学Python的同学,SQL也一定要学习,SQL几乎是每个数据岗的必备题目,下面分享几个常见的大厂SQL习题。
(1)找出连续7天登陆,连续30天登陆的用户(小红书笔试,电信云面试),最大连续登陆天数的问题 --窗口函数
(2)求连续点击三次的用户数,中间不能有别人的点击 ,最大连续天数的变形问题(腾讯微保面试)–窗口函数
(3)计算除去部门最高工资,和最低工资的平均工资(字节跳动面试)–窗口函数
(4)留存的计算,和累计求和的计算 --窗口函数,自联结(pdd面试)
(5)AB球队得分流水表,得到连续三次得分的队员名字 和每次赶超对手的球员名字,(pdd面试)
把这几类题型吃透,再也不怕手撕SQL和笔试了,其中最难的是题(5),整个面试的sql基本上都是窗口函数的玩法,搭配case when 也考得比较多。喜欢本文记得收藏、关注、点赞。
【注】文末关注公众号,获取一份面试真题
(1) 找出连续7天登陆,连续30天登陆的用户
select *
from
(select user_id ,count(1) as numfrom(select user_id,date_sub(log_in_date, rank) dtsf rom (select user_id,log_in_date, row_number() over(partitioned by user_id order by log_in_date ) as rankfrom user_log)t)agroup by dts
)b
where num = 7
(2)求连续点击三次的用户数,而且中间不能有别人的点击,
a表记录了点击的流水信息,包括用户id ,和点击时间
usr_id a a b a a a aclick_time t1 t2 t3 t4 t5 t6 t7
row_number() over(order by click_time) as rank_1 得到rank_1为 1 2 3 4 5 6 7
row_number() over(partition by usr_id order by click_time) 得到rank_2 为 1 2 1 3 4 5 6
rank_1- rank2 得到diff 为 0 0 2 1 1 1 1
这时我们发现只需要对diff进行分组计数大于3个,就是连续点击大于三且中间没有其他人点击的用户
select distinct usr_id
from
(select *, rank_1- rank2 as difffrom(select *,row_number() over(order by click_time) as rank_1row_number() over(partition by usr_id order by click_time) as rank_2from a) b
) c
group by diff,usr_id
having count(diff) >=3
(3)计算除去部门最高工资,和最低工资的平均工资(字节跳动面试)–窗口函数
emp 表
id 员工 id ,deptno 部门编号,salary 工资
核心是使用窗口函数降序和升序分别排一遍就取出了最高和最低。
select a.deptno,avg(a.salary)
from (select *, rank() over( partition by deptno order by salary ) as rank_1, rank() over( partition by deptno order by salary desc) as rank_2 from emp) a
group by a.deptno
where a.rank_1 >1 and a.rank_2 >1
(4) 留存的计算,和累计求和的计算 --窗口函数,自联结(pdd面试)
手机中的相机是深受大家喜爱的应用之一,下图是某手机厂商数据库中的用户行为信息表中部分数据的截图
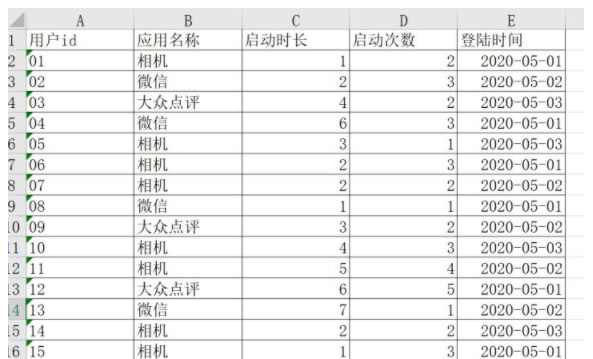
现在该手机厂商想要分析手机中的**应用(相机)的活跃情况,**需统计如下数据:
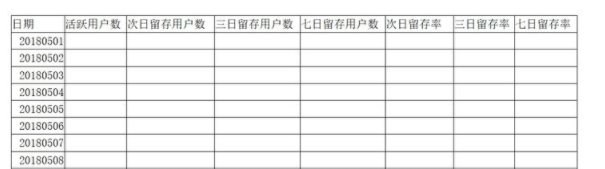
需要获得的数据的格式如下:
select d.a_t,count(distinct case when d.时间间隔=1 then d.用户id else nullend) as 次日留存数,
count(distinct case when 时间间隔=1 then d.用户idelse nullend) /count(distinct d.用户id) as 次日留存率,
count(distinct case when d.时间间隔=3 then d.用户id else nullend) as 3日留存数 ,
count(distinct case when 时间间隔=3 then d.用户idelse nullend) /count(distinct d.用户id) as 3日留存率,
count(distinct case when d.时间间隔=7 then d.用户id else nullend) as 7日留存数 ,
count(distinct case when 时间间隔=7 then d.用户idelse nullend) /count(distinct d.用户id) as 7日留存率from
(select *,timestampdiff(day,a_t,b_t) as 时间间隔
from (select a.`用户id`,a.登陆时间 as a_t ,b.登陆时间 as b_t
from 登录信息 as a
left join 登录信息 as b
on a.`用户id`=b.`用户id`
where a.应用名称= '相机' AND b.应用名称='相机') as c) as d
group by d.a_t;
(5)AB球队得分流水表,得到连续三次得分的队员名字 和每次赶超对手的球员名字(pdd)
在复盘时发现有类似原题,这是我在面试中遇到的最难的题
问题:两支篮球队进行了激烈的篮球比赛,比分交替上升。比赛结束后,你有一张两队得分分数的明细表,记录了球队team,球员号码number,球员姓名name, 得分分数score 以及得分时间scoretime(datetime)。现在球队要对比赛中表现突出的球员做出嘉奖,所以请你用sql统计出
1)连续三次(及以上)为球队得分的球员名单
2)比赛中帮助各自球队反超比分的球员姓名以及对应时间。
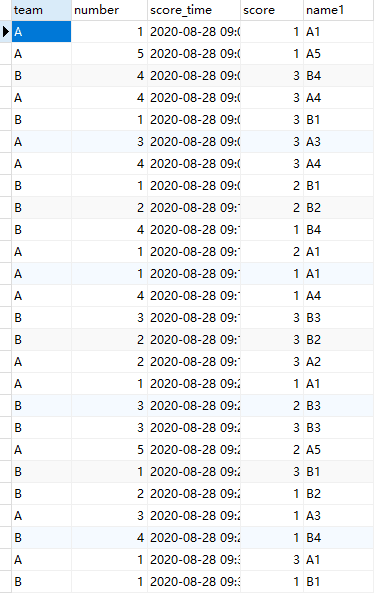
先建一个类似的表
CREATE TABLE basketball_game_score_detail(team VARCHAR(40) NOT NULL ,number VARCHAR(100) NOT NULL,score_time datetime NOT NULL,score int NOT NULL,name varchar(100) NOT NULL
);
insert into basketball_game_score_detail values('A',1,'2020/8/28 9:01:14',1,'A1');
insert into basketball_game_score_detail values('A',5,'2020/8/28 9:02:28',1,'A5');
insert into basketball_game_score_detail values('B',4,'2020/8/28 9:03:42',3,'B4');
insert into basketball_game_score_detail values('A',4,'2020/8/28 9:04:55',3,'A4');
insert into basketball_game_score_detail values('B',1,'2020/8/28 9:06:09',3,'B1');
insert into basketball_game_score_detail values('A',3,'2020/8/28 9:07:23',3,'A3');
insert into basketball_game_score_detail values('A',4,'2020/8/28 9:08:37',3,'A4');
insert into basketball_game_score_detail values('B',1,'2020/8/28 9:09:51',2,'B1');
insert into basketball_game_score_detail values('B',2,'2020/8/28 9:11:05',2,'B2');
insert into basketball_game_score_detail values('B',4,'2020/8/28 9:12:18',1,'B4');
insert into basketball_game_score_detail values('A',1,'2020/8/28 9:13:32',2,'A1');
insert into basketball_game_score_detail values('A',1,'2020/8/28 9:14:46',1,'A1');
insert into basketball_game_score_detail values('A',4,'2020/8/28 9:16:00',1,'A4');
insert into basketball_game_score_detail values('B',3,'2020/8/28 9:17:14',3,'B3');
insert into basketball_game_score_detail values('B',2,'2020/8/28 9:18:28',3,'B2');
insert into basketball_game_score_detail values('A',2,'2020/8/28 9:19:42',3,'A2');
insert into basketball_game_score_detail values('A',1,'2020/8/28 9:20:55',1,'A1');
insert into basketball_game_score_detail values('B',3,'2020/8/28 9:22:09',2,'B3');
insert into basketball_game_score_detail values('B',3,'2020/8/28 9:23:23',3,'B3');
insert into basketball_game_score_detail values('A',5,'2020/8/28 9:24:37',2,'A5');
insert into basketball_game_score_detail values('B',1,'2020/8/28 9:25:51',3,'B1');
insert into basketball_game_score_detail values('B',2,'2020/8/28 9:27:05',1,'B2');
insert into basketball_game_score_detail values('A',3,'2020/8/28 9:28:18',1,'A3');
insert into basketball_game_score_detail values('B',4,'2020/8/28 9:29:32',1,'B4');
insert into basketball_game_score_detail values('A',1,'2020/8/28 9:30:46',3,'A1');
insert into basketball_game_score_detail values('B',1,'2020/8/28 9:32:00',1,'B1');
insert into basketball_game_score_detail values('A',4,'2020/8/28 9:33:14',2,'A4');
insert into basketball_game_score_detail values('B',1,'2020/8/28 9:34:28',1,'B1');
insert into basketball_game_score_detail values('B',5,'2020/8/28 9:35:42',2,'B5');
insert into basketball_game_score_detail values('A',1,'2020/8/28 9:36:55',1,'A1');
insert into basketball_game_score_detail values('B',1,'2020/8/28 9:38:09',3,'B1');
insert into basketball_game_score_detail values('A',1,'2020/8/28 9:39:23',3,'A1');
insert into basketball_game_score_detail values('B',2,'2020/8/28 9:40:37',3,'B2');
insert into basketball_game_score_detail values('A',3,'2020/8/28 9:41:51',3,'A3');
insert into basketball_game_score_detail values('A',1,'2020/8/28 9:43:05',2,'A1');
insert into basketball_game_score_detail values('B',3,'2020/8/28 9:44:18',3,'B3');
insert into basketball_game_score_detail values('A',5,'2020/8/28 9:45:32',2,'A5');
insert into basketball_game_score_detail values('B',5,'2020/8/28 9:46:46',3,'B5');
这里我使用了lead和lag来取每个组的前几个值,这个和最大联系天数不太一样,但也可以用类似思路去解,但是使用lead和lag做起来更容易理解
select distinct a.name ,a.team from
(
select *,lead(name,1) over(partition by team order by score_time) as ld1
,lead(name,2) over(partition by team order by score_time) as ld2
,lag(name,1) over(partition by team order by score_time) as lg1
,lag(name,2) over(partition by team order by score_time) as lg2
from table
) a
where (a.name =a.ld1 and a.name =a.ld2)
or (a.name =a.ld1 and a.name =a.lg1)
or (a.name=a.lg1 and a.name=a.lg2)
第二小问面试时没完全做出来,说了下思路,现在想了想当时的思路还是有问题,而且这个题也并不难,核心还是记录每个时刻的累计得分表
SELECT TEAM,number,name,score_time,score,case when team='A' then score else 0 end as A_score
,case when team='B' then score else 0 end B_score
FROM basketball_game_score_detail
ORDER BY SCORE_time
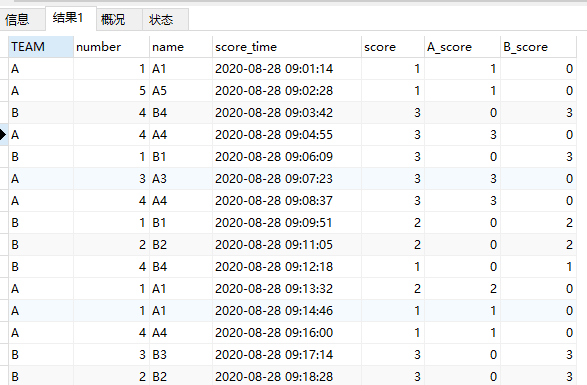
如下得到每个时刻的累计得分表
select team,number,name,score_time,A_score,b_score
,sum(A_score)over(order by score_time) as a_sum_score2
,sum(b_score)over(order by score_time) as b_sum_score2
from
(SELECT TEAM,number,name,score_time,score,case when team='A' then score else 0 end as A_score,case when team='B' then score else 0 end B_scoreFROM basketball_game_score_detailORDER BY SCORE_time
) as x
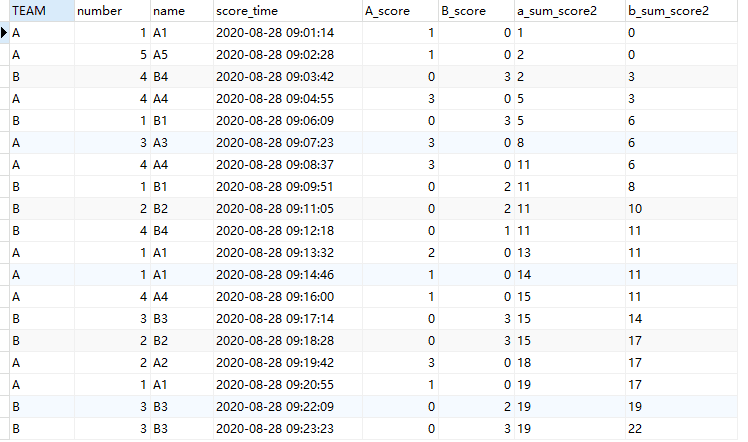
计算每个时刻的累计得分差,和上个时间的累计得分差,只要两个的符号相反就是反超时刻。感觉思路还是比较简洁的。
select *,score_gap*last_score_gap
from
(select *,a_sum_score2-b_sum_score2 as score_gap ,lag(a_sum_score2-b_sum_score2,1)over(order by score_time) as last_score_gapfrom (select team,number,name,score_time,A_score,b_score,sum(A_score)over(order by score_time) as a_sum_score2,sum(b_score)over(order by score_time) as b_sum_score2from (SELECT TEAM,number,name,score_time,score,case when team='A' then score else 0 end as A_score,case when team='B' then score else 0 end B_scoreFROM basketball_game_score_detailORDER BY SCORE_time) as x) as y
) as z
where z.score_gap*last_score_gap<=0
and a_sum_score2<>b_sum_score2
推荐文章
-
李宏毅《机器学习》国语课程(2022)来了
-
有人把吴恩达老师的机器学习和深度学习做成了中文版
-
上瘾了,最近又给公司撸了一个可视化大屏(附源码)
-
如此优雅,4款 Python 自动数据分析神器真香啊
-
梳理半月有余,精心准备了17张知识思维导图,这次要讲清统计学
-
年终汇总:20份可视化大屏模板,直接套用真香(文末附源码)
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群