最近看完了口碑大赞的国产科幻电影,感觉非常的不错,刷新了对未来科幻的认知啊。在大饱眼福的同时,也想着大家对这部电影都是怎么评价的呢?
打开豆瓣网,找到电影短评页面,该网页是分页类型的,我打算使用 requests 与 BeautifulSoup 爬取到文本文件中,然后通过 jieba 抽取关键字和生成词云进行可视化展示。
一、requests+BeautifulSoup爬取目标数据
需求分析:
- 目标地址分页展示,每页20条,通过start参数标记;经测试,当爬取到220条之后就需要登录,这里就使用游客身份爬取前220条。
- 先使用requests请求获取到html,再使用BeautifulSoup解析html的数据,最终封装成JSON格式返回。
代码实现:
<1>. 实现获取短评数据的主体方法,流程有获取html网页数据、将html网页数据保存到txt文件、解析html网页数据并以json格式保存等步骤,如下
def get_comment(html_url, html_path, txt_path, size, header):for i in range(size):param_start = i * 20url = html_url + str(param_start)print(f'url is {url}')text = requests.get(url, headers=header).text# 把html文档保存为.txt,便于查看saveHtml2Txt(text, i, html_path)# 解析响应数据,保存为json格式soup = bs(text, "html.parser")comment_list = soup.find_all("div", class_="comment-item")print(f'comment list is {len(comment_list)}')process_comment(soup, comment_list, txt_path)
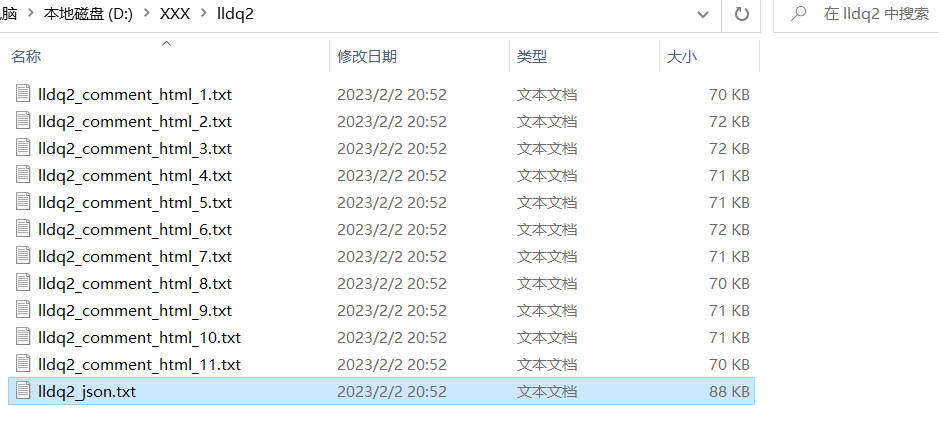
<2>. 将html网页数据保存到txt文件,如下
def saveHtml2Txt(text, i, html_path):# 没有该路径就自动创建目录h_path = Path(html_path)if not h_path.exists():h_path.mkdir(parents=True)# 将每个html写入txt文件保存with open(html_path + f'lldq2_comment_html_{i + 1}.txt', 'w', encoding='utf-8') as wf:wf.write(text)print(f'lldq2_comment_html_{i + 1}.txt, 写入成功!!!')<3>. 解析html网页数据,如下
def process_comment(soup, comment_list, txt_path):for j in range(0, len(comment_list)):# print(f'j is {j+1}')vote_count = soup.select(f'div #comments > div:nth-child({j + 1}) > div.comment > h3 > span.comment-vote > span')[0].get_text().strip()comment_time = soup.select(f'div #comments > div:nth-child({j + 1}) > div.comment > h3 > span.comment-info > span.comment-time')[0].get_text().strip()comment = soup.select(f'div #comments > div:nth-child({j + 1}) > div.comment > p > span')[0].get_text().strip()print(f"第{j + 1}条解析OK,投票数:{vote_count},时间:{comment_time}")# 封装成字典,并转json保存dicts = {"collection_time": time.strftime("%Y-%m-%d %H:%M", time.localtime()),"vote_count": int(vote_count),"comment_time": comment_time,"comment": comment}# 保存解析的数据,格式jsonsaveJson2Txt(dicts, txt_path)<4>. 以json格式保存数据,如下
def saveJson2Txt(dicts, txt_path):with open(txt_path, 'a', encoding='utf-8') as f:# 含有中文,ensure_ascii=Falsejson_data = json.dumps(dicts, ensure_ascii=False)# 每次写入都换行f.write(json_data + '\n')print(f'成功写入当前评论!')需要导入的模块有:
import json, requests, time
from pathlib import Path
from bs4 import BeautifulSoup as bs实现效果1:
 实现效果2:
实现效果2:
接下来,打算使用 jieba 进行分词,并生成词云,看下评论里讨论最多的关键字是什么,由于样本数量有限,只能代表前220条的热门评论哦。
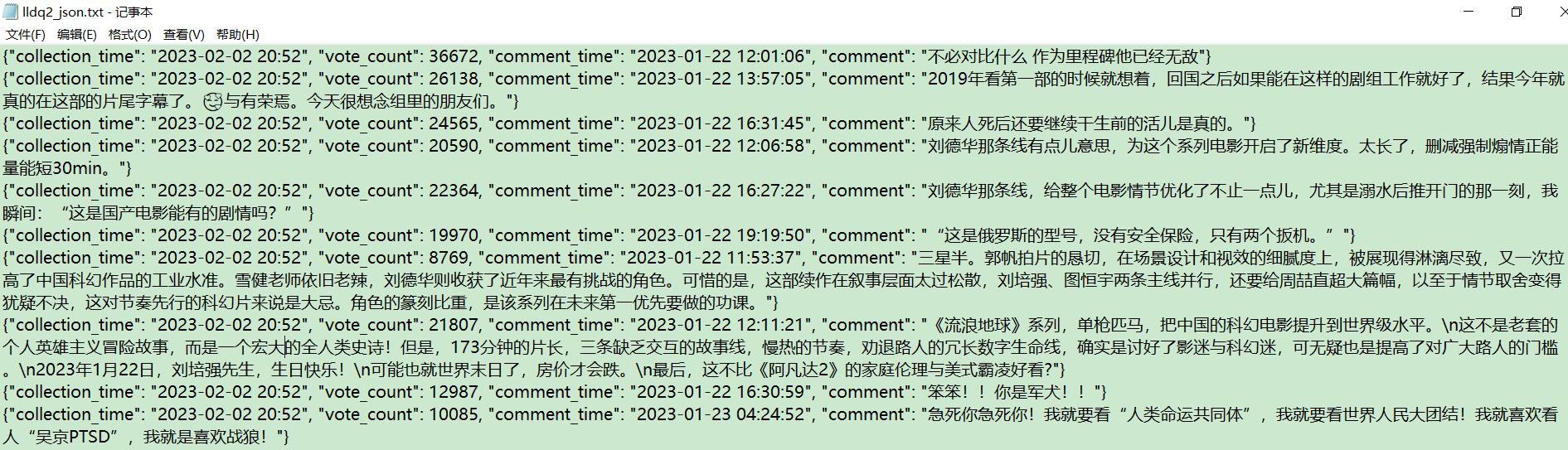
我目的是获取评论内容,而封装成 JSON 格式不利于进行关键词抽取。因此,需要进一步处理,把评论内容按行写入文本文件。写个转换方法,如下:
def processJson2Txt(json_path, save_txt_path):comment_list = []with open(json_path, mode='r', encoding='utf-8') as f:# 读取一行json数据context = f.read()comment_list = list(context.split("\n"))print(comment_list)for i in comment_list:if i != "":comment_dict = json.loads(i)print(comment_dict)with open(save_txt_path, 'a', encoding='utf-8') as fa:fa.write(comment_dict["comment"] + "\n")处理之后,效果如下:

二、使用jieba抽取关键字和生成词云
在之前的 jieba 博文里,介绍过两种抽取关键词的方式,这里使用基于 TextRank 算法的关键词抽取。
实现代码,如下:
def process_jieba(path):with open(path, mode='r', encoding='utf-8') as f:context = f.read()# 关键词抽取rank = analyse.textrank(context, topK=100)print(f'top100:: {rank}')# 构造词云对象,并调节显示词云的参数wc_text = ' '.join(rank)wc_Obj = wc.WordCloud(font_path=r'.\simhei.ttf',background_color='white',width=1000,height=900,).generate(wc_text)# 可视化显示plt.imshow(wc_Obj, interpolation='bilinear')plt.axis('off')plt.show()需要导入的模块:
import jieba.analyse as analyse
import wordcloud as wc
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt生成词云的效果:
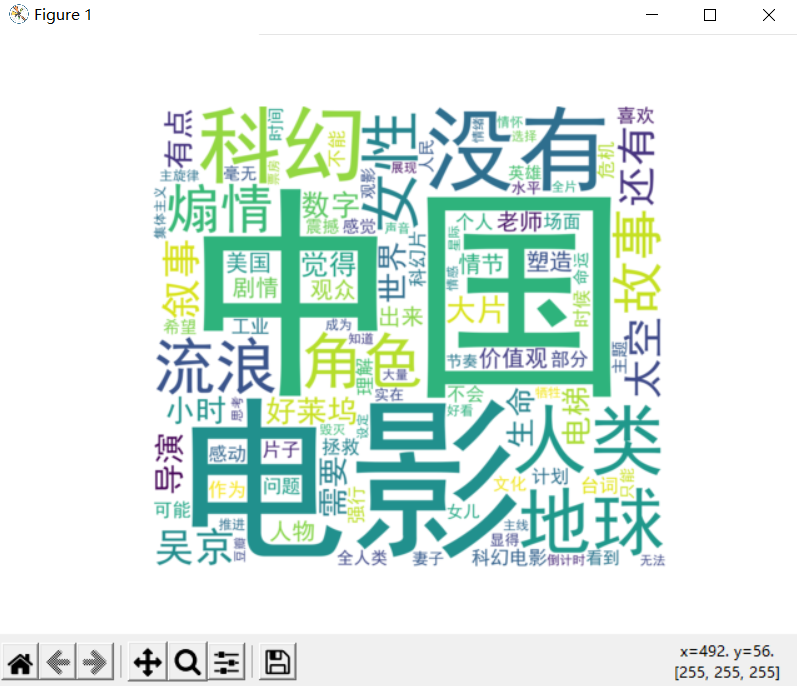
嗯~~,通过词云展示的效果还不错!当然,如果样本评论数据越多,展示的结果就会越客观和准确。