SSD 的提出为目标检测领域带来了一大改进,无论是准确性还是速度都要优于先前的检测模型,美中不足的是 SSD 对图像中的小目标不太友好,检测效果一般,可能是因为小目标在高层没有足够的信息。为解决该问题,出现了以下几种 SSD 的改进版本:
- DSSD: Deconvolutional Single Shot Detector
- RSSD: Enhancement of SSD by concatenating
feature maps for object detection - DSOD: Learning Deeply Supervised Object Detectors from Scratch
- FSSD: Feature Fusion Single Shot Multibox Detector
若上述链接无法打开,可以去该网盘链接下载:上述论文(提取码:pyto )
如果只需要简单了解,可参考该博客:深度学习之目标检测(五)—— DSSD & DSOD & FSSD & RSSD
最早出现的改进版本是 DSSD,该模型在原 SSD 的基础上更改了基础网络,并添加了预测模块和反卷积模块以增加特征图的分辨率,从而改善对图像中较小目标的检测效果。本篇博客将记录 DSSD 模型的构建思想和训练以及实验。
目录
- 1. DSSD 算法构建
- 1.1 related work
- 2.2 DSSD 的改进方向
- 2. DSSD 模型构建
- 2.1 整体结构
- 2.2 预测模块(Prediction Module)
- 3. 反卷积模块(Deconvolution Module)
- 3. 模型的训练
- 3.1 优化 default box 的生成
- 3.2 对基础网络的改进
- 3.3 训练设置
- 4. 小结
- 4.1 DSSD 的优点
- 4.2 DSSD 的缺点
- 5. 代码复现
- 6. 参考文章
1. DSSD 算法构建
1.1 related work
传统的 Sliding Window 是对图像中存在的目标,先选取出一部分可能的边界框,然后再进行分类,典型的双阶段方法,例如 SelectiveSearch、R-CNN 系列等。为紧跟最前沿的算法实现更高的准确性和速度,利用 Sliding Window 算法时需要考虑的边界框数量越来越多,从而计算成本不断增大,使得 Sliding Window 在一段时间内不再适用。然而随着深度学习和机器学习框架的不断发展,使用较少数量边界框的 Sliding Window 技术得以实现,与传统方式不同的是,通过完成 分类:预测边界框类别得分 + 回归:预测边界框的offset 两项任务可以直接将分类器应用在一组可能的边界框上,有效地结合了 region proposal 和 classify 两个阶段,实现了单阶段方法,如 SSD、YOLO 等。
此外,像 SPPNet、Faster R-CNN 这种仅使用一层特征进行预测,很难兼顾所有可能的目标尺度和形状,因此一个很自然的想法就是 使用卷积网络的多个特征层进行预测应该有助于提高精度。实际中这一想法已经存在很多实践证明,大致可以分为以下三类方法:
- 将卷积网络中不同层的特征融合在一起,并利用组合后的特征图进行预测。
- 如 ION 网络利用 L2-Normalization 组合了 VGG 中的多个特征层,将特征图融合并用于预测;
- HyperNet 也是类似的。
组合特征图的优点是显然的,融合的特征来自于输入图像不同抽象层次,更具有描述性,适于进行分类和边框回归;但其缺点也不可忽视,随着模型的内存占用显著增加,模型的速度也随之下降。
- 利用卷积网络的不同特征层预测不同尺度的目标。由于不同层具有不同的感受野,具有较大感受野的层(网络深层)通常用于预测大目标,有着较小感受野的层则用于预测小目标 参考 [3]。
- 如 SSD 将不同尺度的默认框分布在模型的六个特征层上,使得不同的层只需要关注该层特定尺度的目标;
- MS-CNN 在学习候选区域和合并特征之前,将反卷积应用在了网络的多个层上以提高特征图的分辨率。
因此为了更好的预测小目标,网络需要更多的来自具有小感受野和密集特征图的浅层的语义信息,但因为浅层往往只含有较少的语义信息无法直接使用,所以可以采用反卷积+跳跃连接的方式。
- 尝试包含更多用于预测的上下文信息。如Multi-Region CNN 不仅从候选区域中提取特征,还会从其他预定义的区域中获取特征。
因此作者考虑采用“编码器-解码器”的沙漏型结构在进行预测之前传递上下文信息,利用反卷积层不仅可以解决特征图分辨率下降的问题,同时还可引入更多用于预测的上下文信息。
2.2 DSSD 的改进方向
回到我们的问题上,SSD 对小目标的检测效果不好,主要原因就是用于预测小目标的是网络的浅层语义信息,缺乏深层表征能力比较强的语义信息,如何让网络学习关于小目标的深层语义信息就是 DSSD 的核心问题。
卷积神经网络在结构上存在固有的问题:高层网络感受野比较大,语义信息表征能力强,但是分辨率低,几何细节信息表征能力弱。低层网络感受野比较小,几何细节信息表征能力强,虽然分辨率高,但语义信息表征能力弱。SSD采用多尺度的特征图来预测物体,使用具有较大感受野的高层特征信息预测大物体,具有较小感受野的低层特征信息预测小物体。这样就带来一个问题:使用低层网络的特征信息预测小物体时,由于缺乏高层语义特征,导致SSD对于小物体的检测效果较差。而解决这个问题的思路就是对高层语义信息和低层细节信息进行融合。作者采用Top Down的网络结构进行高低层特征的融合并且改进了传统上采样的结构。参考 [1]。
原文中提到,可以从三个方面来提高模型的检测精度:
- 使用更好的特征网络——DSSD 将原 SSD 的基础网络 VGG16 替换成了更深的 Residual-101 网络,同时利用多个卷积层的特征图进行预测。
- 向网络中添加更多的语义信息——DSSD 在原 SSD 后增加了反卷积层以提高特征图的分辨率,同时将浅层语义信息和深层语义信息进行融合,一定程度上提高检测准确性,尤其是对小目标;
- 提升预测过程中边界框的空间分辨率——DSSD 在原 SSD 的特征层添加了预测模块作为输出层,引入残差块结构优化边界框回归和分类任务输入的特征图,增强特征重用。
DSSD作者提出一种通用的Top Down的融合方法,使用vgg和resnet网络,以及不同大小的训练图片尺寸来验证算法的通用型,将高层的语义信息融入到低层网络的特征信息中,丰富预测回归位置框和分类任务输入的多尺度特征图,以此来提高检测精度。在提取出多尺度特征图之后,作者提出由残差单元组成的预测模块,进一步提取深度的特征最后输入给框回归任务和分类任务。参考 [1]。
综上所述, DSSD 的算法思想主要是基于以下两点:
- 提出基于 top down 的网络结构,增加反卷积层(反卷积模块DM)实现深层特征和浅层特征的融合;
- 在预测阶段添加基于残差块构建的预测模块(PM),优化用于 分类+边界框任务 的特征图。
为什么没有指出替换基础网络也是其思想之一?
不完全否定 Residual101 的作用,毕竟它比 VGG 要深的多,在提高准确性上必然是有帮助的。但,原文的消融实验表明,SSD321 的 mAP=76.4%,而原始的 SSD300 可达到 77.5%,说明简单的将基础网络 VGG 替换为 Residual101并不能改善结果,真正对检测效果起到提升作用的是上面两个改进,或者说 SSD-Res101 只有在添加上面两个改进后才会起到作用。
2. DSSD 模型构建
2.1 整体结构
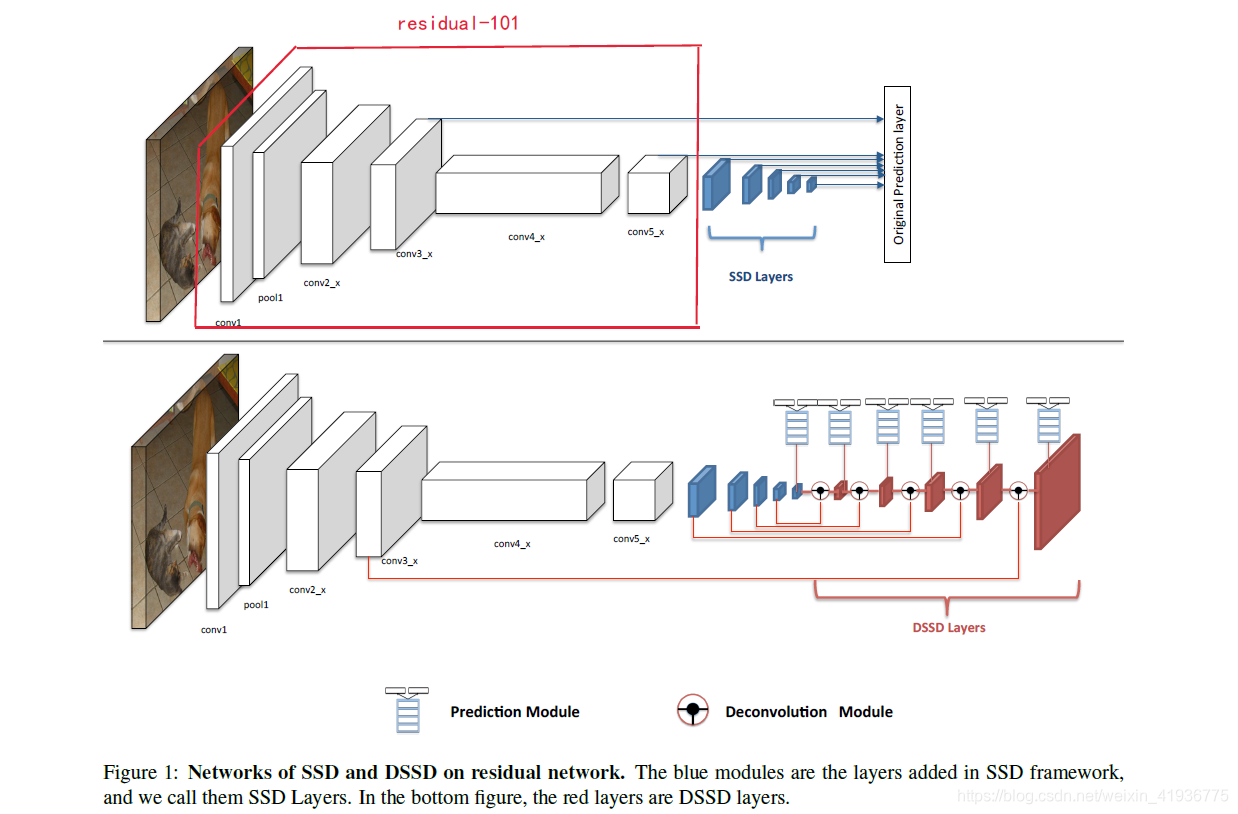
- 图中的上半结构是以 Residual-101 代替 VGG16 后的 SSD 模型,给他简记为 SSD321。其中的
conv3_x,conv5_x为 Res101 中原有的卷积层,蓝色的五层为 原SSD 中新增的卷积层。原始的 SSD300 是将六个卷积层[conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11_2]直接输入进预测阶段进行分类和回归任务。 - 图中的下半结构是以 Res101 作为基础网络并添加预测模块和反卷积模块后的 DSSD,它将六个卷积层
[conv3_x, conv6, conv7, conv8, conv9, conv10]输入到反卷积模块中,输出特征融合后的特征图金字塔(形成了一个由特征图组成的对称沙漏结构),融合后的特征图再经预测模块输入给分类任务和回归任务进行预测。
2.2 预测模块(Prediction Module)
刚才提到,原始的 SSD300 是将卷积层的特征图直接输入进预测阶段进行分类和回归任务(除了 conv4_3 层由于梯度过大使用了 L2 Normalization),因此为了获取更好的预测效果,可以从预测阶段下手。
MS-CNN[2] points out that improving the sub-network of each task can improve accuracy. 大概意思是通过改进每项任务的子网络可以提升准确性。
基于该理念,作者考虑为每个用于预测的特征层添加一个残差模块,结构如下图所示:

- ( a ) (a) (a) 表示原 SSD 中的方式,直接将多尺度特征图用于分类和回归任务,可以表示为 y = x y=x y=x;
- ( b ) (b) (b) 表示带有 identity-skip connection 的残差块,即 ResNet 中残差单元的结构,可以表示为 y = F ( x , W i ) + x y=F(x, {W_i})+x y=F(x,Wi)+x;
- ( c ) (c) (c) 表示带有conv-skip connection 的残差块,将原残差结构中的 identity-skip connection 改进为卷积处理,再与主干的特征图做通道间加法,可以表示为 y = F ( x , W i ) + W s x y=F(x, {W_i})+W_sx y=F(x,Wi)+Wsx;
- ( d ) (d) (d) 表示含有两个堆叠的残差块 ( c ) (c) (c) 的预测模型。
针对上述四种不同的预测模型,作者在训练阶段进行了消融实验,其中模型 ( c ) (c) (c) 的实验效果是最好的。因此在预测阶段采用了模型 ( c ) (c) (c) 对特征图进行处理。

3. 反卷积模块(Deconvolution Module)
DSSD 在原始 SSD 后添加了一系列的反卷积层,并利用这些层进行预测,实现了连续增加特征图层的分辨率;同时利用 skip connection 将浅层信息和深层信息融合以增强特征,构建了一个非对称的沙漏网络结构。但 [2] 中表示沙漏模型在编码器和解码器阶段应当包含对称的层,为什么 DSSD 构建的非对称网络也可以?
原因在于:
- 首先,目标检测作为计算机视觉的一项基本任务,其速度非常重要,而构建对称网络意味着推理时间的翻倍,对 DSSD 作为一个快速检测框架而言,并不需要构建对称模型;
- 其次,随着检测精度的不断增高,网络的层数也在逐渐增加,为加速训练,迁移学习开始被广泛使用,相比于随机初始化的模型,使用迁移学习能够使模型收敛更快且准确性更高。然鹅 DSSD 的解码器阶段并不存在预训练模型,因此无法利用迁移学习,必须采用随机初始化,而反卷积层的计算成本比较高,因此 DSSD 将解码器阶段设置为只与 SSD 新增层对称是可以理解的。
下图红色区域即反卷积层,与左边的蓝色区域及 conv3_x 构成了对称层,但整体来看,编码器和解码器阶段是非对称的。
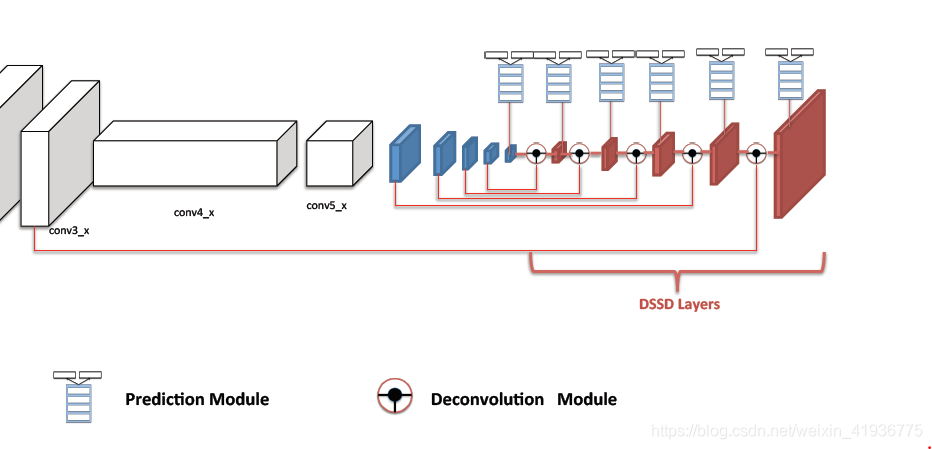
其中反卷积模块的构建思想源于 [6]。
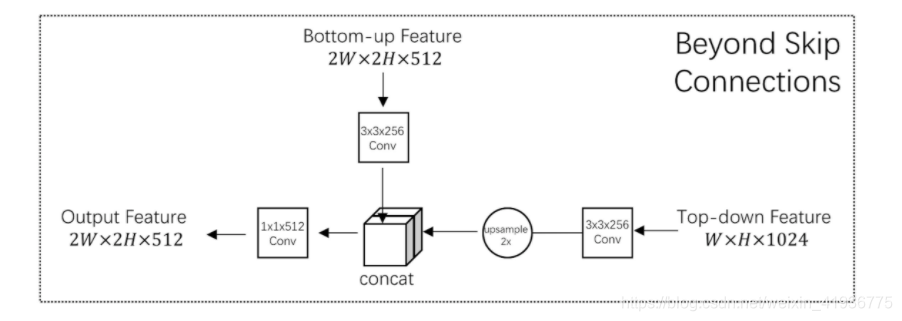
通过消融实验得到使用 Eltw Product 可以获取比 Eltw Sum 更高的准确性,因此 DSSD 选择使用 Eltw Product 将浅层和深层的特征图在对应的通道上做乘法运算,实现了高层特征和低层特征的融合,本质思想即 Top Down融合。结构如下:
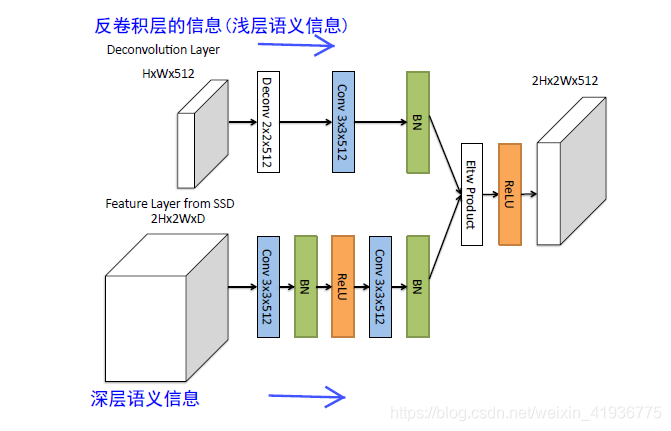
这里需要注意下该模块的两点细节:
- 在每个卷积层后都有一个 BN 层;
- 这里的反卷积是指可以进行学习的卷积的逆过程,而非双线性上采样;
除 DSSD 外,[4] 和 [5] 也利用了 Top Down 融合的思想。
- FPN使用的是 Eltw Sum (也叫broadcast add),将浅层和深层的特征图在对应的通道上做加法运算;

- TDM 使用的是 concat 操作,让浅层和深层的特征图叠加在一起。
3. 模型的训练
DSSD 的训练遵循 SSD 的训练策略,包括 匹配、难负例挖掘、数据增强 及 损失函数,同时做了一部分改进,以更好地适应 DSSD 模型。
3.1 优化 default box 的生成
根据 SSD 模型的训练和实验结果,宽高比为 {2, 3} 的 default box 作用比较大。为了得到 PASCAL VOC 2007 和 2012 trainval 数据集中各个目标对应的 gt box 的宽高比,以框内区域面积的平方根作为特征,作者用 K-means 聚类 对这些 gt box 做了一个聚类分析。最后确定七类的时候收敛的错误率最低,如下图所示:
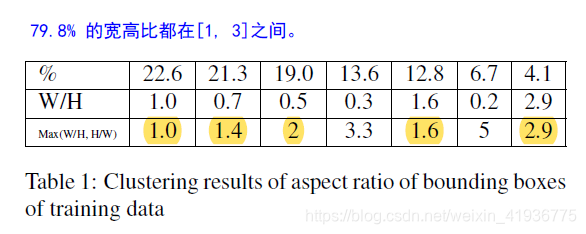
由于 SSD 训练时会将输入调整为方形尺寸如 300 或者 512,且大多数训练图像更宽,所以相应的真实框的宽度会变小一点。基于此表,我们可以看到大多数框比都在 [1, 3] 的范围内,因此,我们决定再增加一个宽高比 1.6,并在每个预测层使用的宽高比为 [1, 1.6, 2, 3] 的default box。
3.2 对基础网络的改进
-
使用 Residual-101 代替 SSD 中的 VGG,并在 ILSVRC CLS-LOC 上进行预训练;

-
遵循 [7] 中设置将
conv5_x的 effective stride 由32更改为16以增加特征图分辨率,这里的32是怎么计算的?ResNet 的输入是224*224,conv5_x的输出是7*7,因此原始步长为224/7=32; -
将
conv5_x中第一个stride=2的卷积层修改为stride=1; -
将
conv5_x中所有kernelsize>1的卷积层由dilation=1修改为dilation=2,并利用 Atrous 算法获取更为密集的特征图; -
DSSD 中选择了如下特征层作为预测层
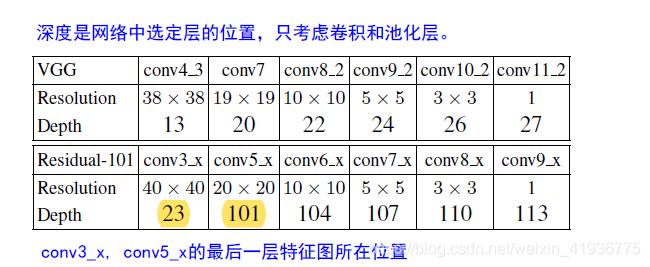
为什么要选择conv3_x,原因在于预测较小目标时密集的特征层能带来更好的预测效果。如果我们只考虑kernelsize>1的卷积层,那么 DSSD 中用于预测的第一个层的深度将下降至9,与 VGG 中的conv4_3相比,该层神经元的感受野可能更小,且特征较弱,就有可能导致预测性能比较差。
3.3 训练设置
| SSD-R101 | 参数设置 |
|---|---|
| train | VOC 2007+2012 trainval |
| test | VOC 2007 test |
| batch_size | 32 32 32 for SSD321 |
| 20 20 20 for SSD513 | |
| lr | 1 0 − 3 10^{-3} 10−3 for 40k iterations |
| 1 0 − 4 10^{-4} 10−4 for 20k iterations | |
| 1 0 − 5 10^{-5} 10−5 for 10k iterations | |
| stage one | 以训练好的 SSD-R101 作为预训练模型,冻结所有权重仅训练反卷积层(无预测模型),分别以 1 0 − 3 10^{-3} 10−3 和 1 0 − 4 10^{-4} 10−4 训练 20k 与 10k iterations |
| stage two | 微调阶段一训练后的模型,解冻 SSD-R101 的权重,添加预测模型,分别以 1 0 − 3 10^{-3} 10−3 和 1 0 − 4 10^{-4} 10−4 各训练 20k iterations |
这里需要注意的一个地方是:实验结果表明添加了微调阶段的训练方法并没有提升模型的性能,反而不冻结网络参数,直接训练网络效果更好。

4. 小结
4.1 DSSD 的优点
- 对包含小目标获密集目标的场景性能比较好;
- 对具有特定上下文的某些类,如足球和足球运动员、西装和领带等性能比较好。
4.2 DSSD 的缺点
速度上没有 SSD 快。原因如下:
- Residual-101 比 VGG 更深;
- 在 SSD 后面新增的卷积层、预测模块和反卷积模块会引入额外的计算成本,加速的一种方式是用较为简单的双线性上采用替代反卷积;
- 相比原 SSD 使用了更多的 default boxes,因此在预测和进行 NMS 时,所用时间均多于原 SSD。
5. 代码复现
Github 上找到了一个利用 Pytorch 实现 DSSD 的源码,ZQPei/DSSD,有兴趣的小伙伴可以区围观一下。
实验记录稍后来补~
6. 参考文章
[1]. DSSD:Deconvolutional Single Shot Detector 解析与实践
[2]. Stacked Hourglass Networks for Human Pose Estimation
[3]. 关于感受野
[4]. FPN:Feature Pyramid Networks for Object Detection
[5]. TDM:Beyond Skip Connections: Top-Down Modulation for Object Detection
[6]. Learning to refine object segments
[7]. R-FCN: Object Detection via Region-based Fully Convolutional Networks