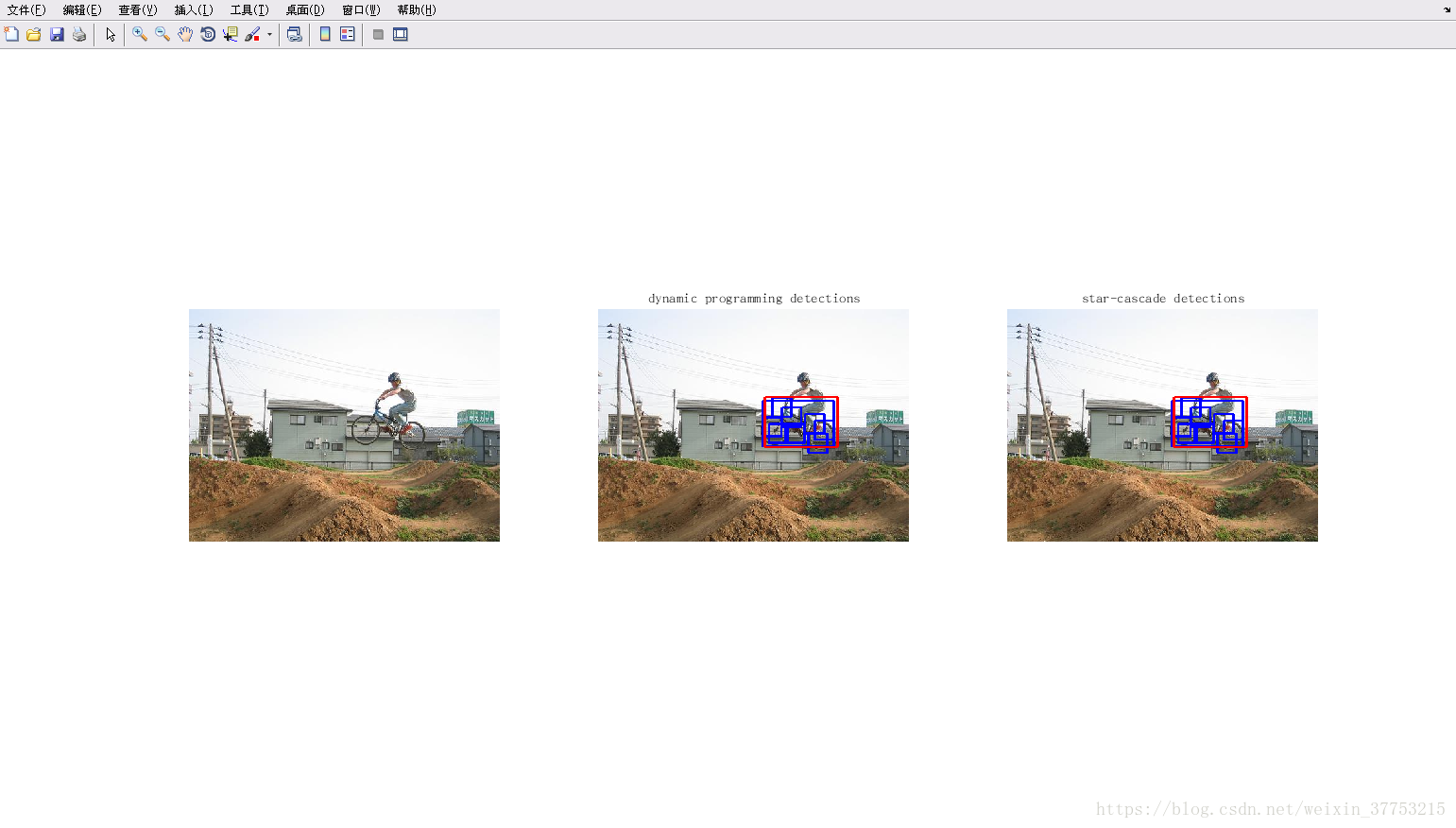
元学习论文总结||小样本学习论文总结
2017-2019年计算机视觉顶会文章收录 AAAI2017-2019 CVPR2017-2019 ECCV2018 ICCV2017-2019 ICLR2017-2019 NIPS2017-2019
提出了一种建立三维密集语义地图的方法,采用GPU,ROS消息通信无法支持。
摘要
三维(3D)点云的理解对于自主机器人是重要的。然而,点云通常是不规则的和离散的。从它们中获得语义信息是很有挑战性的。本文提出了一种利用二维(2D)图像标签和3D几何信息建立稠密语义图的方法。密集点云是通过使用最新的RGB-D SLAM系统来构建的。使用基于图的方法将其进一步分割为有意义的簇。然后,通过卷积神经网络(CNN),利用SLAM过程中的图像关键帧提取语义图像标签。最后,将这些语义标签投影到点云簇,以实现3D密集语义图。在一个著名数据集中验证了我们方法的有有效性。
1 介绍
场景理解是自主驾驶和移动机器人的关键。最近的研究集中于场景重建以构建3D稀疏或密集图,如运动融合[1]、弹性融合[2]和动态融合[3]等。然而,这些地图中没有语义信息,机器人无法从中获得对周围环境的语义层次的理解。事实上,近几年来,二维图像的语义分割取得了很大的进展。在CNN的帮助下,我们可以分析图像中的二维语义信息,如FCN[4]、u-net[5]、SegNet[6]、Refinenet[7]、pspnet[8]和Depplab[9-11]中的语义信息。同时,三维点云语义分割是计算机视觉领域的一个热点问题,近年来取得了很大的进展,包括PointNet [12], PointNet++ [13] and PointCNN [14].然而,这些方法仅仅是利用三维信息来分析点云。
实际上,点云可以由rgb-d SLAM产生,例如orb-slam 2[15],使用像Asus Xtion这样的廉价RGB-d传感器。在RGB-d SLAM中,RGB图像具有丰富的纹理信息,点云具有几何信息.在三维语义分割和映射中,现有的方法大多采用RGB图像或点云作为输入。然而,很少有方法同时利用二维和三维信息。本文介绍了一种将二维和三维信息融合在一起建立密集语义图的系统。本文的主要贡献可归纳如下:
-
一种有效的三维点云分割方法
-
融合二维图像信息和三维几何信息的三维点云语义标记方法
-
三维密集语义映射系统
2 相关工作
2.1 语义SLAM
传统的即时定位与地图构建(SLAM)系统主要集中在使用低层次的几何特征,如点、线、平面等,无法提供语义信息。语义SLAM可以给出环境的语义信息。它可以帮助机器人从几何和内容两方面来理解周围的场景。Salas-Moreno等人。提出了SLAM++[16],能够在RGB-d跟踪和映射中实现目标检测.John McCormac等人研究的语义SLAM是语义融合[17]。该方法利用卷积神经网络生成类概率图,并将预测结果融合到三维映射中。Keisuke Tateno等人提出了一个实时密集的cnn-SLAM[18]。在CNN的帮助下,CNN-SLAM不仅可以进行深度预测,还可以进行语义分割。da-RNN[19]提出了一种新的递归神经网络(RNN)结构,用于RGB-d视频的语义标注,它利用多个视点中的信息来提高分割性能。Tong结合了场景检测方法促成的不同SLAM系统。
2.2 二维目标检测与语义分割
目标检测是获取语义信息的一个重要组成部分,它可以对图像中的对象实例进行定位。girshick等人[21]介绍了R-CNN,提出将CNN应用于目标检测。最近几年提出了其他类似的方法,如快速r-cnn[22],更快的rcnn[23],掩膜-rcnn[24]和yolo[25-26]。R-CNN使用选择性搜索算法生成区域提案,运行速度非常慢.更快的r-cnn用快速神经网络取代了慢选择搜索算法.掩码r-cnn改进了感兴趣区域(Roi)池层,并将r-cnn扩展到像素级图像分割。
语义分割是理解图像的像素级,它可以用类标识标记每个像素。与目标检测类似,最先进的语义分割方法也依赖于cnn.FCN[4]由Long等人提出。是第一个端到端的系统,它推广cnn的语义分割架构.U-net[5]是一种比较流行的编解码结构,它能更有效地利用带注释的样本,具有更高的精度。SegNet[6]是一种类似的编码解码器结构。SegNet将索引从最大池复制到上采样,从而提高了内存效率.Refinenet[7]提出了一种融合高分辨率和低分辨率特征的细化块方法。解决了图像分辨率大幅度下降的问题。
2.3 三维点云分割与语义分析
点云分割是将点云分割成不同区域的过程,每个区域都具有相似的特性。这是从点云理解场景的重要一步。在机器人环境建模等特定应用的推动下,三维点云分割成为一个非常活跃的研究课题。点云库(PCL)[27]是一种流行的提供开放资源分割算法的库。早期的方法[28]使用RANSAC来检测点云中的平面,然后用欧几里德分离来分割物体。在二维图像处理中提出了区域生长算法[29]。后来,它被用于与三维点云相关的工作中。Rabbani等人[30]提出了一种基于平滑约束的点云分割方法,该方法可以在点云中找到平滑的连通区域。Vo等人[31]提出了一种新的基于八叉树的区域生长算法,用于城市环境中三维点云的快速曲面分割。Stein等人[32]利用局部凸连通块(Lccp)算法将点云划分为若干个分段,利用法向量判断局部凸性。Golovinskiy等人[33]提出了一种基于最小切分的点云对象分割方法,该方法既适用于自动分割,也适用于交互式分割。
与二维图像不同,三维点云是不规则的、无序的。因此,像卷积这样的二维图像处理中常用的方法是不适合它们的。最近,基于深度神经网络的三维点云分类和分割方法被提出,如点网[12]和点网[13]。点网可以直接从无序点云中学习,它结合了局部点特征和全局信息来进行三维分割。在点网络的基础上,引入一种分层神经网络来学习局部特征,使其具有更高的上下文尺度,能够高效、可靠地学习深点集特征。Pointcnn[14]提出了一种名为x-变换的新方法,它可以利用CNN进行点云处理。然而,这些方法仅使用点云信息,这很难扩展到语义标记。
3 基于深度学习的三维点云语义标注
我们的系统基于ORB-slam 2[15],由3个模块组成:视觉SLAM模块、点云分割模块和语义标记模块。我们使用基于关键帧的更新策略来生成点云数据。当插入关键帧时,我们使用修改的深度学习框架对其进行处理以获得对象标签。此外,我们用一种基于图的方法对点云进行分割.最后,我们将图像标签投影到点云段,以实现点云的语义标记。上面的过程如图1所示。

3.1视觉SLAM模块
VisualSLAM模块从RGB-d数据集生成点云数据,该数据集将由点云分割模块进一步处理。VisualSLAM模块工作在三个线程中:跟踪线程、局部映射线程和循环关闭线程。
跟踪线程负责从原始RGB图像中提取和匹配灰度图像中的球体特征,以便对摄像机进行定位。此外,它还决定何时插入新的关键帧。
局部映射线程的重点是构建局部三维稀疏映射。它通过执行局部束调整(Ba)来优化本地映射和关键帧构成。为了生成点云数据,只使用关键帧,而其他帧用于计算摄像机的姿态。点云是通过将深度图像中的三维点从摄像机坐标系转换到世界坐标系来生成的。我们还在这个线程中获得了一个粗略的语义图,这将在SectSect3.3.中进行描述。
环路关闭线程检测外观循环,然后通过位姿图优化校正累积漂移。它是通过在关键帧之间使用(a bag-of-words)方法来实现的.
3.2.点云分割模块
在点云分割模块中,只依靠几何信息对点云进行分割,而点云对应的图像纹理对分割结果没有影响。首先,我们使用超体素方法[34]分割原始点云,如图2所示。这样,不仅可以减少计算量,而且还可以根据点的相似性将点云转换成曲面块。supervoxel超体素的结果可以用邻接图G表示,其中v是补丁,sigema连接相邻的补丁vi和vj。![]()

在超体素处理后,每个曲面片上都有一个质心ci和一个法线向量ni。场景分割可以被描述为一个图分割问题。如图3所示,节点是表面补丁,每个节点都属于一个对象。我们应该确定边缘是开的还是关的。
使用欧氏距离[35]和均值移位算法[36]计算节点间的相似性是一种常见的方法。然而,该方法具有较高的计算复杂度。法向量[32]是局部凸性信息的反映,可用于聚类。然而,当点云中有更高百分比的噪声时,它就变得不可靠了。因此,我们建议融合支持平面来抑制这种负面影响。假设我们在点云中有k个支持平面s1-sk,并且在这些平面上得到了曲面片。我们定义了变量...(本节后半段为实现细节,不深究)
在完成平面提取后,得到平面l和曲面块k,直接用基于快速图的[37]方法进行分割。
3.3.语义标注模块
由orb-slam 2生成的原始地图没有语义信息(参见图4(A),这只是一组不规则的无序点。我们借助深度学习框架在点云中执行语义标记。
我们使用修改的Yolov3[26]框架来检测由sam模块提取的关键帧中的对象。标签的图像边界在2D图像中不够精确(见图4(b)),但是我们可以将2D语义标记投影到3D点云,以实现合理的3D语义映射,如图4(c)所示。然而,它是一个粗略的语义图,并且不够精确到使用。如前所述,我们已经执行点云分割,然后我们可以对分割和粗略语义映射进行融合,以提高映射性能。原始标签来自RGB图像,这里我们利用2d标签和3D片段结果来执行语义段。最后,点云中的每个对象区域都得到一个特定的语义标签。有关这一进程的更多细节将在第4.3节中进一步说明。

4.实验和结果
我们评价了我们的系统使用流行的tum数据集[38]。在不需要训练神经网络进行语义标注的情况下,我们只关注于用几种已知的对象来验证我们的三维语义映射方法。
4.1.实验装置
该系统运行在一个带有ubuntu 14.04 64位操作系统的笔记本电脑上,一个英特尔核心i5-6300HQ(4核@2.3GHz)CPU,16g DDR 4 ram和一个gtx 690GPU。我们的视觉SLAM模块能够达到实时性能.在GPU的帮助下,yolo v3能够以每秒8帧的速度检测图像。
4.2.点云段结果
在此实验中,我们通过将分割结果与其他现有方法进行比较,定性地评价了点云分割方法。局部凸连接修补程序(LCP)方法仅使用局部凸性或凹度进行分割,忽略全局几何信息。
缺乏全局信息可能导致错误的分段结果,如图5(A)所示,lccp方法无法从室内场景分割诸如键盘这样的小对象。
区域生长法根据种子点的曲率值对种子点进行初始化,然后通过添加邻域点来增加种子点的各个区域。然而,该方法对噪声数据敏感。在段结果中,我们可以看到背景对象墙和前台对象桌面是混合的(参见图5(B)。
因此,我们采用超体素方法来降低时间开销,同时利用支持平面等全局信息和局部信息来获得更好的分割效果。我们可以检查不同的方法是否可以分割点云中的对象。如图5(C)所示,我们的方法能够分割室内场景中的大多数对象。
此外,基于一种有效的基于图的分割方法,我们的分割方法比lccp和区域增长方法更快。在本实验中,我们的SLAM系统使用了82060 RGB图像和82060张深度图像来构建一个包含952563个点的三维点云地图。我们的系统能够在5秒内完成分割。这些方法的时间费用见表1。


4.3 点云中的语义分割结果
我们的视觉Slam模块使用Yolov3获取对象标签并将其投影到点云。点云具有XYZ和RGB信息,表示每个点的欧氏坐标和颜色数据(参见图6(a))。此外,点云具有2D图像的语义信息。点云分割后,我们还获取每个点的段标签(参见图6(b))。然而,该分段标签仅仅是没有语义含义的随机标签。然后我们可以融合两个点云,将语义信息与段标签结合起来,从而得到图6(c)所示的最终语义点云。
事实上,两点云有相同数量的点,我们可以使用PCL库来融合它们。融合后,不仅可以对分割结果进行校正,还可以进行语义标注。通过这种方式,我们将二维图像标签转换为三维点云标签。顺便说一句,我们的语义标记模块不能达到实时的性能,但是它对于视觉SLAM系统来说是一个有用的模块。
YoloV3接受了包含80个类的Coco1数据集的训练。然而,我们只在我们的室内场景(杯子、键盘、监视器、鼠标、泰迪熊)中检测到几个类作为兴趣对象。CocoDataSet中的大多数类是室外对象类,这些类在我们的实验中不存在。

(YOLO模型)https://blog.csdn.net/guleileo/article/details/80581858
(YOLO模型)https://pjreddie.com/darknet/yolo/
5. 结论
本文提出了一种将二维对象标记和三维点云分割相结合的方法来实现视觉SLAM中的三维语义映射。提出了一种基于图形的三维点云分割方法。本文的另一个贡献是融合了2d和3D信息来建立一个密集的语义图。我们共享github上的源代码。此外,视频演示可以在线上找到。
数据集:http://cocodataset.org
源码:https://github.com/qixuxiang/orb-slam2_with_semantic_label
视频:http://v.youku.com/v_show/id_XMzYyOTMyODM2OA