文章目录
- 摘要
- 一、Introduction
- 1、引入原因
- 2、结构框架
- 二、相关工作
- 1、新闻推荐算法
- 2、推荐中的强化学习
- 3、问题定义
- 三、实现原理
- 1、模型框架
- 2、特征构造
- 3、深度强化推荐Deep Reinforcement Recommendation
- 4、用户活跃度
- 5、探索
- 四、实验结果
- 1、数据集
- 2、评价指标
- 3、实验设置
- 4、性能比较
- 五、总结
- 相关文献
摘要
本文提出了一种新的新闻推荐深度强化学习框架。由于新闻特性和用户偏好的动态性,在线个性化新闻推荐是一个极具挑战性的问题。虽然有人提出了一些在线推荐模型来解决新闻推荐的动态性,但这些方法存在三个主要问题。
- 首先,他们只尝试模拟当前的奖励(例如,点击率)。
- 其次,很少有研究考虑使用点击/不点击标签以外的用户反馈(例如,用户返回的频率)来帮助改进推荐。
- 这些方法倾向于不断向用户推荐类似的新闻,这可能会让用户感到无聊。
本文创新之处:
- 提出了一个基于深度Q-Learning的推荐框架,该框架可以明确地建模未来的奖励。
- 进一步考虑用户返回模式作为点击/不点击标签的补充,以获取更多的用户反馈信息。
- 此外,还加入了有效的探索策略,为用户寻找新的有吸引力的新闻。
一、Introduction
1、引入原因
原有的推荐算法有以下几个问题解决不了:
问题一:
新闻推荐的动态变化很难处理。新闻推荐的动态变化主要表现在两个方面。
- 新闻很快就会过时。在我们的数据集中,一条新闻发布到最后一次点击之间的平均时间是4.1小时,推荐候选池变化是非常迅速的。
- 用户对不同新闻的兴趣可能会随着时间的推移而变化。因此,有必要定期更新模型。虽然有一些网上的推荐方法,可以捕捉新闻的动态变化特性和用户偏好模型通过在线更新,他们只是试图优化当前的奖励(例如,点击率),因此忽略当前的建议可能会带来什么影响未来。
下面举一个例子来说明考虑未来必要性的例子。
当用户Mike请求新闻时,推荐代理会预测他有几乎相同的概率点击两条新闻:一条是关于雷雨警报的,另一条是关于篮球运动员科比·布莱恩特的。但是,根据Mike的阅读偏好,新闻的特点,以及其他用户的阅读模式,我们的代理推测,Mike在阅读了关于雷雨的新闻后,将不再需要阅读关于这个alert的新闻,但是在阅读了关于科比的新闻后,他可能会关于篮球的信息。这表明,推荐后一条消息会带来更大的未来回报。因此,从长远来看,考虑未来的奖励将有助于提高推荐性能。
下图就是用户兴趣的变化情况。

问题二:
当前的推荐算法通常只考虑用户的点击/未点击,或者 用户的评分作为反馈。然而,用户隔多久会再次使用服务也能在一定程度上反映用户对推荐结果的满意度。
问题三:
模型很容易推荐相似的内容给用户。之前有两种办法来缓解这个问题:
- ϵ \epsilon ϵ-greedy策略,但它会推给用户完全不相关的内容
- UCB,但是它的响应时间很长,需要重复点击一个item很多次才能给出一个准确的reward。
本文的解决方法是
- 引入DQN框架来更好的学习新闻动态特征和用户偏好,因为DQN能同时考虑current reward和future reward。MAB-based方法不能清晰地给出future reward,MDP-based方法不适用于大规模数据。
- 引入用户返回APP的情况转化为用户活跃度,作为用户反馈信息。可以在任意时刻计算用户活跃度。
- exploration时采用Dueling Bandit Gradient Descent(DBGD)方法来挑选当前推荐环境下的候选items,方法是在当前推荐器的邻域内随机选择候选项。这种探索策略可以避免推荐完全不相关的项目,从而保持更好的推荐准确性。
2、结构框架
深度强化推荐系统如下图所示。在系统中,用户池和新闻池构成了环境,推荐算法扮演代理的角色。状态定义为用户的特征表示,动作定义为新闻的特征表示。每当用户请求新闻时,一个状态表示(即和一组动作表示(即,新闻考生的特征)被传递给代理。代理将选择最佳操作(即,向用户推荐新闻列表),获取用户反馈作为奖励。具体来说,奖励是由点击标签和用户活跃度评估组成的。所有这些推荐和反馈日志都将存储在代理的内存中。每隔一小时,代理将使用内存中的日志更新其推荐算法。

简单概括一下:
用户点击情况就是实时reward,用户活跃度(用户在一次推荐后返回应用程序的频率)就是future reward,state表示的用户特征以及用户行为特征,action是新闻候选池的特征,这样就构成了强化学习的基本框架。
二、相关工作
1、新闻推荐算法
推荐系统因其与产品利润的直接关系而被广泛研究。近年来,随着网络内容的爆炸式增长,推荐的一种特殊应用——网络个性化新闻推荐受到了越来越多的关注。传统的新闻推荐方法可以分为三类。
基于内容的方法将维护新闻词频特征(例如TF-IDF)和用户概况(基于历史新闻)。然后,推荐人会选择更接近用户资料的新闻。
相比之下,协同过滤方法通常利用当前用户或相似用户的过去评级,或结合这两种进行评级预测。为了结合前两组方法的优点,进一步提出混合方法来改进用户配置文件建模。
近年来,深度学习模型[1,2,3]作为对以往方法的扩展和集成,由于能够对复杂的用户-项目关系进行建模,其性能远远优于前三种模型。
与建模用户与物品之间复杂交互的工作不同,我们的算法侧重于处理在线新闻推荐的动态特性,以及对未来奖励的建模。然而,这些特征构造和用户-项目建模技术可以很容易地集成到我们的方法中。
2、推荐中的强化学习
主要分为两类
- 基于Contextual Multi-Armed Bandit models
- 基于Markov Decision Process models.
3、问题定义
我们将我们的问题定义为:当用户u在时间t向推荐代理G发送一个新闻请求时,给定一个新闻候选集I,我们的算法将为该用户选择一个top-k合适的新闻列表L。本文使用的表示法如表1所示。

三、实现原理
1、模型框架
如下图所示,我们的模型由离线部分和在线部分组成。
离线部分,模型采用了用户记录日志的新闻级别和用户级别的4类特征作为输入,计算DQN的reward。该网络使用离线用户-新闻单击日志进行训练。
在线学习部分,我们的推荐代理G将与用户进行交互,并按照以下四步更新网络:
- PUSH:t1时刻用户u发出请求,agent利用u和新闻候选池作为输入,生成top k个推荐列表L
- FEEDBACK:当用户有点击行为时就生成了反馈信息B
- MINOR UPDATE(小调):t1时刻后,agent利用该用户u,生成的L和反馈信息B,比较exploitation(开发)网络Q和exploration(探索)网络Q’,选择更好的那个
- MAJOR UPDATE(大调):在经过某一个固定的时期Tr后,agent利用反馈信息B和memory存储的用户活跃度采样来更新Q(memory中存储近期的历史点击记录和用户活跃度分值)
- 重复步骤1-4。

2、特征构造
为了预测用户是否会点击某条特定的新闻,构建了以下四类特征:
- 新闻特征:417维的one hot特征,包括标题,供应商,排名,实体名称,类别,主题类别,以及在过去1小时,6小时,24小时,1周,和1年内的点击数。这里每个点击数(click count)是1维,其余的特征总共412维,不知道分别是多少维的。
- 用户特征:413*5维: 在1 hour, 6 hours, 24 hours, 1 week, and 1 year里用户点击过的新闻的标题、提供者、排名、实体名称、类别、主题类别等(这些是412维) 再加上一个总的点击数,共413维。
- 用户-新闻特征:25维,在该用户的所有浏览记录中category, topic category and provider的出现频率,描述了用户和某条新闻之间的交互情况。
- 上下文特征:32维,描述了新闻请求发生时的上下文,包括时间、工作日和新闻的新鲜度(请求时间和新闻发布时间之间的差距)等。
为了重点分析强化学习推荐框架,我们没有尝试添加更多的功能,例如文本功能[4]。但是它们可以很容易地集成到我们的框架中,从而获得更好的性能。
3、深度强化推荐Deep Reinforcement Recommendation
考虑到之前提到的新闻推荐的动态特性和对未来奖励的估计需求,我们使用DQN来建模一个用户点击一个特定新闻的概率。在强化学习的设置下,用户点击一条新闻(以及未来的推荐新闻)的概率本质上是我们的agent所能获得的奖励。因此,我们可以将总回报模型化为公式:
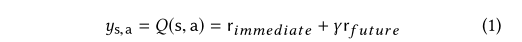
其中状态s由上下文特征和用户特征表示,动作a由新闻特征和用户-新闻交互特征表示,rimmediat将当前情况的奖励(例如,用户是否点击这条新闻)呈现出来,rfuture将代理对未来奖励的预测呈现出来。γ是一个折扣因子,用来平衡即时回报和未来回报的比重。
具体来说,给定s为当前状态,我们使用Double-DQN目标来预测总回报,在时间戳t处采取行动a,如式2所示
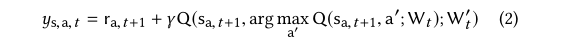
其中ra,t+1表示通过采取行动a获得的即时奖励(下标t+1是因为奖励总是延迟1)这里,
W t W_ t Wt和 W t ′ W_t' Wt′分别是是Q和Q’的参数。
在这个公式中,在动作a被选定后,agent G将推测下一个状态sa,t+1。在此基础上,给定一个动作候选集合{a '},根据参数 W t W_ t Wt选择未来奖励最大的动作a ',然后根据 W t ′ W_t' Wt′计算给定状态sa、t+1的未来奖励估计值。这个策略已经被证明可以消除对Q的过高估计。
通过这个过程,在下一个状态 s a , t + 1 s_{a,t+1} sa,t+1时,agent会产生一系列候选的action {a’},能带来对最大reward的a’所对应的参数W’就会替换掉当前的W。
下图显示了特征的输入形式,状态s由上下文特征和用户特征表示,动作a由新闻特征和用户-新闻交互特征表示。
值函数由静态的用户特征和环境特征构成,行为函数由静态动态的全部特征构成,即,V(s)仅由状态特征决定,A(s,a)由状态特征和动作特征共同决定。

4、用户活跃度
当产生用户请求时,就被标记为user return的时刻(这里有一点疑问,如果是用户在一段时间内连续多次刷新呢?)
采用生存模型进行拟合,生存模型[5,6]已被应用于估计用户返回时间的领域。
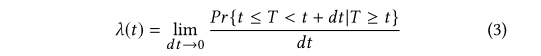
所以经过t时间后事件发生的概率为
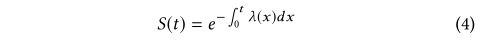
其预计寿命为:
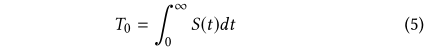
函数的图象大概长这样,意义就比较明确了,最大值不超过1,初始化值是0.5,阶跃的点就代表发生了用户请求

参数S0、Sa、λ0 T0是根据我们数据集的实际用户模式决定的。将s0设置为0.5表示用户的随机初始状态(即,他或她可以是活跃的或不活跃的)。我们可以观察到用户每两个连续请求之间的时间间隔直方图,如下图所示。我们观察到,除了每天多次阅读新闻外,人们通常还会定期返回应用程序。所以我们设定为24小时。λ0衰减参数设置为1.2×10−5秒−1每点击一次,用户的活跃度Sa增加0.32,以确保用户在每天的基本请求后返回初始状态,也就是:
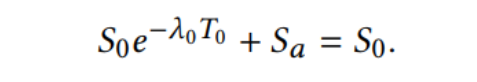
用户点击与否的标签 r c l i c k r_{click} rclick和用户活跃度的标签 r a c t i v e r_{active} ractive通过下式进行整合。
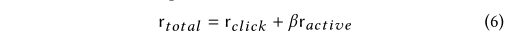
虽然我们在这里使用生存模型来估计用户的活跃度,但是其他的替代方法如泊松点流程也可以应用,并且应该具有类似的功能。
5、探索
通过采用阐述了DQN如何选取候选列表L的过程


四、实验结果
1、数据集
从一个商业新闻推荐应用程序中采集了一个采样的离线数据集进行实验,并将我们的系统在线部署到该应用程序中一个月。当新闻请求到达时,每个推荐算法都会给出自己的推荐,用户的反馈会被记录下来(点击与否)。抽样数据的基本统计如表2所示。在第一个离线阶段,训练数据和测试数据按时间顺序分开(最后两周作为测试数据),使在线模型能够更好地学习不同会话之间的顺序信息。在第二个在线部署阶段,我们使用离线数据对模型进行预训练,并在实际生产环境中运行所有比较的方法。
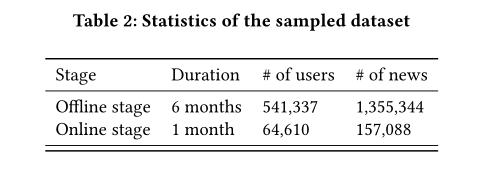
如下图所示,数据集非常倾斜。每个用户的请求数量遵循长尾分布,大多数用户只请求不到500次的新闻。每个新闻推送的次数也遵循长尾分布,大多数新闻推送给用户的次数不超过200次。

2、评价指标
用了点击率CTR、precision、nDCG
3、实验设置
通过参数空间的网格搜索(grid search of parameter space)来确定参数,从而找到最佳的CTR。具体设置如表3所示。

4、性能比较
离线评估


在线评估


五、总结
提出了一个强化学习框架来做在线个性化新闻推荐。与之前的研究不同的是,该框架采用了DQN结构,可以兼顾当前和未来的回报。虽然我们关注的是新闻推荐,但是我们的框架可以推广到很多其他的推荐问题。
我们考虑用户的活跃度来帮助提高推荐的准确性,这比简单地使用用户点击标签可以提供额外的信息。
我们将有效的探索策略应用到我们的框架中,以提高推荐的多样性,并寻找潜在的更有价值的推荐。
我们的系统已经在线部署在一个商业新闻推荐应用程序中。大量的离线和在线实验表明,我们的方法性能优越。
相关文献
[1] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra,
Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al.
2016. Wide & deep learning for recommender systems. In Proceedings of the 1st
Workshop on Deep Learning for Recommender Systems. ACM, 7–10.
[2] Xuejian Wang, Lantao Yu, Kan Ren, Guanyu Tao, Weinan Zhang, Yong Yu, and
Jun Wang. 2017. Dynamic Attention Deep Model for Article Recommendation
by Learning Human Editors’ Demonstration. In Proceedings of the 23rd ACM
SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM,
2051–2059.
[3]Lei Zheng, Vahid Noroozi, and Philip S Yu. 2017. Joint deep modeling of users
and items using reviews for recommendation. In Proceedings of the Tenth ACM
International Conference on Web Search and Data Mining. ACM, 425–434.
[4]Xuejian Wang, Lantao Yu, Kan Ren, Guanyu Tao, Weinan Zhang, Yong Yu, and
Jun Wang. 2017. Dynamic Attention Deep Model for Article Recommendation
by Learning Human Editors’ Demonstration. In Proceedings of the 23rd ACM
SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM,
2051–2059.
[5]Joseph G Ibrahim, Ming-Hui Chen, and Debajyoti Sinha. 2005. Bayesian survival
analysis. Wiley Online Library.
[6]Rupert G Miller Jr. 2011. Survival analysis. Vol. 66. John Wiley & Sons.
参考:
DRN: A Deep Reinforcement Learning Framework for News Recommendation
https://blog.csdn.net/weixin_41864878/article/details/90080576


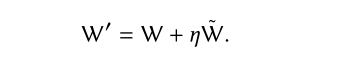








![关于CSRF攻击及mvc中的解决方案 [ValidateAntiForgeryToken]](https://img-my.csdn.net/uploads/201212/05/1354701750_7294.jpg)