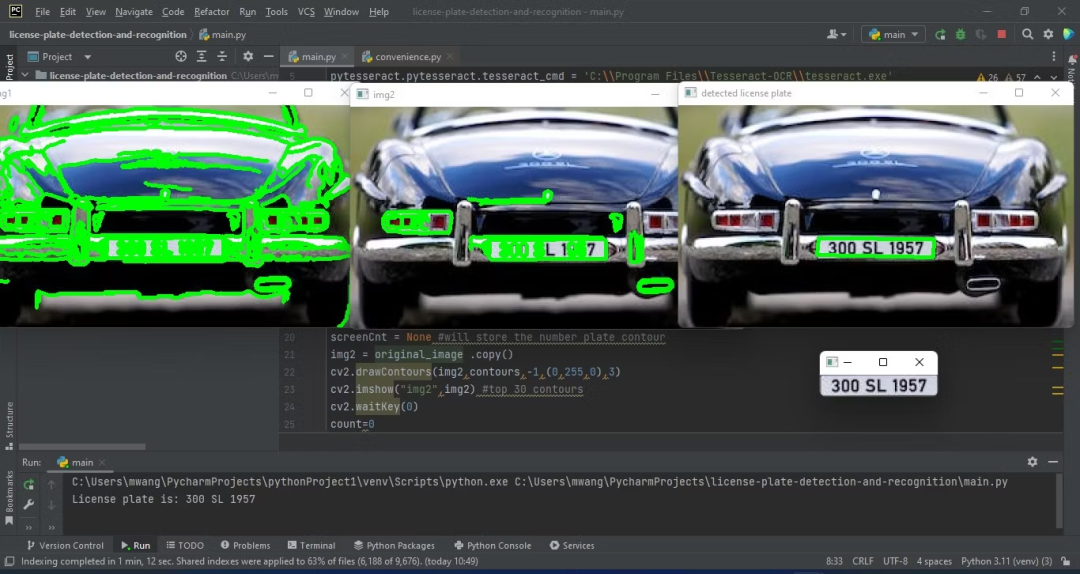
visual_draw_position(test_image)
以上就可以简单的使用HyperLPR这个开源的车牌识别库
现在进入正题我们来看一下HyperLPRLite.py这个重要文件里面写的内容
接下来我会按照代码执行的顺序来解读各个函数的作用
其实这份代码总共分为三大部分:粗定位,精定位,车牌信息识别
1、车牌粗定位
def computeSafeRegion(self,shape,bounding_rect): #该函数是初步的框出车牌的大概位置属于粗定位出一个保险的包含车牌的大小top = bounding_rect[1] # ybottom = bounding_rect[1] + bounding_rect[3] # y + hleft = bounding_rect[0] # xright = bounding_rect[0] + bounding_rect[2] # x + wmin_top = 0max_bottom = shape[0]min_left = 0max_right = shape[1]if top < min_top:top = min_topif left < min_left:left = min_leftif bottom > max_bottom:bottom = max_bottomif right > max_right:right = max_rightreturn [left,top,right-left,bottom-top]def cropImage(self,image,rect): #框出车牌识别的区域x, y, w, h = self.computeSafeRegion(image.shape,rect)return image[round(y):y+h,round(x):x+w]#返回所有车牌的boxdef detectPlateRough(self,image_gray,resize_h = 720,en_scale =1.08 ,top_bottom_padding_rate = 0.05):if top_bottom_padding_rate>0.2:print("error:top_bottom_padding_rate > 0.2:",top_bottom_padding_rate)exit(1)height = image_gray.shape[0]padding = int(height*top_bottom_padding_rate)scale = image_gray.shape[1]/float(image_gray.shape[0])image = cv2.resize(image_gray, (int(scale*resize_h), resize_h))image_color_cropped = image[padding:resize_h-padding,0:image_gray.shape[1]]image_gray = cv2.cvtColor(image_color_cropped,cv2.COLOR_RGB2GRAY)watches = self.watch_cascade.detectMultiScale(image_gray, en_scale, 2, minSize=(36, 9),maxSize=(36*40, 9*40))cropped_images = []for (x, y, w, h) in watches:x -= w * 0.14w += w * 0.28y -= h * 0.15h += h * 0.3cropped = self.cropImage(image_color_cropped, (int(x), int(y), int(w), int(h)))cropped_images.append([cropped,[x, y+padding, w, h]])return cropped_images
这个地方的重点是detectPlateRough()函数,首先开始的时候会对图像进行一些插补还有调整图像大小比例操作(其实个人认为这些不是很必要),然后核心的一部就是这个Cascade级联分类器的应用,这才是核心。这里的级联分类器是基于Haar+Adaboost构成的。很重要的就是之前的cascade.xml文件,这个文件里面存放的都是车牌的Haar特征。
在这里我们采用了cascade.xml 检测模型——目前效果最好的cascad级联检测模型。然后使用OpenCV的detectMultiscale的方法来对图像进行滑动窗口遍历寻找车牌,实现粗定位。detectMultiscale函数为多尺度多目标检测:多尺度:通常搜索目标的模板尺寸大小是固定的,但是不同图片大小不同,所以目标对象的大小也是不定的,所以多尺度即不断缩放图片大小(缩放到与模板匹配),通过模板滑动窗函数搜索匹配;同一副图片可能在不同尺度下都得到匹配值,所以多尺度检测函数detectMultiscale是多尺度合并的结果。
简单来讲就是cascade.xml这个文件是通过很多的正样本车牌图片和负样本非车牌图片然后经过一个exe的程序可以创建出一个cascade.xml文件其中文件里Haar特征数据已经过Adaboost处理。最后通过这个xml文件就可以训练出一个级联分类器分类器的判别车牌标准是通过计算好多车牌特征后得出的一个阈值,大于这个阈值判别为车牌。这就是这个函数大概的功能,其中有一些框选图像中车牌的部分的功能比较基础此处不讲。

推荐原作者的讲解:HyperLPR车牌识别技术算法之车牌粗定位与训练
2、车牌精定位
def model_finemapping(self):input = Input(shape=[16, 66, 3]) # change this shape to [None,None,3] to enable arbitraty shape inputx = Conv2D(10, (3, 3), strides=1, padding='valid', name='conv1')(input)x = Activation("relu", name='relu1')(x)x = MaxPool2D(pool_size=2)(x)x = Conv2D(16, (3, 3), strides=1, padding='valid', name='conv2')(x)x = Activation("relu", name='relu2')(x)x = Conv2D(32, (3, 3), strides=1, padding='valid', name='conv3')(x)x = Activation("relu", name='relu3')(x)x = Flatten()(x)output = Dense(2,name = "dense")(x)output = Activation("relu", name='relu4')(output)model = Model([input], [output])return modeldef finemappingVertical(self,image,rect):resized = cv2.resize(image,(66,16))resized = resized.astype(np.float)/255#cv2.imshow("wd", resized)res_raw= self.modelFineMapping.predict(np.array([resized]))[0]#这里会返回两个值print(self.modelFineMapping.predict(np.array([resized])))res =res_raw*image.shape[1]res = res.astype(np.int)H,T = resH-=3if H<0:H=0T+=2;if T>= image.shape[1]-1:T= image.shape[1]-1rect[2] -= rect[2]*(1-res_raw[1] + res_raw[0])rect[0]+=res[0]cv2.imshow("ww",image)image = image[:,H:T+2]cv2.imshow("wd",image)image = cv2.resize(image, (int(136), int(36)))return image,rect
model12.h5这是这部分左右边界回归模型
这里的精定位其实就是切掉原来上面粗定位出来车牌的多余部分,这里用到了一个CNN网络来实现左右边届切除点的预测也就是self.modelFineMapping.predict()这个函数他会返回两个值两个小数值,左右边界分别要切除多少。其实这部分我有点迷,我不太懂如何利用CNN网络来训练出得到两个切除边界的值,因为一般往往CNN网络用来做图像中分类较多,至少对我来说我很少看到CNN拿来做回归。所以在这一部分我不是很看懂。
这里附上原作者的:HyperLPR车牌识别技术算法之车牌精定位
3、车牌信息识别
def fastdecode(self,y_pred):results = ""confidence = 0.0table_pred = y_pred.reshape(-1, len(chars)+1)res = table_pred.argmax(axis=1)for i,one in enumerate(res):if one<len(chars) and (i==0 or (one!=res[i-1])):results+= chars[one]confidence+=table_pred[i][one]confidence/= len(results)return results,confidencedef model_seq_rec(self,model_path):width, height, n_len, n_class = 164, 48, 7, len(chars)+ 1 #输入层为164*48*3的tensor,类别有len(chars)+1个rnn_size = 256input_tensor = Input((164, 48, 3))x = input_tensorbase_conv = 32for i in range(3): #一共做了三次卷积池化x = Conv2D(base_conv * (2 ** (i)), (3, 3))(x) #卷积层x = BatchNormalization()(x) #统一量纲防止网络失衡x = Activation('relu')(x) #采用RELU激活函数x = MaxPooling2D(pool_size=(2, 2))(x) #池化层conv_shape = x.get_shape()x = Reshape(target_shape=(int(conv_shape[1]), int(conv_shape[2] * conv_shape[3])))(x)x = Dense(32)(x) #全连接层x = BatchNormalization()(x)x = Activation('relu')(x)gru_1 = GRU(rnn_size, return_sequences=True, kernel_initializer='he_normal', name='gru1')(x)gru_1b = GRU(rnn_size, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru1_b')(x)gru1_merged = add([gru_1, gru_1b])gru_2 = GRU(rnn_size, return_sequences=True, kernel_initializer='he_normal', name='gru2')(gru1_merged)gru_2b = GRU(rnn_size, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', name='gru2_b')(gru1_merged)x = concatenate([gru_2, gru_2b])x = Dropout(0.25)(x) #正则化,扔掉25%的隐层神经元x = Dense(n_class, kernel_initializer='he_normal', activation='softmax')(x) #再一次全连接,最后使用softmax输出类别数的网络base_model = Model(inputs=input_tensor, outputs=x)base_model.load_weights(model_path)return base_modeldef recognizeOne(self,src):x_tempx = srcx_temp = cv2.resize(x_tempx,( 164,48))x_temp = x_temp.transpose(1, 0, 2)y_pred = self.modelSeqRec.predict(np.array([x_temp]))y_pred = y_pred[:,2:,:]return self.fastdecode(y_pred)
此处的车牌字符信息识别事实上是采用了OCR光学字符识别技术也就是在不分割字符的前提下能够识别出车牌一共七个字符。当然传统的车牌字符识别就是先分割字符然后再逐一使用分类算法进行识别。这种方法有个好处就是,仅仅需要较少的字符样本即可用于分类器的训练。在光照,相机条件好的情况下也能取得较好的效果。现在大多数商业车牌识别软件采用的也是这种方法。但是在某些恶劣的自然情况下,车牌字符的分割和识别变得尤其的困难,传统的方法并不能取得很好的结果。这时候我们就能考虑下是否能整体一起识别。当然我们注意到车牌字符的数量是固定的,对于中国车牌而言,车牌一直是7个字符。我们就可以采用多标签分类的方法直接输出多个标签。

但是这种方法有个很大的缺点,就是需要大量的样本,样本需要涵盖所有的省份和地区。这就为样本的收集造成的极大的困难
这里采用CNN+GRU的方法来实现
GRU:(我个人理解CNN网络是初步的对字符进行分类,而GRU实际是并不常用在分类上,GRU更多用在预测处理上,我个人认为这里运用了双向GRU是为了在车牌图片较为模糊时,也可以大概预测出一个字符类别就是经过G双向GRU后可以更好的预测)
GRU(Gated Recurrent Unit) 是由 Cho, et al. (2014) 提出,是LSTM的一种变体。GRU的结构与LSTM很相似,LSTM有三个门,而GRU只有两个门且没有细胞状态,简化了LSTM的结构。而且在许多情况下,GRU与LSTM有同样出色的结果。GRU有更少的参数,因此相对容易训练且过拟合问题要轻一点。
下图展示了GRU的网络结构,GRU的网络结构和LSTM的网络结构很相似,LSTM中含有三个门结构和细胞状态,而GRU只有两个门结构:更新门和重置门,分别为图中的z_t和r_t,结构上比LSTM简单。把GRU看着LSTM的变体,相当于取消了LSTM中的cell state,只使用了hidden state,并且使用update gate更新门来替换LSTM中的输入们和遗忘门,取消了LSTM中的输出门,新增了reset gate重置门。这样做的好处是在达到LSTM相近的效果下,GRU参数更少,训练的计算开销更小,训练速度更快。
这里在CNN的训练模型后加上的是双向GRU

以上就是我对于HyperLPR代码的理解,如有不足之处,请勿喷!蟹蟹!