title: 神箭手云爬虫
categories:
- 神箭手
tags: - 爬虫
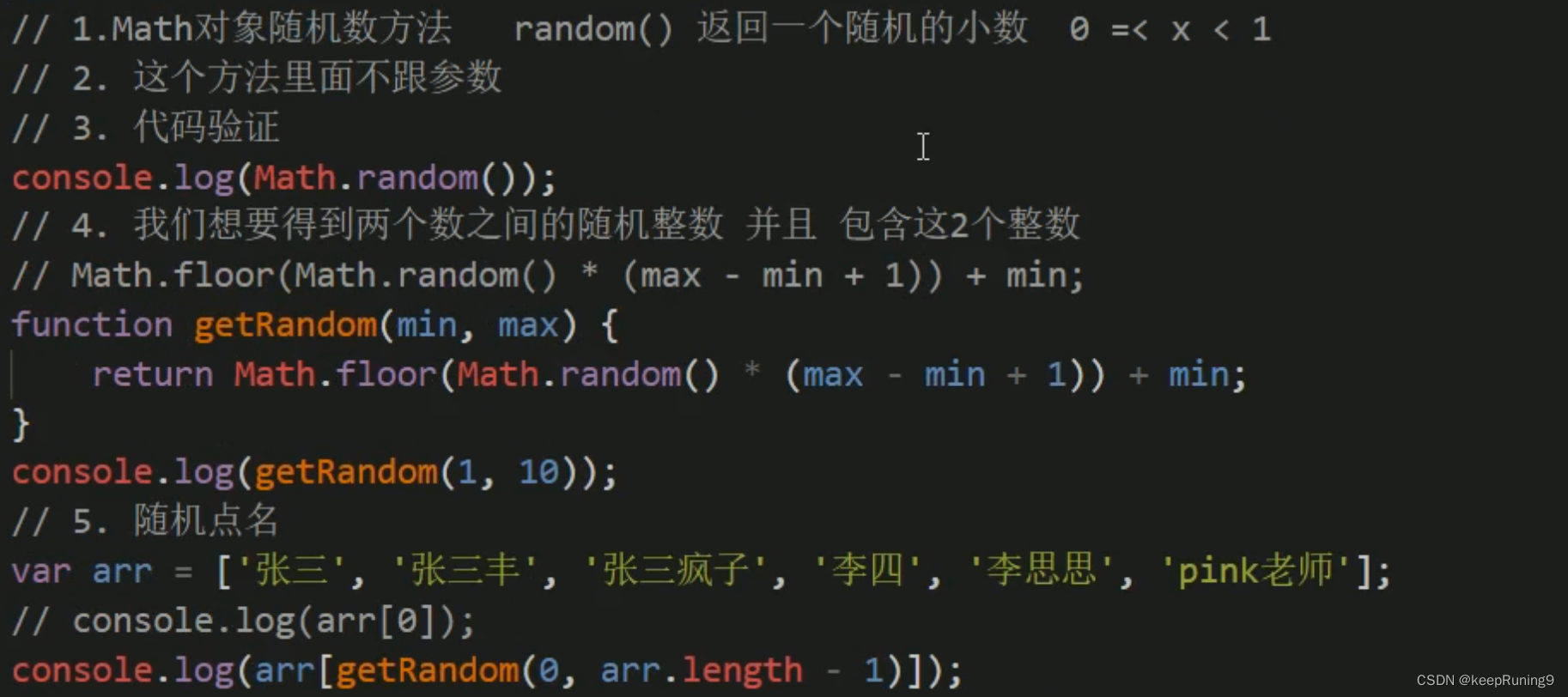
分为: 入口页,帮助页,内容页
入口页: scanUrl 爬虫网页的入口
帮助页:helperurl 一帮包含大量的内容页(列表),多数情况下事业个内容列表,也叫列表页
contentUrl队列:此队列中存放内容页类型的链接,自动链接发现以及site.addUrl的时候,通过正则表达式来判断链接类型,如果是内容页,则将会加到此链接中
普通队列:一般存放的都是帮助页类型的链接,自动链接发现以及site.addUrl 的时候,通过正则表达式来判断链接类型,如果不是内容页,将会加到此队列中
失败队列:一种特殊的队列,用来存放处理失败的链接。
链接调度
一次调度一个链接:默认情况下
contentUrl队列>普通队列>scanUrl队列
当configs.entriesFirst为true时,调度优先级为:
scanUrl队列>contentUrl队列>普通队列
在链接调度过程中,如果遇到了处理失败的情况: 首先会触发链接的重试(此链接会被重新加载到队列中),当重试次数(入口页:5次;帮助页:3次;内容页2次)仍然失败时,此链接就会被放到失败链接,当其他所有队列都为空时,失败队列里面的链接再重试一次,这些链接重试完成后,爬虫结束。
链接去重
网站之中链接存在循环,爬虫在爬去的过程中,如果不做控制,很容易陷入死循环。
比较好的方式就是对已经处理过的链接做标记,进行去重处理,(因为大部分处理过的链接不需要再处理一次,另一方面避免爬虫进入死循环)
对于GET类型的请求:平台使用链接本身去重,但是!!!平台不会对#做处理,
www.baidu.com/ 和 www.baidu.com/# 是两个不同的链接
对于POST请求,使用链接+参数的方式去重,也就是说对于同一链接,如果post的参数不一样,平台会认为是两个不同的链接
HTTP的header不会作为去重的依据
爬虫的生命周期

链接生命周期

configs对象
configs属性:
domains String 数组 不可为空
定义爬虫爬去哪些域名下的网页,链接发现的时候会检查链接的域名,如果不是这些域名下的链接,则会被忽略。
scanUrl String 数组
爬虫入口的链接,这是给爬虫添加入口的简单方式,这种方式添加的都是GET方式的请求。
不设置此属性,在initCrawl回调函数中调用site.addScanUrl,也可以达到添加入口页链接的目的。
以下情况只能在initCrawl回调函数中调用site.addScanUrl才能实现:
1.如果需要添加POST请求的入口页链接,只能通过site.addScanUrl来添加。
2.scanUrls数组长度的限制是1000个,超过1000个的部分将会被忽略;这种情况需要把添加入口链接的工作放到initCrawl回调函数中来做。
contentUrlRegexes String 数组或正则数组
定义内容页的链接正则,爬虫会根据这些正则来判断一个链接是否是内容页链接。
可以使字符串形式的正则,也可以是javaScript的正则,
//写法一:js原生正则(建议使用这种写法)
[/http:\/\/club2011\.auto\.163\.com\/post\/\d+\.html.*/]
//写法二:正则的字符串形式
["http://club2011\\.auto\\.163\\.com/post/\\d+\\.html.*"]
//写法三:通过字符串形式new一个js正则对象
[new RegExp("http://club2011\\.auto\\.163\\.com/post/\\d+\\.html.*")]
1.正则可以写多个,一个链接只要能匹配到其中的任意一个正则,该链接就会被认为是内容链接
2.不设置或设置为空数组,则所有的链接都是内容页链接。
helperUrlRegexes String数组或正则数组
定义帮助页的链接正则,爬虫会根据这些正则来判断一个链接是否是帮助页链接。
属性同内容页正则属性相同;
fields filed对象或数组 不可为空
定义爬取结构的数据字段,一个field定义出一个字段。
interval 整数
两个链接之间的处理间隔,单位是毫秒,默认值是1000,既1秒。可设置的最小值是1000.
一般保持默认值即可,如果反扒严重,可适当加大此值。
timeout 整数
每个请求的默认超时时间。单位是毫秒,默认值是5000,即5秒。
一般保持默认值即可,如果目标网站比较卡,经常超时,可以适当加大此值,如果设置过小,会导致所有的请求都超时。
注意:!1.这是全局超时时间,对于没有特殊指定超时时间的请求,超时时间都是这个值。
2.对于开启自动Js渲染的页面,在渲染过程中会自动发出很多其他js,css等的请求,这些请求的超时时间都是这个值((既这个值代表了超时的所有的时长 ))
enableJS 布尔类型
是否默认开启自动Js渲染。默认值是false。
这是一个全局设置,在处理具体的请求时,如果该请求有设置options.enableJS,则此值被覆盖。
var configs = {enableJS: false
};
configs.initCrawl = function(site) {site.addUrl("http://www.baidu.com");//该请求不会自动JS渲染site.addUrl("http://tieba.baidu.com", {enableJS: true});//该请求将会自动JS渲染site.requestUrl("http://music.baidu.com");//该请求不会自动JS渲染site.requestUrl("http://index.baidu.com", {enableJS: true});//该请求将会自动JS渲染
};
var configs = {enableJS: true
};
configs.initCrawl = function(site) {site.addUrl("http://www.baidu.com", {enableJS: false});//该请求不会自动JS渲染site.addUrl("http://tieba.baidu.com");//该请求将会自动JS渲染site.requestUrl("http://music.baidu.com", {enableJS: false});//该请求不会自动JS渲染site.requestUrl("http://index.baidu.com");//该请求将会自动JS渲染
};
JsEngine 枚举类型
使用哪种JS引擎来渲染页面。默认值为JSEngine.PhantomJS
- JSEngine.PhantomJs 使用phantomjs作为渲染引擎
- JSEngine.HtmlUnit 使用HtmlUnit作为渲染引擎
注:!
1.HtmlUnit目前兼容性相对差一些2.phantomjs单个网页最长渲染2分钟
entriesFirst 布尔类型是否优先处理待爬队列中的scanUrl队列,默认值是false
userAgent 枚举类型爬虫在发请求时使用的UserAgent类型。默认值为userAgent.Computer
UserAgent.Computer 使用电脑浏览器的UserAgent
UserAgent.Android 使用Android手机的UserAgent
UserAgent.iOS 使用苹果手机的UserAgent
UserAgent.Mobile 使用手机的UserAgent
UserAgent.Empty 不使用UserAgent
acceptHttpStatus 整数数组
添加下载网页时可以接受的HTTP返回码。默认接收的返回码包括200、201、202、203、204、205、206、207、208、226、301、302,通过此属性添加可以接受的返回码。
autoFindUrls 布尔类型
是否自动发现链接。默认值为true。此值实际上只影响onProcessScanPage,onPrcessHelperPage,onProcessContentPage这三个回调函数的默认返回值,最终是否会自动发现链接,还是由着三个回调函数的返回值决定的
field对象
name String 类型 不可为空
注意:!
1.名字中不能包含英文句点,既.。
2.同意层级名字不能重复。
3.为了更好的兼容性(尤其是数据库发布,名字建议不要使用中文,命名尽量符合变量名(标识符)的命名规则)
4.此值讲作为抽取项的标识,如果中途做了修改,将导致之前的数据无法读出该字段。
alias String 类型
抽取项的别名:一般起中文别名,方便数据查看,只影响网页的显示,课随意修改selectorType 枚举类型抽取规则的类型,默认值是selectorType.XPathSelectorType.XPath 一般针对html网页或xml
SelectorType.JsonPath 针对json数据
SelectorType.Regex 可以针对一切文本
selector String 类型
抽取规则
注意:
如果selector为空或者未设置,则抽取的值为null,在进行required的判定之前,仍会进行afterExtractField回调。
required 布尔类型
标识当前抽取项的值是否必须(不能为空),默认是false,可以为空
抽取过程中,如果某个不能为控制的抽取项,抽取出来的结果是空值,则当前网页的数据抽取会立即结束,抽取结果会被丢弃
注意:!
1.抽取规则可以抽取多条,但是repeated是false,最终的值是抽取结果里面的第一个。
2.抽取队则只抽取一条,但是repeated是true,那么抽取结果还是数组,数组值包含一个元素。
children field对象数组
抽取项的子抽取项。
field支持子项,可以设置多层级,方便数据以本身的层级方式存储,而不是全部展开到第一层级。
注意:!
第一层field默认从当前网页内容中抽取,而子项默认从父项的内容中抽取。
primaryKey 布尔类型
当前抽取项是否作为整条数据的主键组成部分,默认是false。