1 介绍
使用Scikit-Learn模块在Python实现任何机器学习算法都比较简单,并且不需要了解所有细节。这里就对如何进行随机森林回归在算法上进行概述,在参数上进行详述。希望对你的工作有所帮助。
这里,将介绍如何在Python中构建和使用Random Forest回归,而不是仅仅显示代码,同时将尝试了解模型的工作原理。
1.1 随机森林概述
随机森林是一种基于集成学习的监督式机器学习算法。集成学习是一种学习类型,可以多次加入不同类型的算法或相同算法,以形成更强大的预测模型。随机森林结合了多个相同类型的算法,即多个决策的树木,故名“随机森林”。
1.2 理解决策树
决策树是随机森林的构建块,它本身就是个直观的模型。我们可以将决策树视为询问有关我们数据问题的流程图。这是一个可解释的模型,因为它决定了我们在现实生活中的做法:在最终得出决定之前,我们会询问有关数据的一系列问题。
随机森林是由许多决策树组成的整体模型。通过对每个决策树的预测平均来进行预测。就像森林是树木的集合一样,随机森林模型也是决策树模型的集合。这使随机森林成为一种强大的建模技术,它比单个决策树要强大得多。
随机森林中的每棵树都在对数据子集进行训练。其背后的基本思想是在确定最终输出时组合多个决策树,而不是依赖于各个决策树。每个决策树都有很高的方差,但是当我们将所有决策树并行组合在一起时,由于每个决策树都针对特定样本数据进行了完美的训练,因此结果方差很低,因此输出不依赖于一个决策树而是多个决策树木。对于回归问题,最终输出是所有决策树输出的平均值。
1.3 随机森林工作过程概述
- 从数据集中随机选择N个样本子集。
- 基于这N个样本子集构建决策树。
- 选择算法中所需树的棵数,然后重复步骤1和2。
对于回归问题,森林中的每棵树都将预测Y值(输出)。通过取森林中所有决策树预测值的平均值来计算最终值。
1.4 Bootstrapping&Bagging
Bootstrapping
Bootstrapping算法,指的就是利用有限的样本资料经由多次重复抽样。如:在原样本中有放回的抽样,抽取n次。每抽一次形成一个新的样本,重复操作,形成很多新样本。
随机森林就是采用在每个随机样本上训练决策树。尽管每棵树相对于一组特定的训练数据可能有很大的差异,但总体而言,整个森林的方差都很小。
Bagging
随机森林在不同的随机选择的样本子集上训练每个决策树,然后对预测取平均以进行整体预测。这个过程被称为Bagging。
2 随机森林优缺点
2.1 随机森林回归的优点
在机器学习领域,随机森林回归算法比其他常见且流行的算法更适合回归问题。
- 要素和标签之间存在非线性或复杂关系。
- 它对训练集中噪声不敏感,更利于得到一个稳健的模型。随机森林算法比单个决策树更稳健,因为它使用一组不相关的决策树。
- 避免产生过拟合的模型。
2.2 随机森林的缺点
- 随机森林的主要缺点在于其复杂性。由于需要将大量决策树连接在一起,因此它们需要更多的计算资源。
- 由于其复杂性,与其他同类算法相比,它们需要更多的时间进行训练。
2.3 随机森林的过拟合问题
欠拟合、合适与过拟合,如下图所示。当出现过拟合情况时候,对于训练数据模型表现良好,测试数据模型表现肯定较差。机器学习是比较容易出现过拟合的。对于随机森林的过拟合问题分为两派,会产生过拟合与不会过拟合。
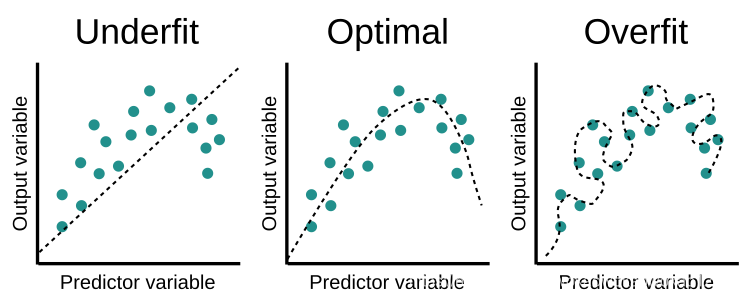
不会过拟合:
在Leo Breiman(随机森林算法的创建者)论文《Random Forests》中的表述:


会过拟合:
问题描述,一部分数据(数据的90%)作为训练样本,一部分(10%)作为测试样本,发现训练样本的R2一直在0.85,而测试样本R2都只有0.5几,高的也就0.6几。
对于这个问题,也很有可能是自变量与因变量之间本身关系就很低产生了过拟合假象。
3 使用随机森林回归实践
在本节中,我们将研究如何使用Scikit-Learn将随机森林用于解决回归问题。
3.1 问题描述
根据汽油税(美分),人均收入(美元),高速公路(以英里为单位)和人口所占比例来预测美国48个州的汽油消耗量(百万加仑)。
为了解决这个回归问题,采用Scikit-Learn 中的随机森林算法。
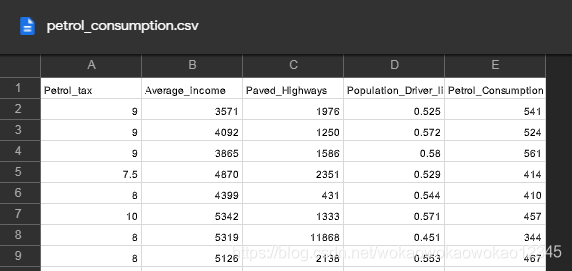
3.2 样本数据
例子数据集可在以下位置获得(需要KeXueShangWang才可以打开):
https://drive.google.com/file/d/1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_/view
3.3 代码
相关的解释说明都在代码中进行了注释
import pandas as pd
import numpy as np# 导入数据,路径中要么用\\或/或者在路径前加r
dataset = pd.read_csv(r'D:\Documents\test_py\petrol_consumption.csv')# 输出数据预览
print(dataset.head())# 准备训练数据
# 自变量:汽油税、人均收入、高速公路、人口所占比例
# 因变量:汽油消耗量
X = dataset.iloc[:, 0:4].values
y = dataset.iloc[:, 4].values# 将数据分为训练集和测试集
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=0)# 特征缩放,通常没必要
# 因为数据单位,自变量数值范围差距巨大,不缩放也没问题
from sklearn.preprocessing import StandardScalersc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)# 训练随机森林解决回归问题
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=200, random_state=0)
regressor.fit(X_train, y_train)
y_pred = regressor.predict(X_test)# 评估回归性能
from sklearn import metricsprint('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:',np.sqrt(metrics.mean_squared_error(y_test, y_pred)))输出结果
Petrol_tax Average_income Paved_Highways Population_Driver_licence(%) Petrol_Consumption
0 9.0 3571 1976 0.525 541
1 9.0 4092 1250 0.572 524
2 9.0 3865 1586 0.580 561
3 7.5 4870 2351 0.529 414
4 8.0 4399 431 0.544 410
Mean Absolute Error: 48.33899999999999
Mean Squared Error: 3494.2330150000003
Root Mean Squared Error: 59.112037818028234
4 Sklearn随机森林回归参数详解
要了解sklearn.ensemble.RandomForestRegressor每个参数的意义,我们需要从函数定义入手,具体介绍还得看官网介绍:
sklearn.ensemble.RandomForestRegressor(
n_estimators=100, *, # 树的棵树,默认是100
criterion='mse', # 默认“ mse”,衡量质量的功能,可选择“mae”。
max_depth=None, # 树的最大深度。
min_samples_split=2, # 拆分内部节点所需的最少样本数:
min_samples_leaf=1, # 在叶节点处需要的最小样本数。
min_weight_fraction_leaf=0.0, # 在所有叶节点处的权重总和中的最小加权分数。
max_features='auto', # 寻找最佳分割时要考虑的特征数量。
max_leaf_nodes=None, # 以最佳优先方式生长具有max_leaf_nodes的树。
min_impurity_decrease=0.0, # 如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split=None, # 提前停止树木生长的阈值。
bootstrap=True, # 建立树木时是否使用bootstrap抽样。 如果为False,则将整个数据集用于构建每棵决策树。
oob_score=False, # 是否使用out-of-bag样本估算未过滤的数据的R2。
n_jobs=None, # 并行运行的Job数目。
random_state=None, # 控制构建树时样本的随机抽样
verbose=0, # 在拟合和预测时控制详细程度。
warm_start=False, # 设置为True时,重复使用上一个解决方案,否则,只需拟合一个全新的森林。
ccp_alpha=0.0,
max_samples=None) # 如果bootstrap为True,则从X抽取以训练每个决策树。
5 随机森林可视化
5.1 代码
import sklearn.datasets as datasets
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.decomposition import PCA# 导入数据,路径中要么用\\或/或者在路径前加r
dataset = pd.read_csv(r'D:\Documents\test_py\petrol_consumption.csv')# 输出数据预览
print(dataset.head())# 准备训练数据
# 自变量:汽油税、人均收入、高速公路、人口所占比例
# 因变量:汽油消耗量
X = dataset.iloc[:, 0:4].values
y = dataset.iloc[:, 4].values# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=0)
regr = RandomForestRegressor()
# regr = RandomForestRegressor(random_state=100,
# bootstrap=True,
# max_depth=2,
# max_features=2,
# min_samples_leaf=3,
# min_samples_split=5,
# n_estimators=3)
pipe = Pipeline([('scaler', StandardScaler()), ('reduce_dim', PCA()),('regressor', regr)])
pipe.fit(X_train, y_train)
ypipe = pipe.predict(X_test)from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
import os# 执行一次
# os.environ['PATH'] = os.environ['PATH']+';'+r"D:\CLibrary\Graphviz2.44.1\bin\graphviz"
dot_data = StringIO()
export_graphviz(pipe.named_steps['regressor'].estimators_[0],out_file=dot_data)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('tree.png')
Image(graph.create_png())5.2 GraphViz’s executables not found报错解决方案
参考博文

5.3 InvocationException: GraphViz’s executables not found 解决方案
参考博文

5.4 随机森林可视化
X[0], X[1], X[2], X[3], X[4]…分别为对应的自变量。 从结构化可以看到mse逐渐减小。这里一共是12层树,实际工作中可能远大于这里的例子。

5.5 变量重要性
通过变量重要性评价,可以删除那些不重要的变量,并且性能不会受到影响。另外,如果我们使用不同的机器学习方法(例如支持向量机),则可以将随机森林特征重要性用作一种特征选择方法。
为了量化整个随机森林中所有变量对模型的贡献,我们可以查看变量的相对重要性。 Skicit-learn中返回的重要性表示包含特定变量可以提高预测。 重要性的实际计算超出了本文的范围,这里仅对模型输出重要性数值进行使用。
# Get numerical feature importances
importances = list(regr.feature_importances_)
# List of tuples with variable and importance
print(importances)# Saving feature names for later use
feature_list = list(dataset.columns)[0:4]feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)]
# Sort the feature importances by most important first
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True)
# Print out the feature and importances
# [print('Variable: {:20} Importance: {}'.format(*pair)) for pair in feature_importances];# Import matplotlib for plotting and use magic command for Jupyter Notebooksimport matplotlib.pyplot as plt
# Set the style
# plt.style.use('fivethirtyeight')
# list of x locations for plotting
x_values = list(range(len(importances)))
print(x_values)
# Make a bar chart
plt.bar(x_values, importances, orientation = 'vertical')
# Tick labels for x axis
plt.xticks(x_values, feature_list,rotation=6)
# Axis labels and title
plt.ylabel('Importance'); plt.xlabel('Variable'); plt.title('Variable Importances');
plt.show()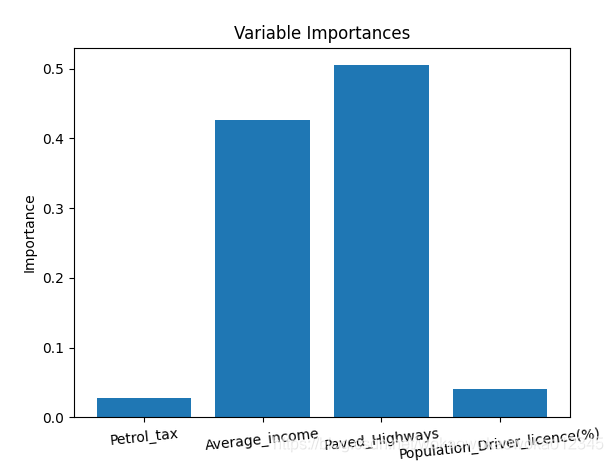
参考
https://stackabuse.com/random-forest-algorithm-with-python-and-scikit-learn/
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html
https://towardsdatascience.com/random-forest-in-python-24d0893d51c0
添加链接描述
![DS和[address]](https://img-blog.csdnimg.cn/20200202162712584.png)