文章目录
- 1. LaTex介绍
- 2. Texlive2019的下载和安装
- (1) 下载
- (2) 安装
- 3. TeXstudio的安装以及简单使用
- (1) 设置中文界面
- (2) 添加行号
- (3) 设置编译器与编码
- (4) 第一个简单程序
- 4. 扩展
1. LaTex介绍
LaTeX 基于 TeX,主要目的是为了方便排版。在学术界的论文,尤其是数学、计算机等学科论文都是由 LaTeX 编写, 因为用它写数学公式非常漂亮。
在稍微了解一点 LaTeX 后,你会发现 LaTeX 的工作方式类似 web page,都是由源文件(.tex or .html)经由引擎(TeX or browser)渲染产生最终效果(得到 PDF 文件 或者 生成页面)。两者极其神似,包括语法规则与工作方式。所以呢,与 HTML 一样,入门其实很简单。

一般的规范写法中都是在 HTML 文件中写入 web page 的结构与内容,再由 css 控制页面生成的样式。当然你也可以选择在 HTML 中直接写入样式内容,不过这并不提倡。同样,在 LaTeX 有着同样的情况,你可以在 tex 源文件中同时写入内容和样式,也可以内容与样式分离,以网络上流传广泛的 清华大学 LaTeX 模板为例,以.cls(class)结尾的 thuthesis.cls 便可看作是与 css 起到同样作用的样式文件。
LaTeX 有所谓宏包的概念,\usepackage{foo} 即可使用宏包 foo 中定义的内容。所谓宏包就是一些写好的内容打包出来以便大家使用而已。这跟 C 语言的 include 是一致的,将文件加载进来进行使用。利用宏包,我们可以使用很多现成的好用的样式。当然了,如果要编写一个自己的个性化的宏包也是可以的,不过需要学习成本。
初期的话,我们可以选择一个 LaTeX 模板进行改造。不过第一次见到一些模板,可能会对其中很多文件的作用一头雾水. 下面是简单的介绍。
| LaTeX模板常见文件类型 | 功能简要介绍 |
|---|---|
| .dtx | Documented LaTeX sources,宏包重要部分 |
| .ins | installation,控制 TeX 从 .dtx 文件里释放宏包文件 |
| .cfg | config, 配置文件,可由上面两个文件生成 |
| .sty | style files,使用\usepackage{…}命令进行加载 |
| .cls | classes files,类文件,使用\documentclass{…}命令进行加载 |
| .aux | auxiliary, 辅助文件,不影响正常使用 |
| .bst | BibTeX style file,用来控制参考文献样式 |
LaTex使用安装,主要要安装两样东西
-
根据平台选择一个 TeX 发行版 进行安装,建议选择最全功能最多的版本。
TeX 发行版的概念相当于 Linux 及其发行版,Linux 内核虽然只有一个,但是有很多基于内核的不同特色的 Linux 发行版,Ubuntu,Fedora 等等不胜枚举。
-
选择一个合适的LaTex编辑器
在安装好LaTeX环境以后,通常都会有一个自带的编辑器,比如 CTex 的WinEdt, MacTeX的TeXShop, 不过功能并不强大,好比 Windows 记事本,只有一些基本的文本编辑功能。
研究生写paper建议使用
Texlive + TeXstudio +JabRef
其中Texlive 选择用于TeX 发行版;TeXstudio 是LaTex编辑器,免费的;JabRef是管理文献的,这样子用于编写参考文献比较方便。
2. Texlive2019的下载和安装
(1) 下载
推荐下载用离线下载安装包,然后再安装的方式。可以使用官网的镜像下载,也可以利用国内的镜像下载。
官方下载网址: http://www.tug.org/texlive/
进入官网后,按以下操作进行:




然后选择texlive2019.iso点击进行下载。
可能官网下载比较慢,我们可以利用国内的镜像网站来下载,这样子下载速度快:
清华大学镜像文件 https://mirrors.tuna.tsinghua.edu.cn/CTAN/systems/texlive/Images/

(2) 安装
将texlive2019.iso 文件进行解压,然后双击打开其中的install-tl-advanced.bat文件。
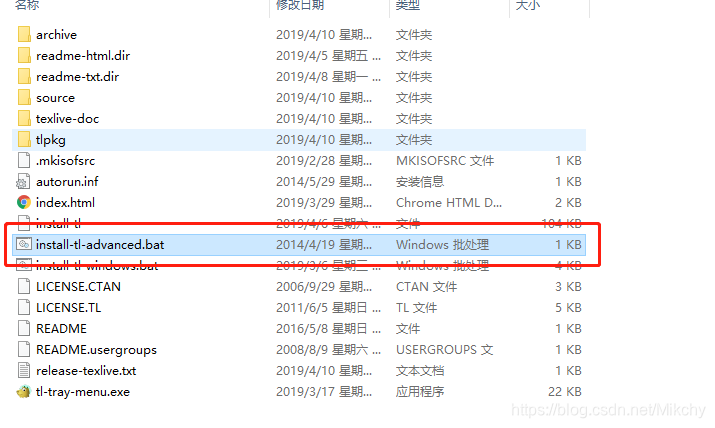
点击Advanced

然后依次按下图操作,修改安装目录,点击安装

接下来就是一个等待的过程,一般要安装一个小时左右。
当安装结束后,可以调出windows系统下的cmd,输入tex -version,如果出现版本号
TeX 3.14159265 (TeX Live 2019/W32TeX)
即说明安装成功。
接下来就是安装LaTex的编辑器,我们选用TeXstudio。
3. TeXstudio的安装以及简单使用
直接去官网下载(需要科学上网),要么选择网上找别人的网盘,这里我不提供网盘,百度搜一下会有很多的,官网地址:https://www.texstudio.org/
下载后直接点击安装,一样选择安装路径,这个和平时windows安装QQ之类的是一样的,简单。然后进行一些简单操作。
(1) 设置中文界面
安装结束后,一开始的打开界面是英文的,这里我们可以切换成中文。
依次点击:Options—> Configure Texstudio —> General—> Language—> zh_CN

(2) 添加行号
添加段落行号,这样可以很方便查看段落的某句话所在的位置,尤其是在运行报错时,有行号就非常方便查看错误的位置了。
依次点击:选项—>设置 Texstudio —>显示高级选项

(3) 设置编译器与编码
为了正常的输出中文,我们需要把编译器改成xelatex,utf-8编码
如果是为了编写英文论文的,那就下面第一张图不要改成“xelatex”,英文论文要用“pdflatex”


(4) 第一个简单程序
% 导言区
\documentclass{article} % 导入中文宏
\usepackage{ctex}% 构建命令,取别名,使用degree 代替 ^ circ
\newcommand\degree{^\circ}\title{\heiti 浅谈勾股定理}
\author{\kaishu 张一根}
\date{\today}
% 正文区
\begin{document}\maketitlehello world!勾股定理可以用现代的语言描述如下:直角三角形斜边的平方等于两腰的平法和。可以用符号语言描述为:设直角三角形 $\angle C=90\degree $则有:$$ AB^2 = BC^2 + AC^2 $$这就是勾股定理
\end{document}
新建一个 .tex 文件后,将上述代码复制粘贴进去,然后,点击下图中的构建并查看

从而在软件界面的右边就出现了编译后的界面

4. 扩展
LaTeX主要的就是利用模板,所以一般如果写论文的,导师或者投稿的那里都会有模板拿来使用的,因此最主要的就是
知道如何编写数学公式
还有论文写作的时候,要有参考文献,一般一个个加参考文献,但是这种情况下,对于少量参考文献还可以。当有大量的参考文献存在时,就会很麻烦,因此,推荐使用JabRef