-
-
- SSD:SingleShotMultiBoxDetector
- 简介
- one-stage、基于回归的目标检测,74.3mAP、59FPS ( on VOC2007 test )
- 网络结构
-
- SSD 300中输入图像的大小是300x300,特征提取部分使用了VGG16的卷积层,并将VGG16的两个全连接层转换成了普通的卷积层(图中conv6和conv7)。由SSD的网络结构可以看出,SSD使用6个不同特征图检测不同尺度的目标。低层预测小目标,高层预测大目标
-
- 主要特点
- 同时使用多个卷积层的输出(6个)来做分类和位置回归
- 边界框(bound ing boxs)的生成与Faster R-CNN中anchor类似的方式
- 在特征图的每个像素点处,生成不同宽高比的default box(anchor box),论文中设置的宽高比为{1,2,3,1/2,1/3}。假设每个像素点有k个default box,需要对每个default box进行分类和回归,其中用于分类的参数为c*k(c表示类别数),用于回归的参数为4*k
- default box的尺寸计算是基于下面的公式的(YOLOV3是直接利用kmeans生成的,也不需要宽高比。faste-rcnn是直接设置的anchor Scales )
- 先验框匹配的原则
- 先验框匹配的目的、
- 为了训练。在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。
- SSD匹配原则
- 1、对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。(一个图片中ground truth是非常少的, 而先验框却很多,如果仅按这一个原则匹配,很多先验框会是负样本(匹配不上的)造成正负样本极其不平衡,所以有了下一个原则)
- 2、对于剩余的未匹配的先验框,若与某个ground truth的 IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。
- 先验框匹配的目的、
- 简介
- 从特征融合的角度来提升准确度解决小目标检测的问题(DSSD、FSSD)
- DSSD:DeconvolutionalSingleShotDetector
- 简介
- 基础信息: cvpr2017 二作就是SSD的一作Wei Liu
- 主要解决问题:SSD对小目标不够鲁棒(SSD虽然采用了多层feature map来生成bbox,浅层的feature map对小目标的检测可以起到一定的作用,但是浅层的feature map的表征能力不够强(因为层数浅,可能不能提取到语义特征))
- 主要贡献: 在常用的目标检测算法中加入上下文信息(特征融合)。即(基于CNN的目标检测算法基本都是利用一层的信息(feature map),比如YOLO,Faster RCNN等。还有利用多层的feature map 来进行预测的,比如ssd算法。那么各层之间的信息的结合并没有充分的利用。)
- 网络结构
- 基础网络是Residual-101与SSD (即用resnet 101 替代了原来的vggnet,因为更深的网络具有更强的表征能力)
-
- prediction Moudule(该模块的消融实验结果表明变体c结果最好)(注意:下图中的cls 与 loc 只是分别画出,但其仍然都是基于回归的,只是loss不同)
-
- Deconvolution module(中间的Eltw Product可以是求和也可以是乘积,实验显示为乘积时效果更好)(该模块中的Deconv是为了替代bilinear upsampling)
- 总结
- 提高浅层的表征能力,是可以提高类似检测器对小目标的检测能力
- 简介
- FSSD:Feature Fusion Single Shot Multibox Detector
- 简介
- 北航
- 主要贡献:提出一个特征融合模块(Feature Fusion Module)。其中:方式c是FPN的方式,方式d是SSD中采用的方式, e是本文采用的融合方式,就是把网络中某些feature调整为同一szie再 contact,得到一个像素层,以此层为base layer来生成pyramid feature map,作者称之为Feature Fusion Module。该方式与FPN相比,只需要融合一次,较为简单,在融合时方式e采用的时concat,标准的fpn采用的时sum
- 网络结构
- 注:这里concat之后之所以是512是因为作者是从三个里面选择了两个feature map进行融合 。在生成pyramid feature map 时,在fusion feature map接了个33卷积后作为第一层的。没有直接将fusion feature map作为第一层(实验之后选择的)
-
- 简介
- RefineDet:Single-Shot Refinement Neural Network for Object Detection
- 简介
- cvpr2018
- two stage(生成候选框+确定目标的位置与类别)与one stage(直接回归) 融合,(最后论文还是定位到one-stage)
- SSD、FPN(为了特征融合)、RPN(two stage的体现,为了提高object detection位置的准确性)的结合
- 模型主要包含两大模块, 分别是anchor精化模块和物体检测模块. 网络采用了类似FPN的思想, 不仅提升了精度, 同时还在速度方面取得了与one-stage方案相媲美的表现
- 主要特点是:先对anchor进行一次精细化(提取出属于前景的ancho,并调整其位置与尺寸),之后在基于精细化后的anchor进行物体检测
- 网络结构
- 该网络与faster-rcnn有类似之处,
- ARM(anchor refinement moudle)类似与RPN,其起到的作用是对feature map上生成的anchor的位置和尺寸的微调,以及前景和背景的判断,之后将背景过滤掉,不传入ODM(object detection moudle)(但是网上复现的源码并没有将背景滤掉,可能是因为要为anchor设置索引并且要存储前景信息的索引,还要映射回来麻烦?)
- ODM相当于SSD的操作
- TCB(Transfer Connection Block),用于链接ARM和ODM,并且可以构成类似FPN的结构,实现特征的融合
- 该网络与faster-rcnn有类似之处,
- 简介
- SSD:SingleShotMultiBoxDetector
-
-
部分内容来源网络,如有侵权,请联系删除
SSD系列(SSD、DSSD、FSSD 、RefineDet)
article/2025/8/22 22:41:05
相关文章

DL之DSSD:DSSD算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
DL之DSSD:DSSD算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略 相关文章DL之DSSD:DSSD算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略DL之DSSD:DSSD算法的架构详解
DSSD算法的简介(论文介绍) DSSD࿰…


SSD目标检测算法改进DSSD(反卷积)
论文:DSSD : Deconvolutional Single Shot Detector 论文地址:https://arxiv.org/abs/1701.06659 代码:https://github.com/chengyangfu/caffe/tree/dssd DSSD是2017年的CVPR,二作就是SSD的一作Wei Liu。另外值得一提的是…

SSD、DSSD算法详解
SSD(Single Shot MultiBox Detector)
特点:多尺度特征图用于检测;采用了先验框,,SDD backbone采用VGG-16
SSD和YOLO一样都是采用一个CNN网络进行检测,但是采用了多尺度的特征图,如下图所示:
采用多尺度特征图用于检测
采用步长stride=2的卷积或者pool来降低特征图…
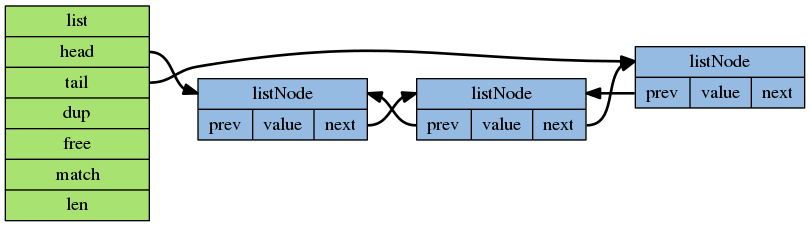

xSSD: DSSD,FSSD,ESSD,MDSSD,fireSSD
1 DSSD
title :DSSD : Deconvolutional Single Shot Detector conf & anthor: arXiv, Cheng-Yang Fu arXiv:https://arxiv.org/abs/1701.06659 intro:Deconvolutional 主要内容: DSSD使用ResNet-101代替VGG作为主干网络,在‘SSD layers‘后面添加了…

redis SDS介绍
Redis面试中经常被问到,Redis效率为什么这么快,很多同学往往回答: ① Redis基于内存操作② Redis是单线程的,采用了IO多路复用技术③ Redis未使用C语言字符串,使用了SDS字符串然而,很少有人能说清楚SDS字符…

DSSD: Deconvolutional Single Shot Detector 论文笔记
论文地址:DSSD : Deconvolutional Single Shot Detector 项目地址:Github
概述
这篇论文应该算是SSD: Single Shot MultiBox Detector的第一个改进分支,作者是Cheng-Yang Fu, 我们熟知的Wei Liu大神在这里面是第二作者…

DSSD(Deconvolutional Single Shot Detector)算法理解
论文地址:https://arxiv.org/abs/1701.06659 Github 源码(caffe版):https://github.com/chengyangfu/caffe/tree/dssd
1、文章概述 DSSD(Deconvolutional Single Shot Detector)是SSD算法改进分支中最为著名的一个,SS…

DSSD : Deconvolutional Single Shot Detector
参考 DSSD : Deconvolutional Single Shot Detector - 云社区 - 腾讯云 目录
一、简介
二、相关工作
三、反卷积的单阶段检测器DSSD
3.1、SSD
3.2、用VGG代替Residual-101
预测模型
反卷积SSD
反卷积模块
训练
四、实验
基本网络
PASCAL VOC 2007
在VOC2007上的消…


目标检测系列:SSD系列SSD、FSSD、DSSD、DSOD
SSDDSSDFSSDDSOD SSD
动机
目前目标检测的一些算法包括基于深度学习的,都是先假定一些候选框,接着对候选框内容进行特征提取再分类,然后再对边框的位置进行修正这一系列的计算,最典型的例如Faster RCNN,虽然准确&…

计算机保密dss是啥,什么是DSS?
什么是DSS 上线时间:2020年9月4日 以下引用猪弟写的设计文档: DFS的存款系统: DSS (DFS Saving System) 原名DSR,你也可以把它称作,DFS的银行或DFS的余额宝。 它是专门为DFS量身定做的DFS币本位无风险保障性收入系统。 特征&#…
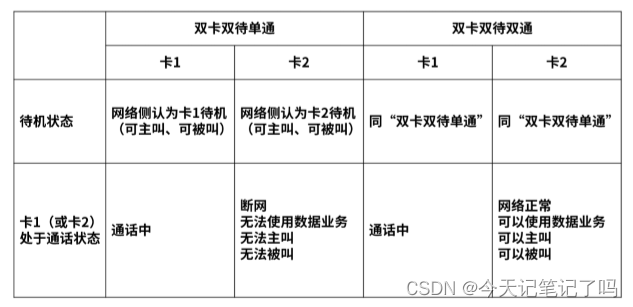
SS, DSDS, DR-DSDS,DSDA 区别与理解
1.首先简单解释一下SS, DSDS, DSDA都是什么意思
SS(single standby):单卡单待
DSDS(Dual SIM Dual Standby) :双卡双待
DSDA(Dual SIM dual active):双卡双通 2.双卡双待/双卡双通主要区别
双待 : 两个卡都处于待机状态&#…


目标检测(六):DSSD
SSD 的提出为目标检测领域带来了一大改进,无论是准确性还是速度都要优于先前的检测模型,美中不足的是 SSD 对图像中的小目标不太友好,检测效果一般,可能是因为小目标在高层没有足够的信息。为解决该问题,出现了以下几种…
目标检测算法DSSD的原理详解
论文地址:https://arxiv.org/abs/1701.06659 Github 源码(caffe版):https://github.com/chengyangfu/caffe/tree/dssd 1、文章概述 DSSD(Deconvolutional Single Shot Detector)是SSD算法改进分支中最为著名的一个,SSD…

【每日一网】Day30:DSSD(Deconvolutional Single Shot Detector)简单理解
DSSD:Deconvolutional Single Shot Detector
算法背景
本文的主要贡献在于将上下文索引和残差网络加到了SSD算法中,然后在反卷积层上增加SSD和residual-101,以在目标检测中提高对小目标的准确性。DSSD将SSD的VGG网络用Resnet-101进行了替换…
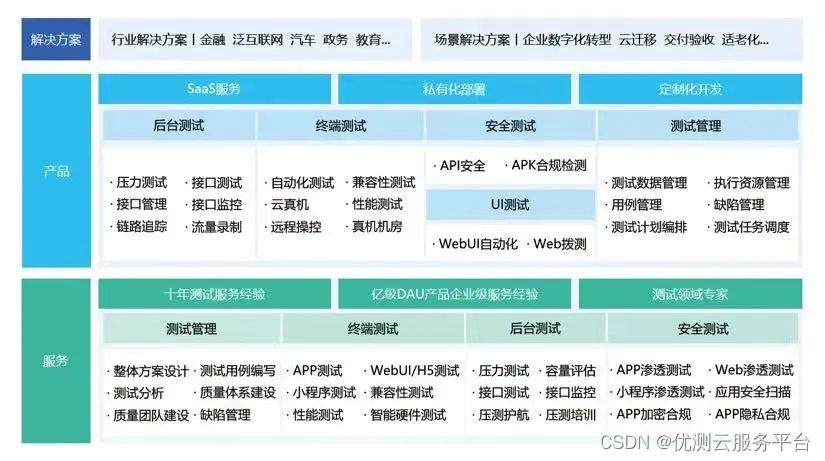
【压测指南|压力测试核心性能指标及行业标准】
文章目录 压力测试核心性能指标及行业标准指标1:响应时间指标2:吞吐量(TPS)指标3:失败率总结: 压力测试核心性能指标及行业标准
在做压力测试时,新手测试人员常常在看报告时倍感压力:这么多性能…
推荐文章
- 铲特-姬劈蹄的N种用法(持续更新中。。。)
- ChatGPT快速入门
- 《ChatGPT Prompt Engineering for Developers》课程中文版系列
- ChatGPT帮你写代码?人工智能ChatGPT之于Web3的几点思考
- ChatGPT核心技术奠基者,在中国开放平台
- [chatGPT问题解决]An error occurred. If this issue persists please contact us through our help center at
- uniapp 离线打包 添加文件读写权限
- python 文件读写操作总结
- Linux监控文件读写
- C#文件读写操作 [详细]
- Qml读写文件
- 文件读写基本流程