工作中经常遇到需要取两个集合之间的交集、差集情况,但是普通的retainAll()和removeAll()无法满足数据量大的情况,由此就自己尝试运用其他的方法解决。注:如果数据量小的情况下,还是使用retainAll()和removeAll()方便
1.假使不存在重复数据,如果存在重复数据,也会被覆盖掉,实际情况中,重复数据也无意义。
2.取交集或者差集时存在主数据和从数据的关系,可提前判断一下那个集合数据量更多,来决定主从数据,或者经过两轮比较,或者经过两轮比较,获取两个结果集。下面例举中,list1为主数据,list2为从数据。
取交集
public static void main(String[] args) {//模拟数据List<Integer> list1 = new ArrayList<>();List<Integer> list2 = new ArrayList<>();for (int i = 1; i <= 1000000; i++) {list1.add(i);list2.add(1000000 - i);}//记录开始时间long startTime = System.currentTimeMillis();//最后结果集List<Integer> resultList = new ArrayList<>();//中间存储Map<String, Integer> map = new HashMap<>();list2.forEach(i2 -> {map.put(i2 + "", i2);});list1.forEach(i1 -> {Integer m = map.get(i1 + "");//如果不为空,则证明list1和list2都拥有该数据if (m != null) {resultList.add(i1);}});System.out.println("耗时:" + (System.currentTimeMillis() - startTime) + "ms");System.out.println(resultList.size());}
运行结果
取差集
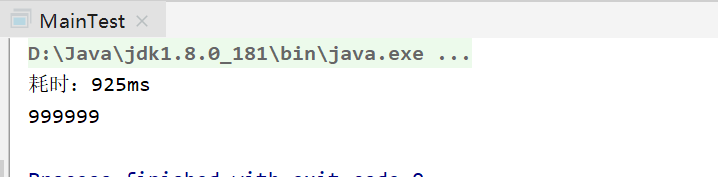
public static void main(String[] args) {//模拟数据List<Integer> list1 = new ArrayList<>();List<Integer> list2 = new ArrayList<>();for (int i = 1; i <= 1000000; i++) {list1.add(i);list2.add(1500000 - i);}//记录开始时间long startTime = System.currentTimeMillis();//最后结果集List<Integer> resultList = new ArrayList<>();//中间存储Map<String, Integer> map = new HashMap<>();list2.forEach(i2 -> {map.put(i2 + "", i2);});list1.forEach(i1 -> {Integer m = map.get(i1 + "");//如果为空,则证明list2中无该数据if (m == null) {resultList.add(i1);}});System.out.println("耗时:" + (System.currentTimeMillis() - startTime) + "ms");System.out.println(resultList.size());}
运行结果

总结
在双向一百万的数据情况下,使用retainAll()和removeAll()取交集和差集,都需要很长的时间,但是使用map来存储数据,后续通过循环来对比数据,速度就会有显著提升,此方法可以使用于任意数据结构,只要把中间map的键设置好就可以了。