文章目录
- 一、项目背景
- 二、项目功能
- 三、项目的基本流程
- 1.准备工作
- 2.数据库设计
- 3.准备前端页面
- 4.实现前端匹配的Servlet所需功能
- 5.项目难点
一、项目背景
在学习完JavaWeb相关知识后,有了基础能力就想通过完成一个Javaweb项目来回顾和加强已经学过的知识,并且希望在这个过程中发现自己的不足并加以改正。
由于之前一直都在CSDN上分享自己的学习过程,对CSDN博客系统的功能有了一定的了解,因此便尝试完成了个人博客系统。
二、项目功能
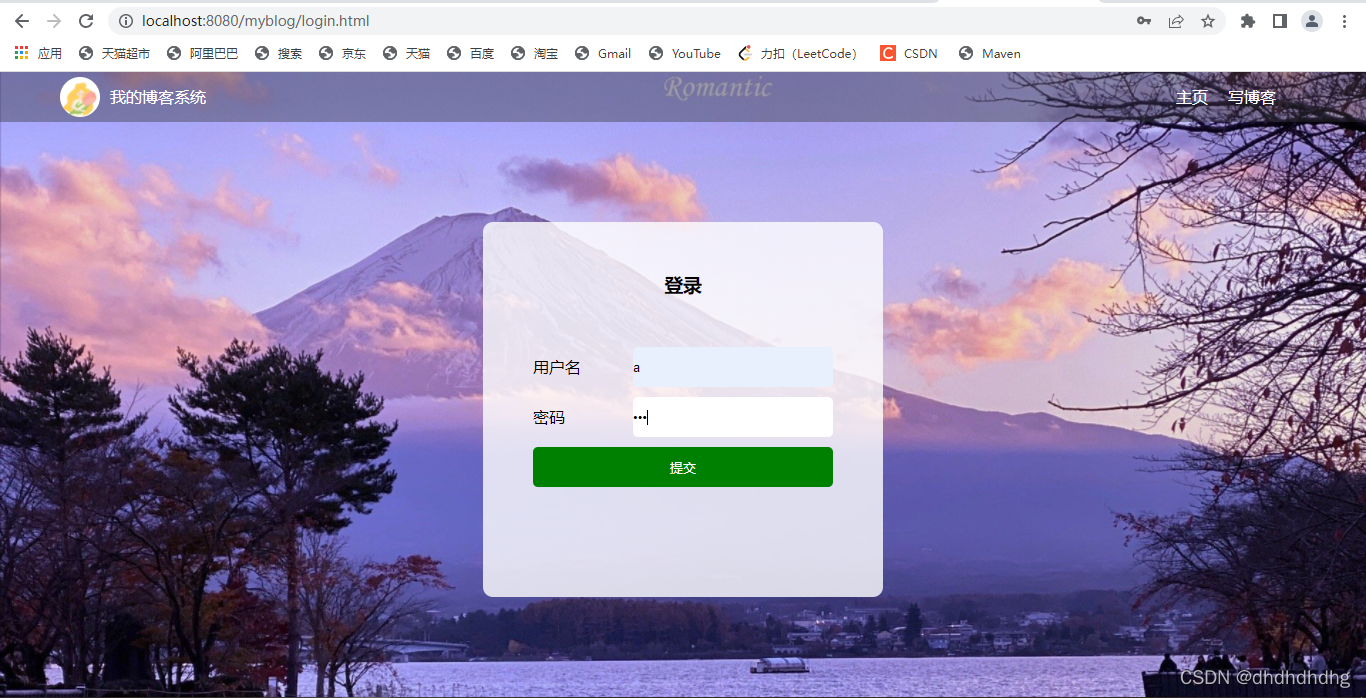
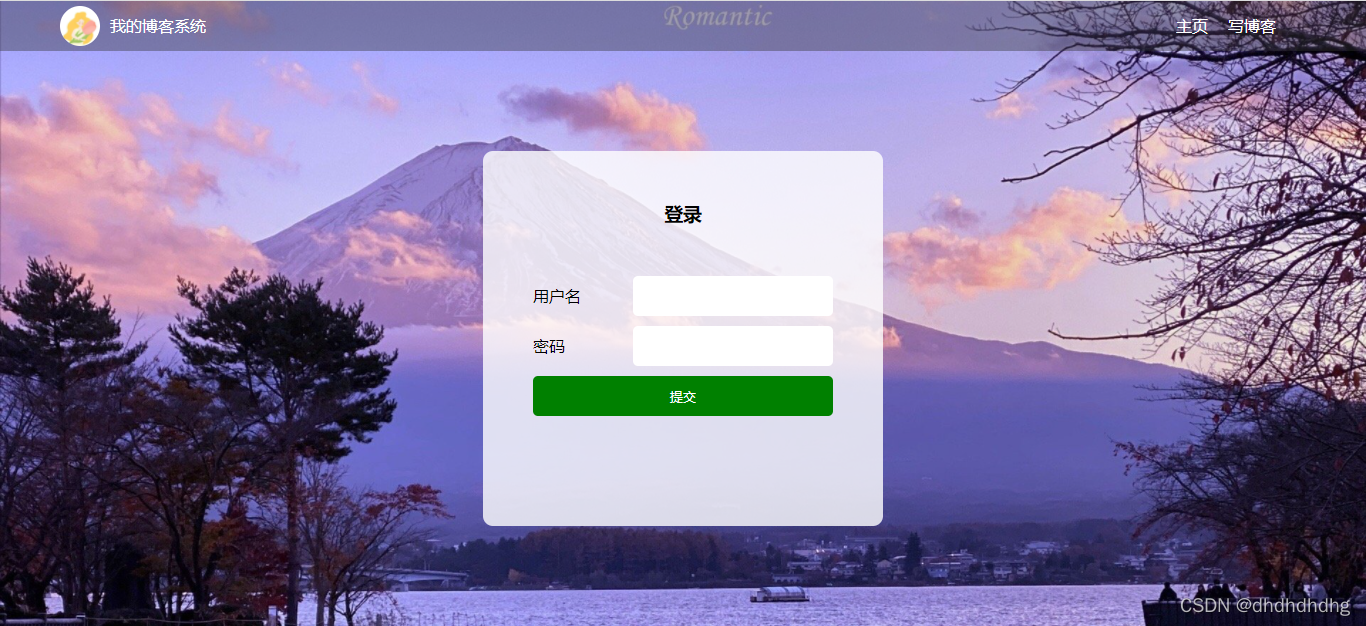
1.用户登录:
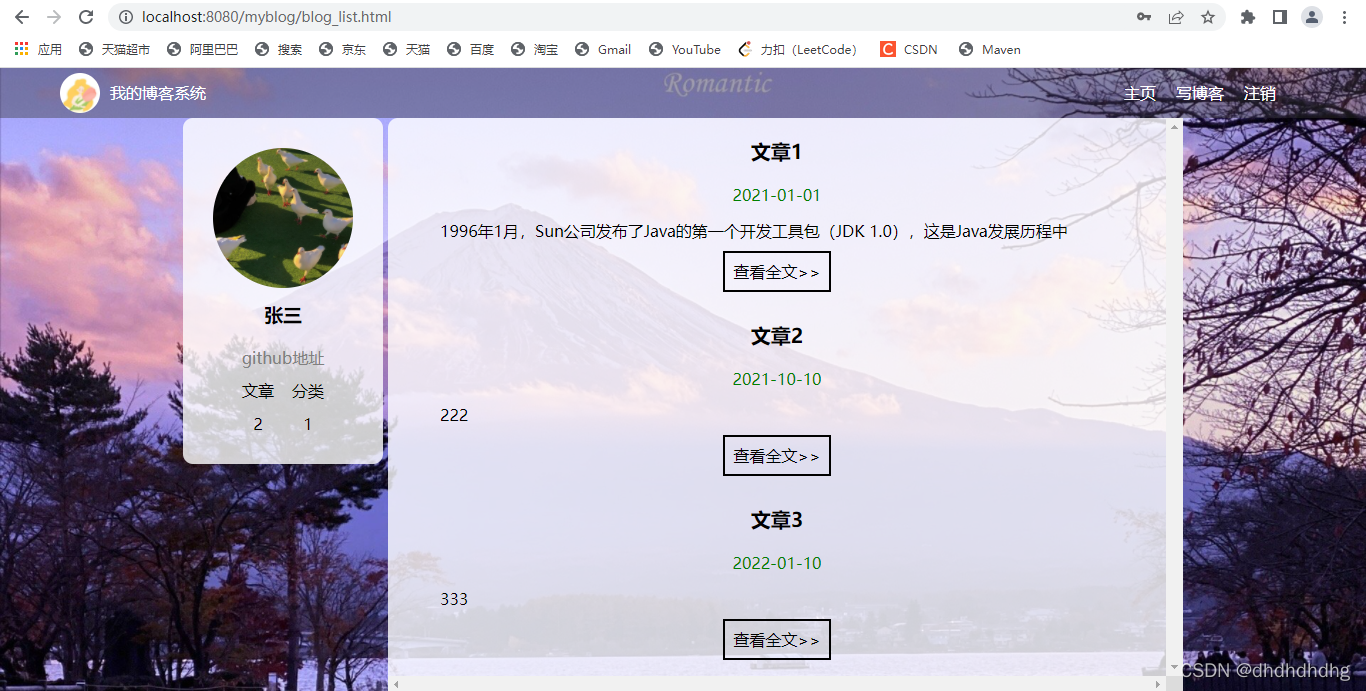
2.用户主页:
3.查看全文:
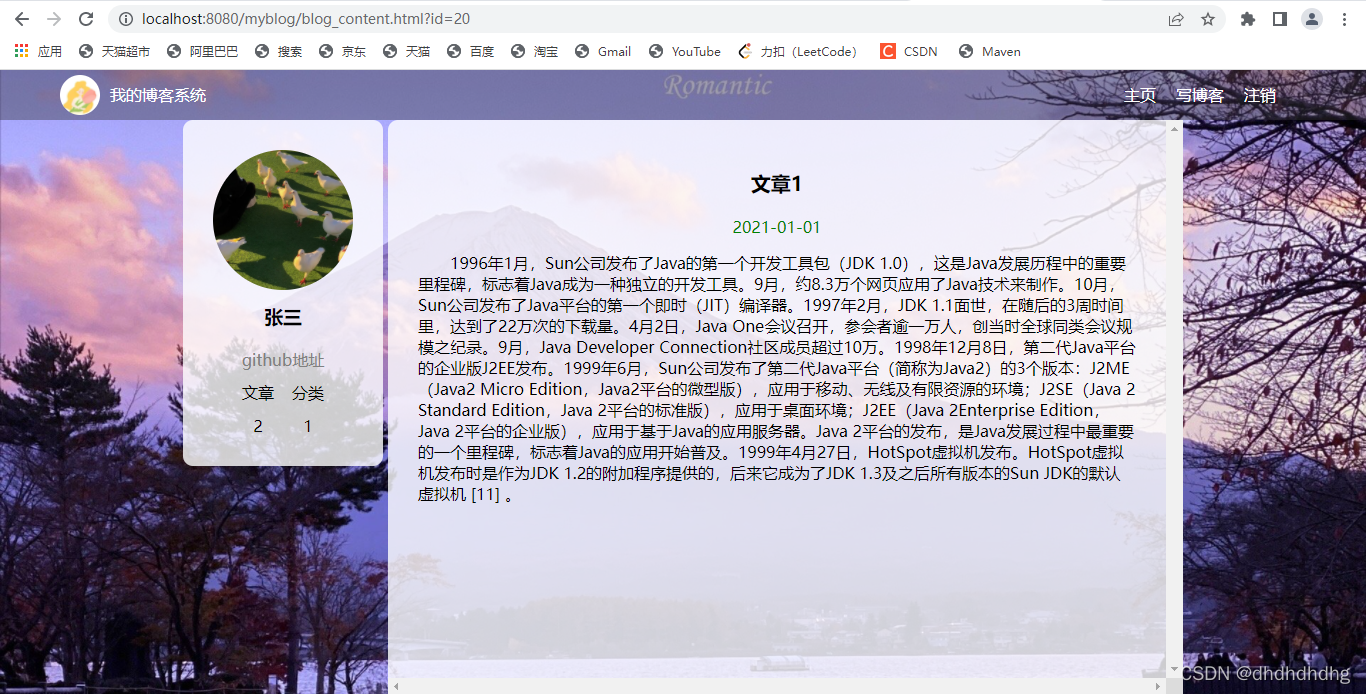
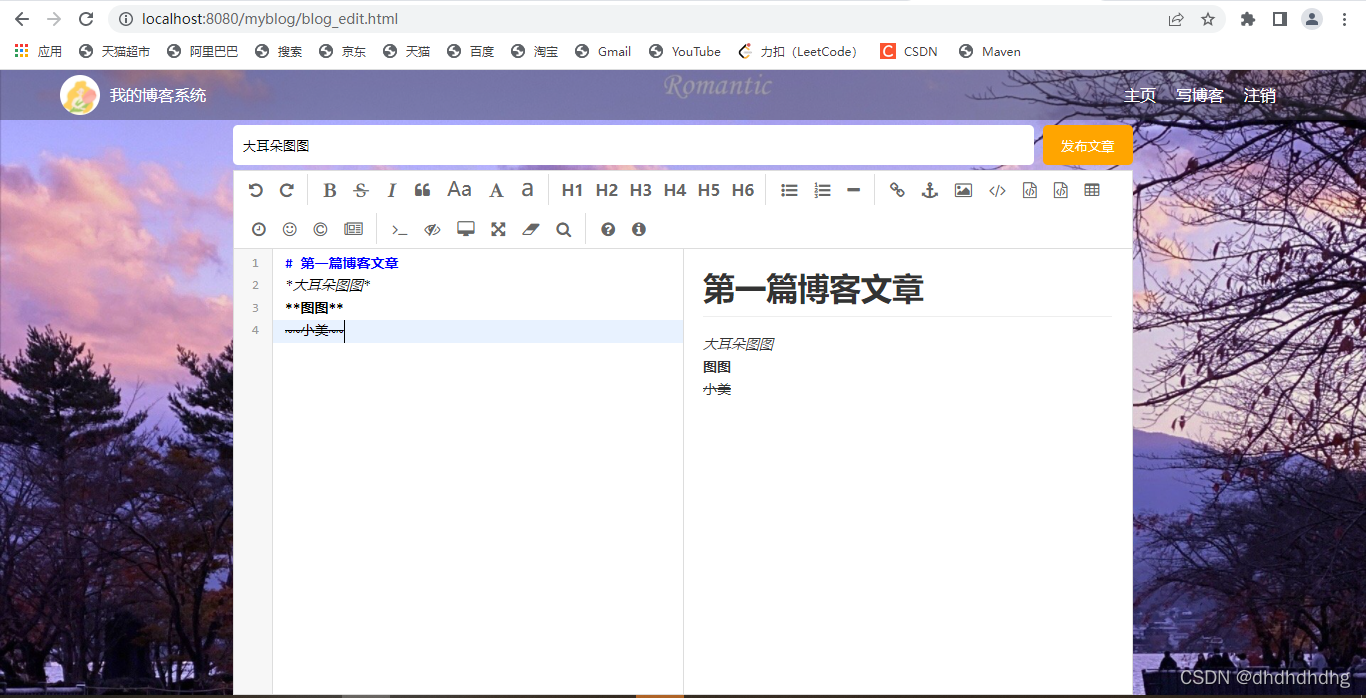
4.写文章:
5.注销回到登录页面:
三、项目的基本流程
1.准备工作
pom.xml中引入的依赖包
<dependencies><dependency><groupId>org.thymeleaf</groupId><artifactId>thymeleaf</artifactId><version>3.0.12.RELEASE</version></dependency><!-- Servlet依赖包:官方提供的servlet标准 --><dependency><groupId>javax.servlet</groupId><artifactId>javax.servlet-api</artifactId><version>3.1.0</version><!-- 开发编译时需要这个依赖包,运行时不需要 --><scope>provided</scope></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.49</version></dependency><!-- 数据绑定包,提供JAva对象与JSON数据格式进行序列化 --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.12.3</version></dependency><!-- 引入单元测试框架,方便我们做测试 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.1</version></dependency>
</dependencies>
引入Jackson依赖是为了进行序列化、反序列化的操作
作用:使数据和对象之间可以相互转换,保证数据的完整性
Jackson是一个Java用来处理JSON格式数据的类库,性能非常好,经常被用来JSON序列化(将对象转换为JSON字符串)和反序列化(将JSON字符串转换为指定的数据类型)
序列化和反序列化操作:
public class WebUtil {//判断是否登录,通过请求对象获取session,如果session存在且登录时// 保存的键为user,值是用户对象,这个数据存在,就表示已登录//返回user:已登录就返回session中保存的用户,未登录返回nullpublic static User checkLogin(HttpServletRequest req){User user = null;//如果从tomcat保存的session的map数据结构中,获取session,false表示获取不到,返回nullHttpSession session = req.getSession(false);if(session!=null){user = (User)session.getAttribute("user");}return user;}//这个对象可以使用单例private static ObjectMapper M = new ObjectMapper();//反序列化:转换一个输入流中包含的json字符串为一个java对象//使用泛型:传一个什么类型给我,就返回一个该类型的对象public static <T> T read(InputStream is,Class<T> clazz){try {return M.readValue(is,clazz);} catch (IOException e) {throw new RuntimeException("json反序列化出错",e);}}//序列化:将一个任意类型的java对象,转换为一个json字符串public static String write(Object o){try {return M.writeValueAsString(o);} catch (JsonProcessingException e) {throw new RuntimeException("json序列化出错",e);}}
2.数据库设计
1.创建所需表:
- user(用户表)
- acticle(文章表)
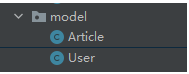
2.设计与之对应的数据库实体类:
3.数据库连接工具:
//数据库工具类:提供获取数据库连接,释放资源的统一代码
public class DBUtil {//静态变量,是类加载的时候初始化,只执行一次private static MysqlDataSource ds;//一个程序,连接一个数据库,只需要一个连接池,其中保存了多个数据库连接对象//1.获取连接池,内部使用,不开放private static DataSource getDataSource(){//ds类加载的时候,初始化为null,方法使用的时候,每次都判断一下if(ds==null){//判断为空,就创建及初始化属性ds=new MysqlDataSource();ds.setURL("jdbc:mysql://127.0.0.1:3306/blog");ds.setUser("root");ds.setPassword("010124");ds.setUseSSL(false);//不安全连接,如果不设置,也不影响,只是有警告ds.setCharacterEncoding("UTF-8");}return ds;}//2.获取数据库连接对象:开放给外部的jdbc代码使用public static Connection getConnection(){try {return getDataSource().getConnection();} catch (SQLException e) {throw new RuntimeException("获取数据库连接出错,可能是url,账号密码写错了",e);}}//3.释放资源//查询操作需要释放三个资源,更新操作(插入,修改,删除)只需要释放前两个资源public static void close(Connection c, Statement s, ResultSet r){try {if(r!=null) r.close();if(s!=null) s.close();if(c!=null) c.close();} catch (SQLException e) {throw new RuntimeException("释放数据库资源出错",e);}}//提供更新操作方便的释放资源功能public static void close(Connection c, Statement s){close(c,s,null);}public static void main(String[] args) {System.out.println(getConnection());}
}
4.用户表和文章表的CRUD操作(Dao类):
3.准备前端页面
1.把之前写好的前端静态页面部署到webapp目录下
2.封装ajax:
在前后端交互中我们需要用到ajax进行数据交互
把之前封装好的ajax函数拷贝过来,放到一个单独的js文件中,方便后续使用
function ajax(args){//var ajax = function(){}let xhr = new XMLHttpRequest();// 设置回调函数xhr.onreadystatechange = function(){// 4: 客户端接收到响应后回调if(xhr.readyState == 4){// 回调函数可能需要使用响应的内容,作为传入参数args.callback(xhr.status, xhr.responseText);}}xhr.open(args.method, args.url);//如果args中,contentType属性有内容,就设置Content-Type请求头if(args.contentType){//js中,if判断,除了判断boolean值,还可以判断字符串,对象等,有值就为truexhr.setRequestHeader("Content-Type", args.contentType);}//如果args中,设置了body请求正文,调用send(body)if(args.body){xhr.send(args.body);}else{//如果没有设置,调用send()xhr.send();}
}
3.设计一个类:用于返回给前端ajax回调
//设计一个类,用于返回给前端ajax回调
public class JsonResult {private boolean ok;//表示执行一个操作是否成功private Object data;//操作成功,且是一个查询操作,需要返回一些数据给前端//同样省略getter、setter和toString
}
4.实现前端匹配的Servlet所需功能
5.项目难点
- 实现用户不登录不允许访问主页内容并且重定向到登录页面,其次用户不登录的情况下访问某个接口也是非法的,也要重定向到登录页面
- 文章发布后要将新的一篇文章插入到数据库中,查看全文要将markdown格式的数据转为HTML
- 登录成功也要创建session并保存用户信息以供后面使用