第三章 关系数据库标准语言 SQL
文章目录
- 第三章 关系数据库标准语言 SQL
- 3.1 SQL 概述
- 3.1.1 SQL 的特点
- 3.2 学生-课程数据库
- 3.3 数据定义
- 3.3.2 基本表的创建、删除与修改
- 1. 基本表的创建
- 2. 数据类型
- 3. 插入数据
- 4. 修改数据
- (1) 修改某一个元组的值
- (2) 修改多个元组的值
- (3) 带子查询的修改语句(后面就讲子查询)
- 5. 删除数据
- (1)删除某一个元组的值
- (2) 删除多个元组的值
- (3) 带子查询的删除语句(后面就讲子查询)
- 3.4 数据查询
- 3.4.1 单表查询
- 1. 选中表中的若干列
- (1)查询指定列(属性)
- (2)查询全部列—— *
- (3)重命名列名(属性)
- 2. 选择表中的若干元组
- (1)去重关键字—— DISTINCT
- (2)比较
- (3)确定范围
- (4) 确定集合
- (5) 字符匹配
- (6)涉及空值的查询
- (7) 多重条件查询
- 3. ORDERB子句
- 4. 聚变函数
- 5. GROUP BY 语句
- 3.4.2 连接查询——多表查询
- 1. 等值与非等值连接
- 2. 自身连接——给自己取别名,代表各自信息
- 3. 外连接
- 4. 多表连接
- 3.4.3 嵌套查询
- 1. 带有IN谓词的子查询
- 2. 带有比较运算守甘子查询
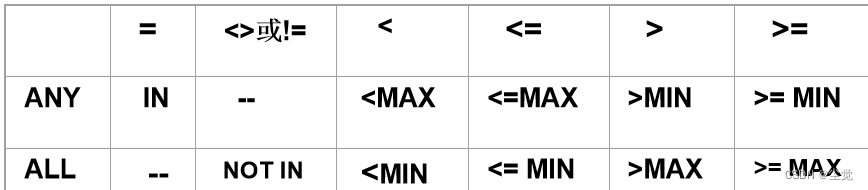
- 3. 带有ANY(SOME)或ALL谓词的子查询
- 4. 带有EXISTS谓词的子查询
- 3.5 视图
- 3.5.1 视图的作用
- 3.5.2 视图的用法
概述:了解数据库表单的查找、删除、添加、修改
3.1 SQL 概述
3.1.1 SQL 的特点
1. 综合统一
1. 高度非过程化
1. 面向集合的操作方式
1. 以同一种语法结构提供多种使用方式
1. 语言简洁. 易学易用
了解即可
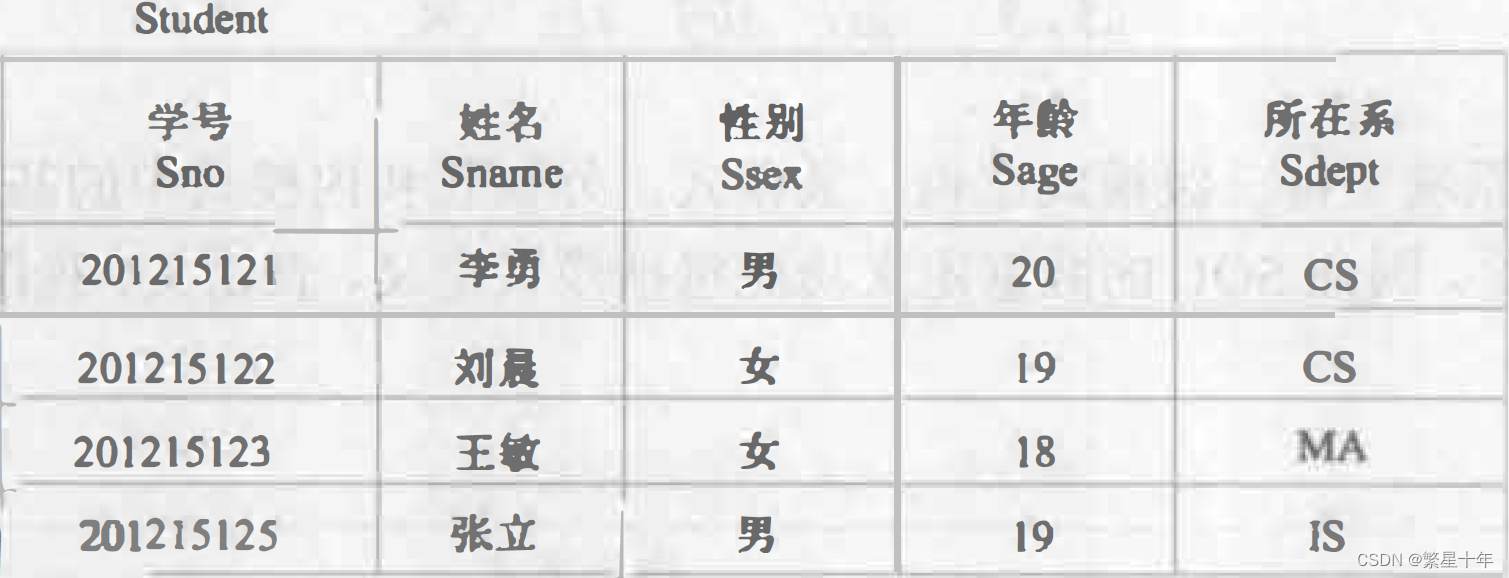
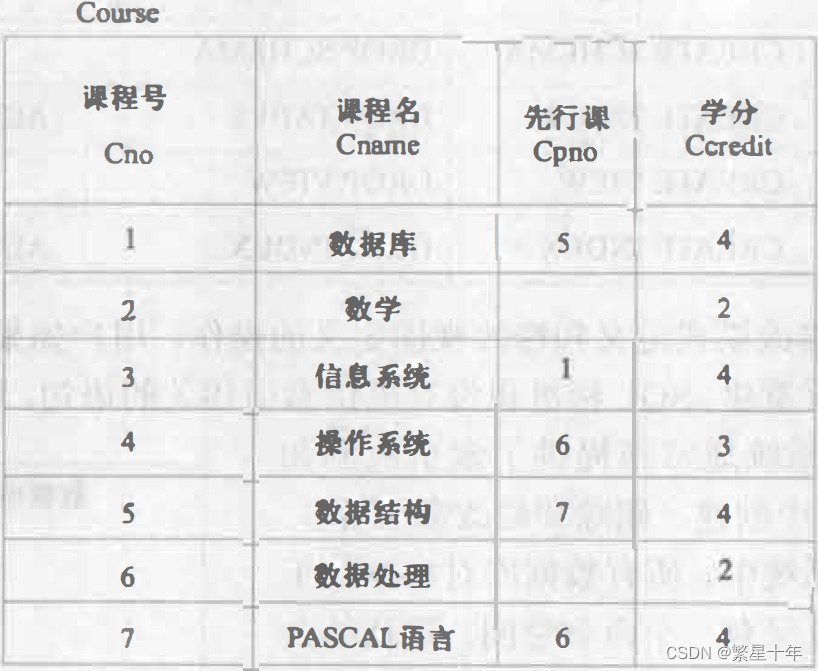
3.2 学生-课程数据库
这里给出navicat的三个表:Student、Course、Sc
3.3 数据定义
3.3.2 基本表的创建、删除与修改
1. 基本表的创建
基本格式:CREATE TABLE <表名> (<列名><数据类型> [列级完整性约束条件]
[,<列名><数据类型> [列级完整性约束条件]]
[,<表级完整性约束条件>])
简而言之:CREATE TABLE + 表名 + 列名(也就是属性) + 列级完整性约束条件
CREATE TABLE student (/*student表*/Sno CHAR ( 9 ) PRIMARY KEY,/*PRIMARY KEY 主键*/Sname CHAR ( 20 ) UNIQUE,/*UNIQUE 唯一*/Ssex CHAR ( 2 ),Sage SMALLINT,Sdept CHAR ( 20 )
);
CREATE TABLE Course (/*Course表*/Cno CHAR ( 4 ) PRIMARY KEY,Cname CHAR ( 40 ) NOT NULL,Cpno CHAR ( 4 ) Ccredit SMALLINT,FOREIGN KEY ( Cpno ) REFERENCES Course ( Cno )
);
CREATE TABLE SC ( /*Sc表*/Sno CHAR ( 9 ),Cno CHAR ( 4 ),Grade SMALLINT,PRIMARY KEY ( Sno, Cno ),FOREIGN KEY ( Sno ) REFERENCES student ( Sno ),FOREIGN KEY ( Cno ) REFERENCES Course ( Cno )
);
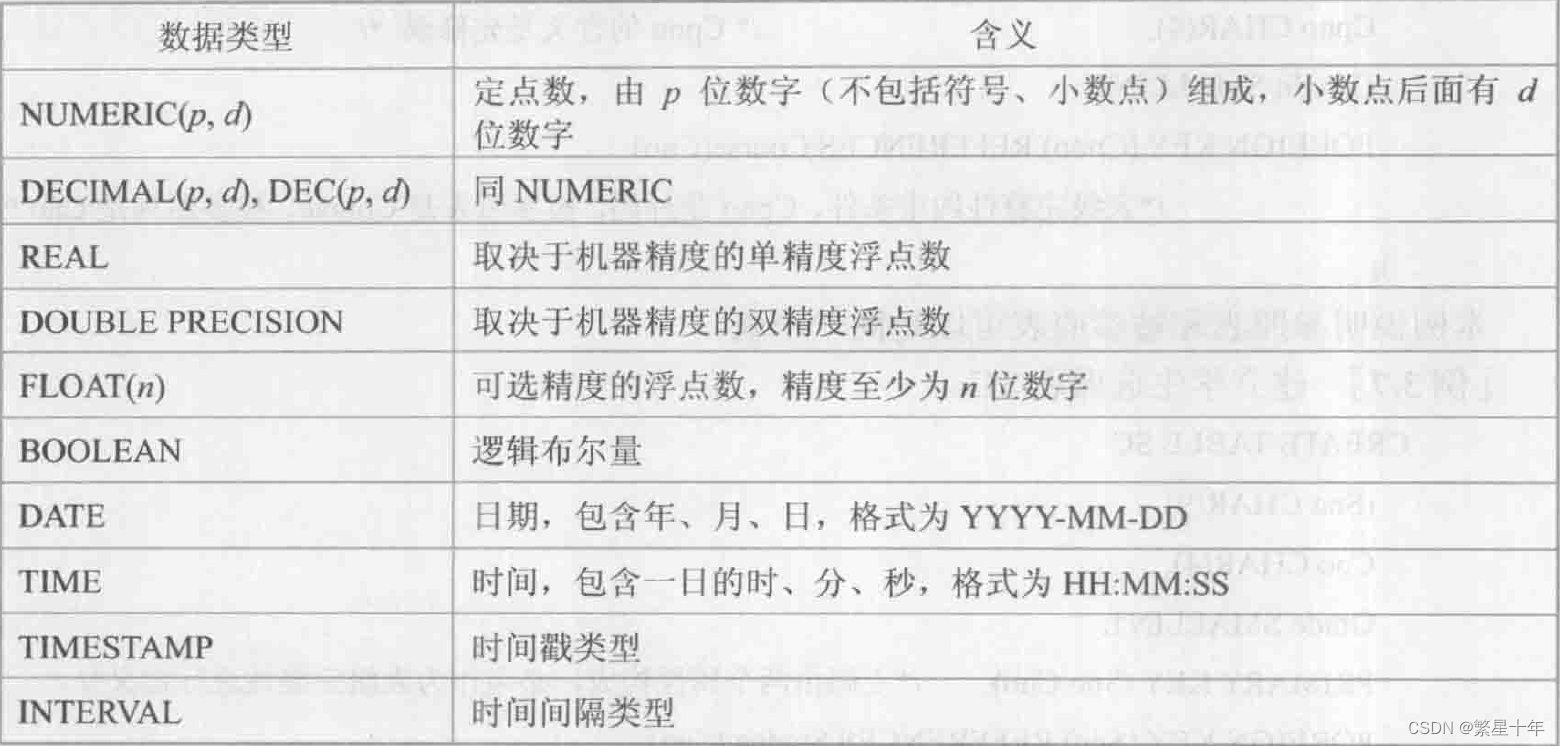
2. 数据类型

3. 插入数据
基本格式:INSERT
lNTO<表名> [(<属性列 I>[,<属性列 2>] ···)]
VALUES(<常量l>[,<常量>]…);
简而言之:INSERT + lNTO + 表名 + VALUES()
这里就把上述三个表的数据插入
/*插入数据,student表的数据,可以全部选中直接执行*/
INSERT INTO `student` VALUES('201215121','李勇','男','20','CS');
INSERT INTO `student` VALUES('201215123','王敏','女','18','MA');
INSERT INTO `student` VALUES('201215122','刘晨','女','19','CS');
INSERT INTO `student` VALUES('202115125','张立','男','19','IS');/*由于有外键的约束后面两个表不能一下全部选中执行,需要按顺序一条一条执行,后面会给出原因*/
INSERT INTO `course` VALUES ('1','数据库', '5', '4');/*执行的第5条指令*/
INSERT INTO `course` VALUES ('2', '数学', NULL, '2');/*执行的第1条指令*/
INSERT INTO `course` VALUES ('3', '信息系统','1', '4');/*执行的第6条指令*/
INSERT INTO `course` VALUES ('4', '操作系统', '6', '3');/*执行的第1条指令*/
INSERT INTO `course` VALUES ('5', '数据结构', '7', '4');/*执行的第4条指令*/
INSERT INTO `course` VALUES ('6', '数据处理', NULL, '2');/*执行的第2条指令*/
INSERT INTO `course` VALUES ('7', 'PASCAL语言', '6', '4');/*执行的第3条指令*//*这个表要求前两个表数据全部插入完成,才能插入*/
INSERT INTO `sc`(Sno,Cno, Grade) VALUES ('201215121', '1', '92');
INSERT INTO `sc` VALUES ('201215121', '2', '85');
INSERT INTO `sc` VALUES ('201215121', '3', '88');
INSERT INTO `sc` VALUES ('201215122', '2', '90');
INSERT INTO `sc` VALUES ('201215122', '3', '80');
这里先给出外键的定义,帮助大家理解为什么,插入是这个顺序。后续会精讲
外键:如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表。外键又称作外关键字。
简而言之:只要只要被作为外键的数据,一定要先存在再能插入
4. 修改数据
基本格式:UPDATE<表名>
SET<列名>=<表达式>[,<列名>=<表达式>]…
[WHERE<条件>];
(1) 修改某一个元组的值
UPDATE student
SET Sage=22
WHERE Sno='201215121';
(2) 修改多个元组的值
UPDATE student
SET Sage=Sage+1;
(3) 带子查询的修改语句(后面就讲子查询)
UPDATE sc
SET Grade=0
WHERE Sno IN(SELECT SnoFROM studentWHERE Sdept='CS';);
5. 删除数据
基本格式:DELETE
FROM<表名>
[WHERE<条件>]
(1)删除某一个元组的值
(2) 删除多个元组的值
(3) 带子查询的删除语句(后面就讲子查询)
3.4 数据查询
基本格式: SELECT [ALL I DISTINCT]<目标列表达式>[,<目标列表达式>J…
FROM<表名或视图名>[,<表名或视图名>···] I (<SELECT语句>)[AS]<别名>
[WHERE<条件表达式>]
[GROUP BY<列名I>[HAVING<条件表达式>]]
[ORDER BY<列名2>[ASC I DESC]]
简而言之:SELECT + FROM + WHERE + GROUP BY (聚合函数)+ ORDER BY (排序方式)
3.4.1 单表查询
1. 选中表中的若干列
(1)查询指定列(属性)
SELECT Sno,Sname/*查询指定列*/
FROM student;/*查询student表*/
(2)查询全部列—— *
SELECT * /*查询全部列*/
FROM student;/*查询student表*/
(3)重命名列名(属性)
SELECT Sname NAME, 'year of birth' BIRTH,2014-Sage BIRTHDAY,LOWER(Sdept)
FROM student;
简而言之: 选出目标列(属性)
2. 选择表中的若干元组

(1)去重关键字—— DISTINCT
DISTINCT:该查询结果里包含了许多重复的行。如想去掉结果表中的重复行,必须指定 DISTINCT:
SELECT DISTINCT Sno
FROM sc;
(2)比较
/*查询计算机科学系全体学生的名单*/
SELECT Sname, Sdept
FROM student
WHERE Sdept = 'CS';
(3)确定范围
/*查询年龄在20~23岁(包括20岁和23岁) 之间的学生的姓名、系别和年龄*/
SELECT Sname, Sdept, Sage
FROM student
WHERE Sage BETWEEN 20 and 23;
/*这里也可以用比较
WHERE Sage >= 20 and Sage <=23;
*/
(4) 确定集合
/*查询计算机科学系(CS)、数学系(MA)和信息系(IS)学生的姓名和性别*/
SELECT Sname, Ssex, Sdept
FROM student
WHERE Sdept IN('CS', 'MA', 'IS');
(5) 字符匹配
谓词 LIKE:
基本语法:[NOT] LIKE’<匹配串>' [ESCAPE '<换码字符>' ]
-
% (百分号)代表任意长度(长度可以为0) 的字符串。
例如 a%b 表示以 a 开头, 以b 结尾的任意长度 的字符串。如 acb 、addgb 、 ab 等都满足该匹配串。
-
-(下横线)代表任意单个字符。
例如 a_b 表示以 a 开头, 以 b 结尾的长度 为3的任意字符串。如 acb 、 afb 等都满足该匹配串。
/* % 的应用*/
SELECT Sname,Sno,Ssex
FROM student
WHERE Sname LIKE '刘%';
/*_的应用*/
SELECT Sname,Sno,Ssex
FROM student
WHERE Sname LIKE '张_';
(6)涉及空值的查询
/*某些学生选修课程后没有参加考试, 所以有选课记录, 但没有考试成绩。 查询缺少成绩的学生的学号和相应的课程号。*/
SELECT Sno,Cno
FROM sc
WHERE Grade IS NULL;
(7) 多重条件查询
/*查询计算机科学系年龄在20岁以下的学生姓名AND*/
SELECT Sname,Sno,Ssex
FROM student
WHERE Sdept = 'CS' AND Sage < 20;
/*查询计算机科学系年龄或者20岁以下的学生姓名。OR*/
SELECT Sname,Sno,Ssex
FROM student
WHERE Sdept = 'CS' OR Sage < 20;
3. ORDERB子句
/*ASC升序*/
SELECT Sno,Grade
FROM sc
WHERE cno='3'
ORDER BY Grade ASC;
/*DESC降序*/
SELECT Sno,Grade
FROM sc
WHERE cno='3'
ORDER BY Grade DESC;
4. 聚变函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0VgyGrkb-1666405040528)(D:\大学四年经历\数据库\图片质料\聚变函数.png)]
/*查询学生总人数 ALL*/
SELECT COUNT(Sno)
FROM sc;
注: WHERE子句中是不能用聚集函数作为条件表达式的。 聚集函数只能用于SELECT子句和GROUP BY中的HAVING子句。
5. GROUP BY 语句
定义:对查询结果分组的目的是为了细化聚集函数的作用对象。 分组后聚集函数将作用千每个组,即每 组都有 个函数值。
/*求各个课程号及相应的选课人数。*/
SELECT Cno,COUNT(Sno)
from sc
GROUP BY Cno;
简而言之:GROUP BY 语句是对选中的列(属性)每一个元组,用聚变函数。不用GROUP BY 语句是对选中的列(属性)用聚变函数。
/*从中选择满足条件的元组。HAVING短语作用于组, 从中选择满足条件的组。*/
SELECT Cno,COUNT(Sno)
from sc
GROUP BY Cno
HAVING AVG(Grade) >= 90;
3.4.2 连接查询——多表查询
1. 等值与非等值连接
连接查询的WERE子句中用来连接两个表的条件称为连接条件或连接谓词, 其一般格式为
[<表名I>.]<列名1><比较运符符> [<表名2>]<列名2>
其中比较运算符主要有= 、 > 、 <、 >=、 <=、!= (或<>)等。
/*查询每个学生及其选修课程的情况。*/
SELECT student.*,sc.*
FROM student,sc
WHERE student.Sno=sc.Sno;
2. 自身连接——给自己取别名,代表各自信息
SELECTF FIRST.Cno,SECOND.Cpno
FROM Course FIRST,Course SECOND
WHERE FIRST.Cpno=SECOND.Cno;
3. 外连接
SELECT student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM student left outer JOIN sc on (student.Sno=sc.Sno)
这个概念在前面讲过,不多赘述。简而言之,左外——不包含右边集合独有的部分
4. 多表连接
连接操作除了可以是两表连接、 一个表与其自身连接外, 还可以是两个以上的表进行 连接, 后者通常称为多表连接。
3.4.3 嵌套查询
定义:在SQL语言中, 一个SELECT-FROM-WHERE语句称为一个查询块。将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询(nested query)。
/*查询学生表中在sc表中学号为2的学生姓名*/
SELECT Sname
FROM student
WHERE Sno IN (SELECT SnoFROM sc WHERE Cno='2');
1. 带有IN谓词的子查询
SELECT Sno,Sname,Sdept
FROM student
WHERE Sdept IN(SELECT SdeptFROM studentWHERE Sname='刘晨');
2. 带有比较运算守甘子查询
3. 带有ANY(SOME)或ALL谓词的子查询
4. 带有EXISTS谓词的子查询
EXISTS 代表存在量词,带有 EXISTS 谓词的了查询不返回任何数据, 只产生逻辑真“ true ” 或逻辑假值 “ false”。
子查询为真执行父查询,否则不执行
SELECT Sname
FROM student
WHERE NOT EXISTS(SELECT*FROM scWHERE sno=student.sno AND Cno='1');
3.5 视图
基本格式:CREATE VIEW<视图名> [(<列名> [,<列名>]…)J
AS<子查询>
[WITH CHECK OPTION]
3.5.1 视图的作用
- 视图能够件简化用户的操作
- 视图使用户能够以多种角度看待同一数据
- 视图对重构数据库提供了一定程度的逻辑性
3.5.2 视图的用法
与查询无异,不多赘述
在我看来,视图就是用来,装查询结果的。
![(九)密度聚类、层次聚类和轮廓系数[机器学习代码实现]](https://img-blog.csdnimg.cn/20210426192127604.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDk3Mjk5Nw==,size_16,color_FFFFFF,t_70)