一、solrcloud介绍
solrcloud是solr提供的分布式的搜索方案,当我们需要大规模,容错,分布式搜索和索引时使用solrcloud。当系统的索引量少,请求并发性低的时候不需要用到solrcloud。solrcloud是基于solr和zookeeper的分布式搜索方案,使用zookeeper作为集群的配置信息中心。
特色功能:
1、集中式的配置信息。
使用ZK进行集中配置。启动时可以指定把Solr的相关配置文件上传 Zookeeper,多机器共用。这些ZK中的配置不会再拿到本地缓存,Solr直接读取ZK中的配置信息。配置文件的变动,所有机器都可以感知到。
2、自动容错
SolrCloud对索引分片,并对每个分片创建多个Replication。每个 Replication都可以对外提供服务。一个Replication挂掉不会影响索引服务。更强大的是,它还能自动的在其它机器上帮你把失败机器上的索引Replication重建并投入使用。
3、近实时搜索
可以在秒内检索到新加入索引。
4、查询时自动负载均衡
SolrCloud索引的多个Replication可以分布在多台机器上,均衡查询压力。如果查询压力大,可以通过扩展机器,增加Replication来减缓。
系统架构图如下:

1、物理结构
需要三个solr服务器,每个服务器包含两个core
2、逻辑结构
索引集合由两个分片组成,每个分片包含了三个core,一个leader,两个replication,leader由zookeeper选举产生,zookeeper控制着一个分片上的三个core的一致性,解决高可用问题。
二、solrcloud伪集群搭建
solrcloud伪集群的搭建可以参考这篇文章:http://www.linuxidc.com/Linux/2017-12/149941.htm,我自己也搭建了一个solrcloud的伪集群服务器。下载链接如下:http://download.csdn.net/download/liuyuanq123/10213445
我们搭建的是一个简化版的伪集群,架构图类似下图:

我们需要三台zookeeper服务器和4个solr服务器,每个服务器一个core,一主一从,分为两片,组成一个集合。
zookeeper在这里扮演的角色:
1、集群管理:容错,负载均衡
2、几种管理配置文件
3、集群的统一入口
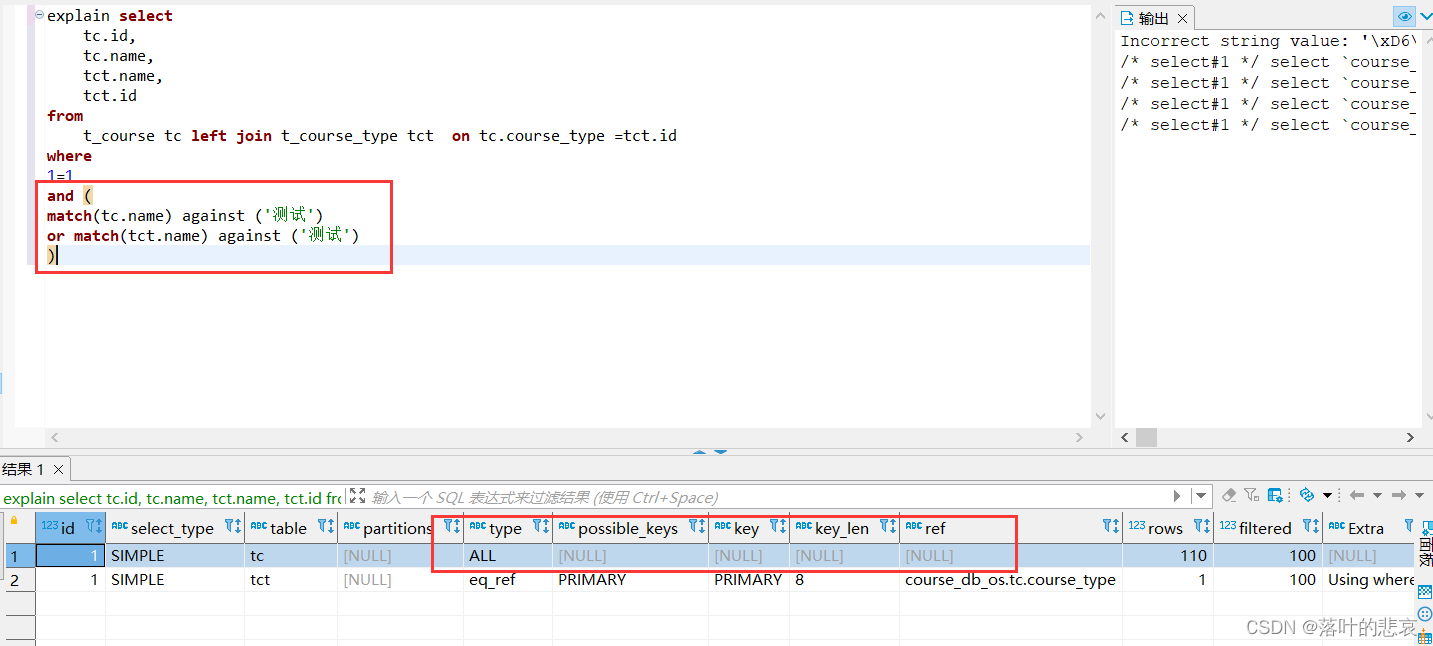
三、solrj测试
最后我们使用solrj来测试集群,代码如下:
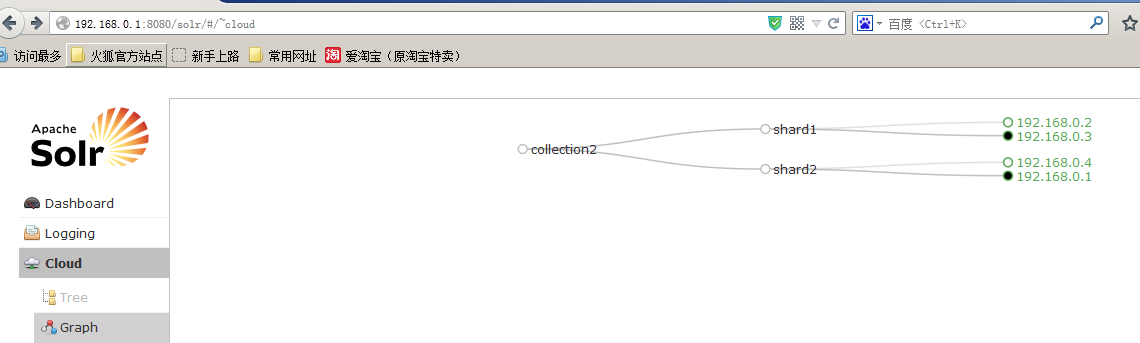
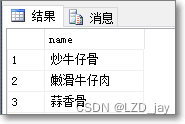
@Testpublic void testSolrCloud() throws Exception{//创建CloudSolrserver对象CloudSolrServer server = new CloudSolrServer("192.168.156.33:2181,192.168.156.33:2182,192.168.156.33:2183,");//设置默认的collectionserver.setDefaultCollection("collection2");//创建文本对象SolrInputDocument sInputDocument = new SolrInputDocument();//向文本对象中添加域sInputDocument.addField("id", "test0001");sInputDocument.addField("title", "大大方方");sInputDocument.addField("item_sell_point", "测试卖点");sInputDocument.addField("item_price", 500);sInputDocument.addField("item_category_name","测试" );sInputDocument.addField("item_desc", "测试描述");//将文本对象添加到索引库server.add(sInputDocument);//提交server.commit();}然后我们打开服务器并查看结果:

可以看到我们已经添加成功。