手把手教学超详细python通用爬虫分布式框架(一)
` 这里日后添加系列文章的所有文章的目录
文章目录
- 手把手教学超详细python通用爬虫分布式框架(一)
- 前言
- 一、所谓任务?
- 二、任务需要什么
- 1.启动格式
- 2.任务执行流程分析
- 3.任务灵活化
- 总结
前言
采用 vue+flask,无高难度技术
爬虫越来越难,幸好公司爬的网站比较简单,我也逐渐学习了爬虫的分布式运维,记录下过程。
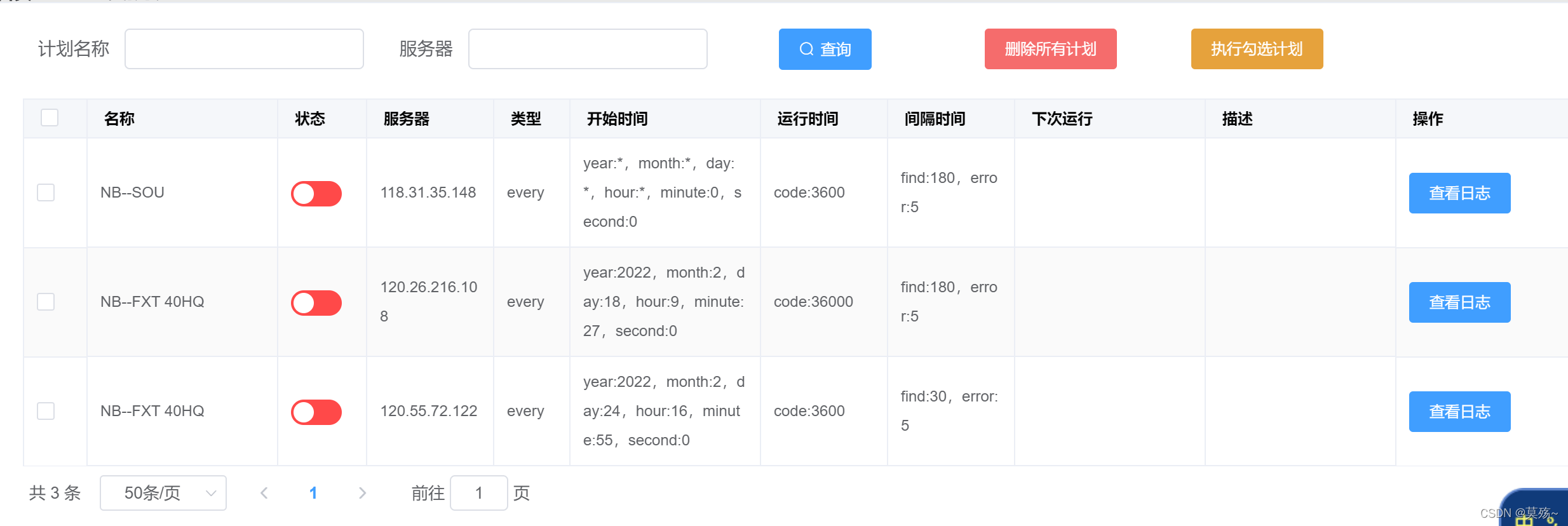
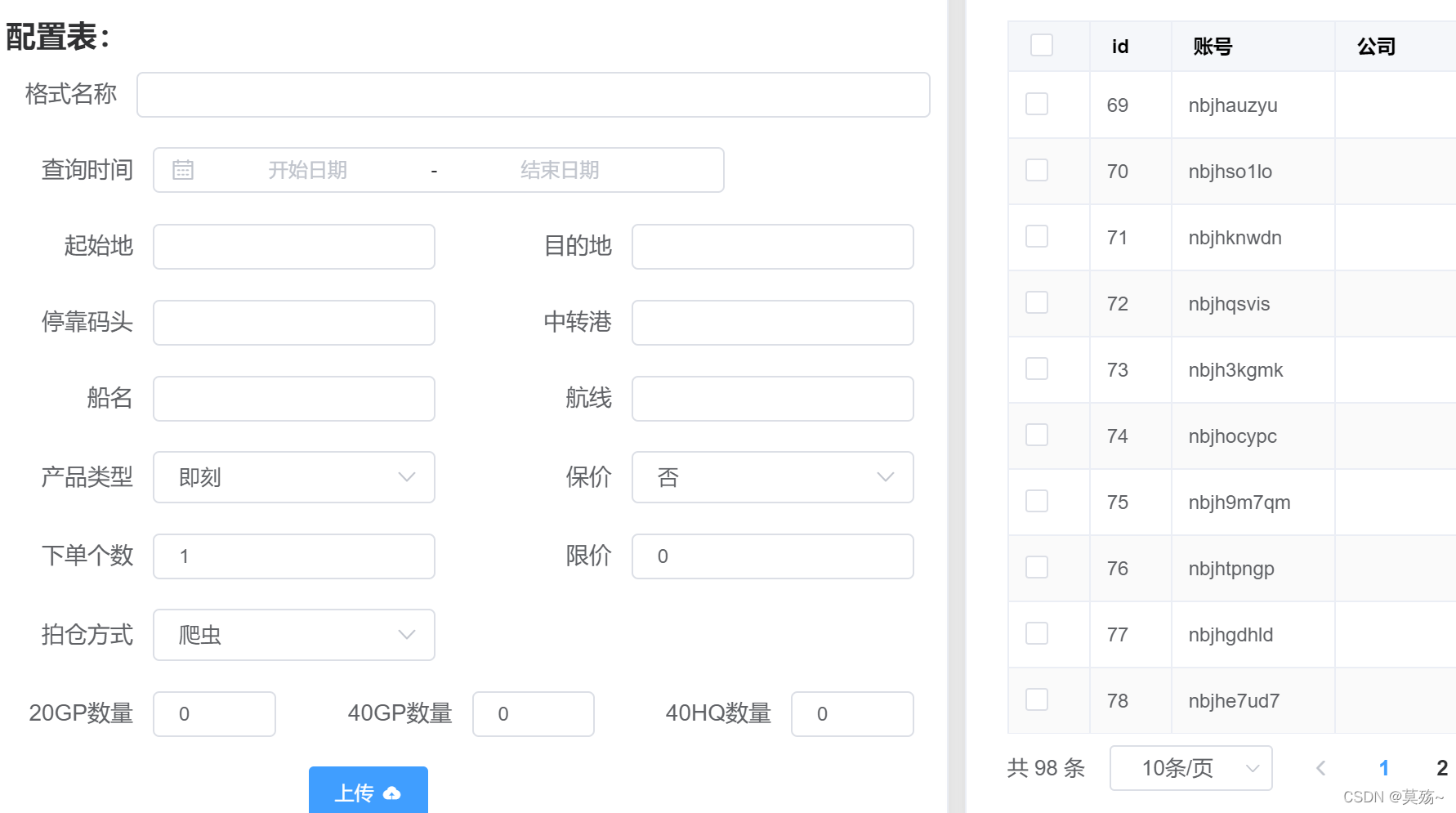
ps:一些不通用的分布式框架在我的git上可以下载,界面大致是这样:
一、所谓任务?
既然是分布式爬虫,总要有个任务去跑,但是每个爬虫所要的参数不同如何通用呢?没错,就是传json。
二、任务需要什么
我认为任务不仅包含爬虫运行的参数,还需要所在容器、运行时间,我们爬虫重要的还有长任务的请求间隔时间。
注意:其中很多参数是通用分布式客户端所搭配的,格式搞清楚了我们的客户端写完就再也不需要修改,一劳永逸。
1.启动格式
如下(示例,还有很多我没写):
work = {"runing": 3600, # 运行时间"spider_start_time":2022-04-01 00:00:00,#启动时间"interval_time": { # 相关间隔时间"aaa_com_request": 5, # aaa.com请求间隔"aaa_com_error": 60, # aaa.com报错重试间隔"once_work": 10, # 每次任务间隔},"code_addres": { # 代码所在地址,rpg、http模式。(后面会说)"type": "rpg","address": "","code_name": "spiderName","version": 2},"up_res": { # 上传结果"type": "redis","addres": '1.1.1.1',"key": "","name": ""},"spider_params": { # 爬虫参数"arg1": "","arg2": 2,}
}
2.任务执行流程分析
参数好了还不行,一些参数是后期添加的,比如容器、结果、状态等,我的导图:
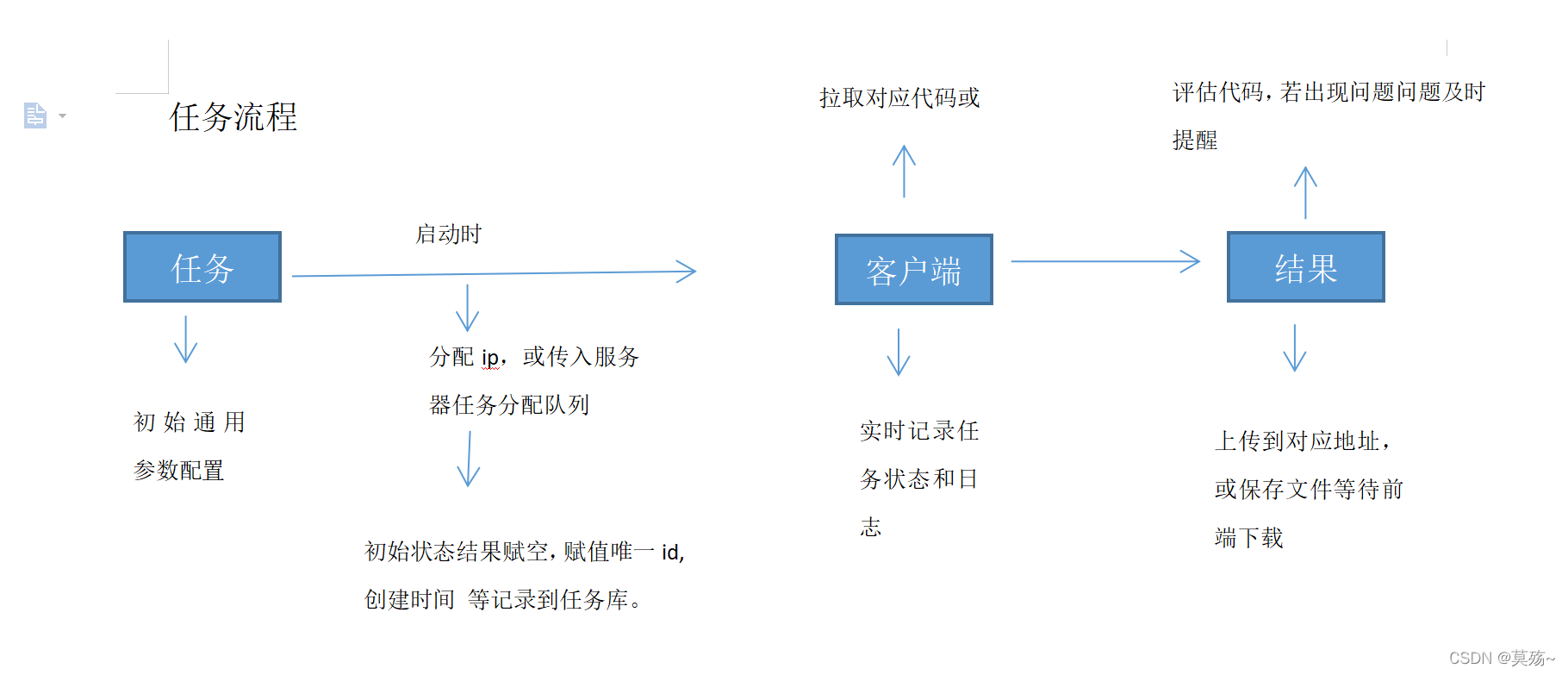
暂时的导图,还有没考虑的我会及时更新
3.任务灵活化
我们要搞的是通用分布式,既然这样格局要打开,关于任务讲究的就是: 通用且具有表达,优雅而不失细节。
总结
这次就讲任务设计模式,接下来还有总体思路,服务端设计,代码库设计,通用客户端(一劳永逸版)等。。。。。。