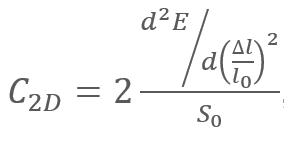在将HRNet从PyTorch框架向MindSpore迁移的过程中,由于初始学习率的选择不好,导致了最终精度没有达到预期要求。
文末有总结。
具体实验过程如下:
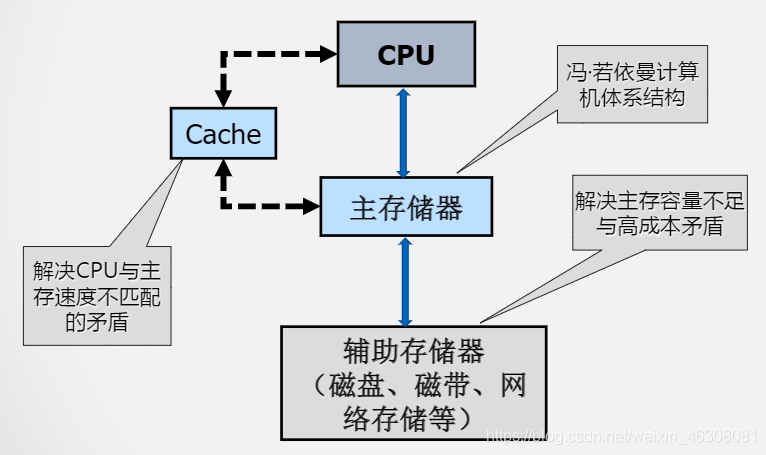
实验过程
-
优化器:SGD
初始学习率:0.01
学习率调整策略:poly
miou精度变化:

整体上呈上升趋势,但是没有达到预期的0.81。
经过检查,在400–484周期,miou一直是呈上升趋势。因此我有了第一个猜想:收敛速度不够。
因此,我尝试了其他的优化器和初始学习率。 -
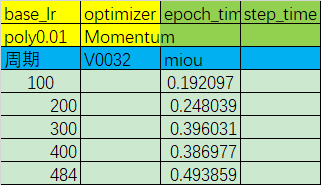
优化器:Momentum
初始学习率:0.01
学习率调整策略:poly
miou精度变化:
-
优化器:SGD
初始学习率:0.015
学习率调整策略:poly
miou精度变化:
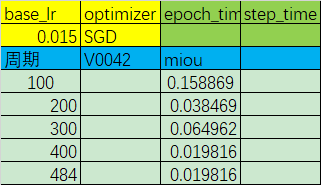
从上面的两个实验(以及其他更多类似实验)中可以得出一下结论:- 更换收敛更快的优化器并没有对实际的收敛速度有明显的帮助;
- 增大学习率后,精度先是正常上升,但在200–300周期出现了断崖式下跌,此后一蹶不振。
更改不同的初始学习率(均大于0.01),并更换其他收敛更快的优化器,结果都和上面如出一辙。都很烂!!!情况变得有些焦灼。
然后我采用了固定学习率,进行了如下实验。 -
优化器:SGD
初始学习率:0.01
学习率调整策略:固定学习率
miou精度变化:

不出所料,中途拉跨,和之前的情况很相似,因此我有了第二个猜想:造成精度中途暴跌的原因是学习率过大。 即使是用poly策略动态调整,中间过程中的学习率对于训练还是太大了。
那么就减小学习率嘛。 -
优化器:SGD
初始学习率:0.00001
学习率调整策略:固定学习率
miou精度变化:

固定学习率0.00001,训练1000周期,精度变化稳步上升,证明调小学习率的猜想是可行的。 -
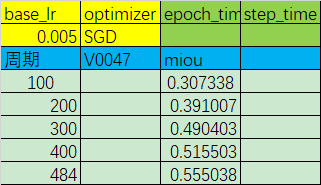
优化器:SGD
初始学习率:0.005
学习率调整策略:poly
miou精度变化:
-
优化器:Momentum
初始学习率:0.005
学习率调整策略:poly
miou精度变化:
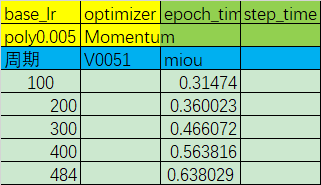

虽然,和目标的精度还有一段距离,但至少前进的方向有了!
总结
网络收敛速度慢的原因可能有两个:学习率略大和学习率太小。
-
学习率略大
学习率略大会导致网络在收敛的过程中是以一种徘徊向前的形式收敛。学习率大倒不至于致使网络不收敛,但会导致每次收敛都要先在更优值附近震荡,直到等到合适的学习率才会收敛一点。这点可以通过之前加大学习率的实验证明,当学习率足够大,便会放大这个问题,使得精度在中途暴跌! -
学习率太小
这个原因就很好理解了,学习率太小导致网络在最后一个周期结束还没达到最优值。可以采用收敛更快的优化器或是适当增大学习率调整。
精度中途暴跌的原因:学习率太大。
精度涨停:暂时没有经验。
这是我第一次迁移网络,第一次调整网络,因此缺乏足够的理论支撑,大多是个人的感性认知。欢迎大家挑错、指正、补充!