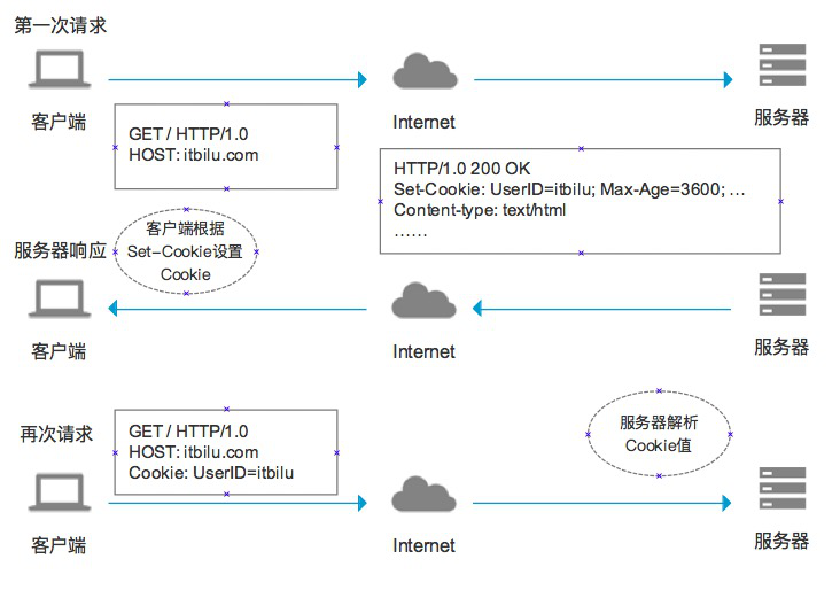
一、安装textlive
1. 首先下载安装包:textlive
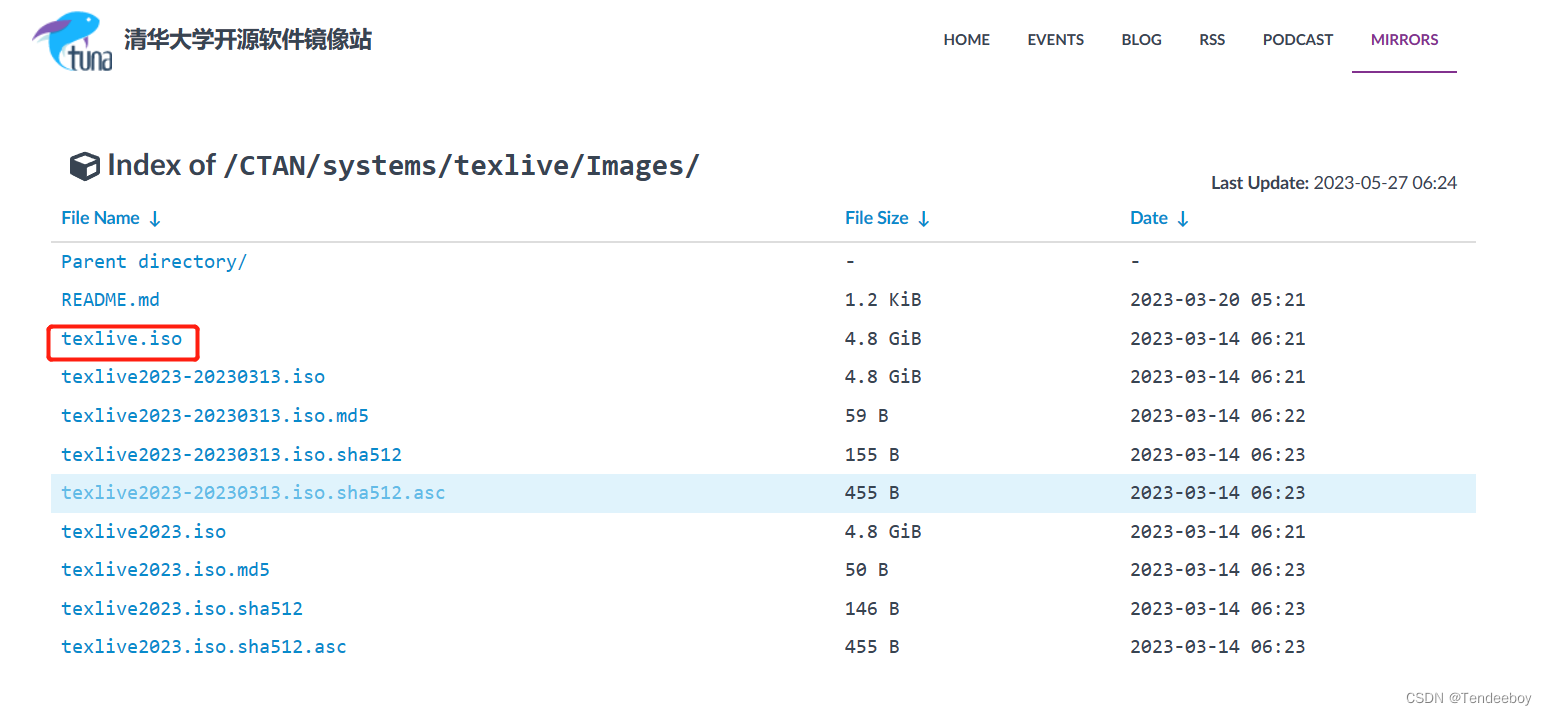
2. 下载完成后,解压ios文件。并以管理员的身份运行该文件。
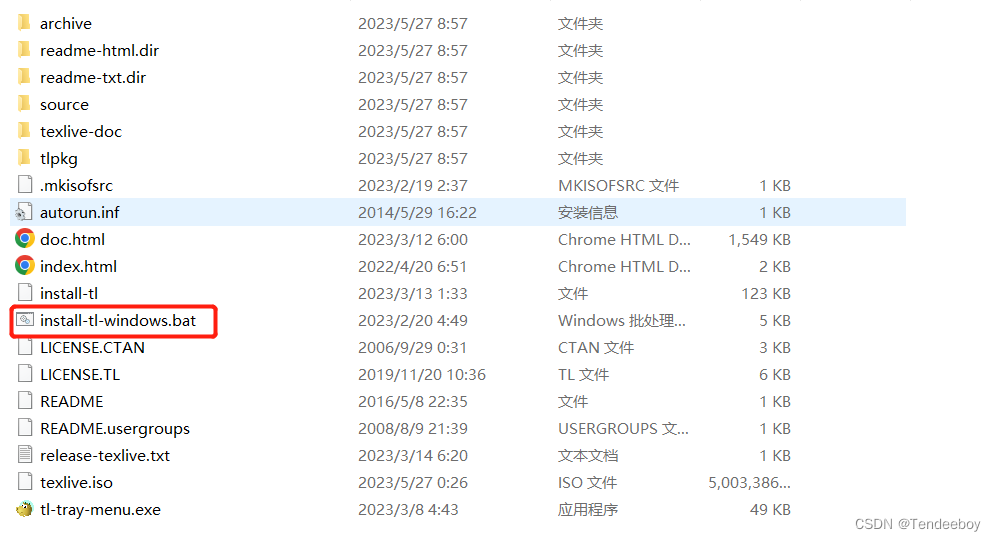
3. 设置安装路径,第二步选择语言,一般是中文和英文。
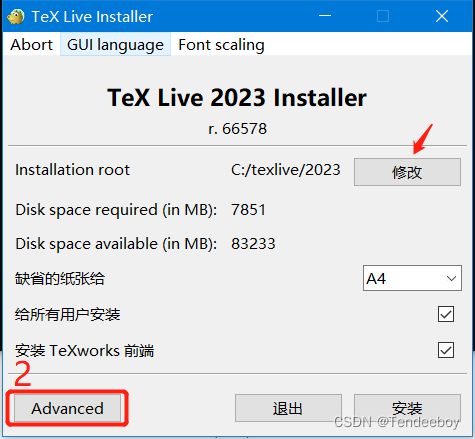

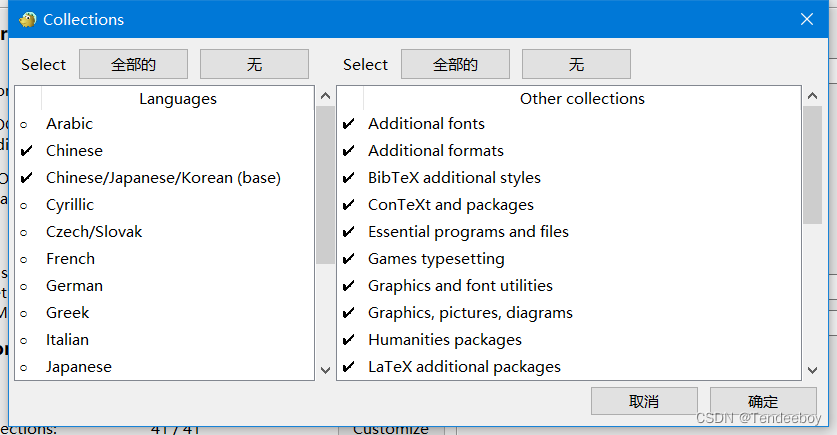
4. 确定好后点击安装就行,一般需要30分钟以上。
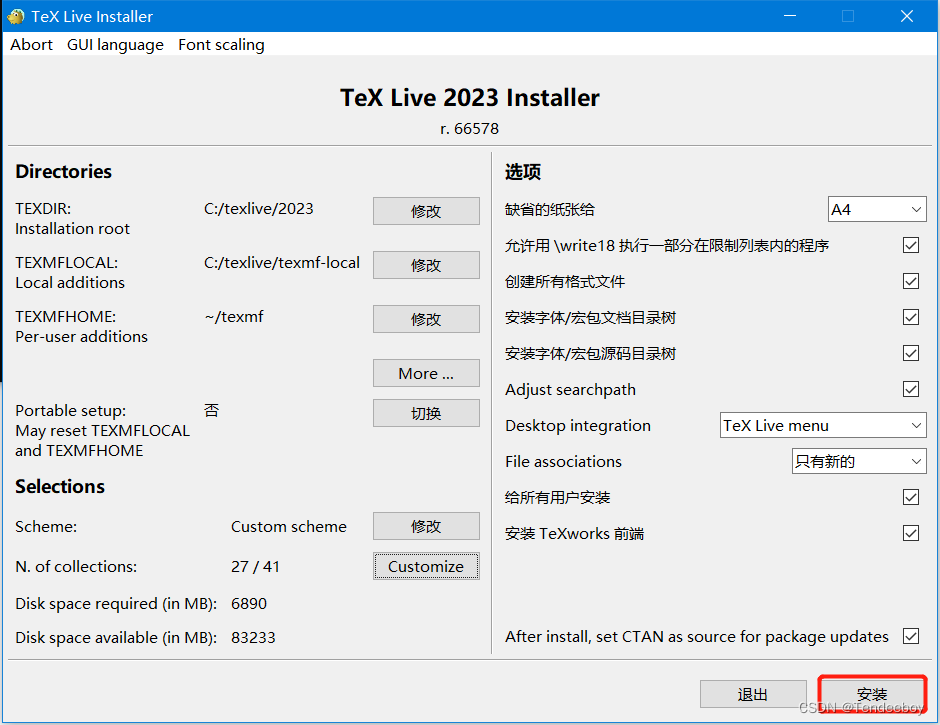
二、配置环境变量
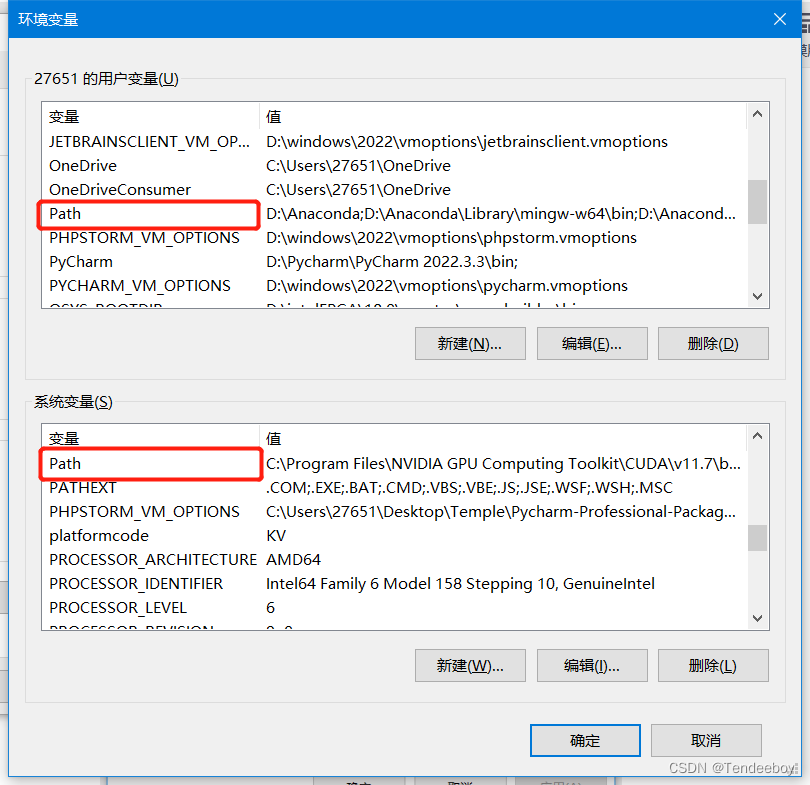
找到自己安装textlive的安装路径,我的是D:\textlive\texlive\2023\bin\windows。将其加入用户变量和系统变量的PATH中。
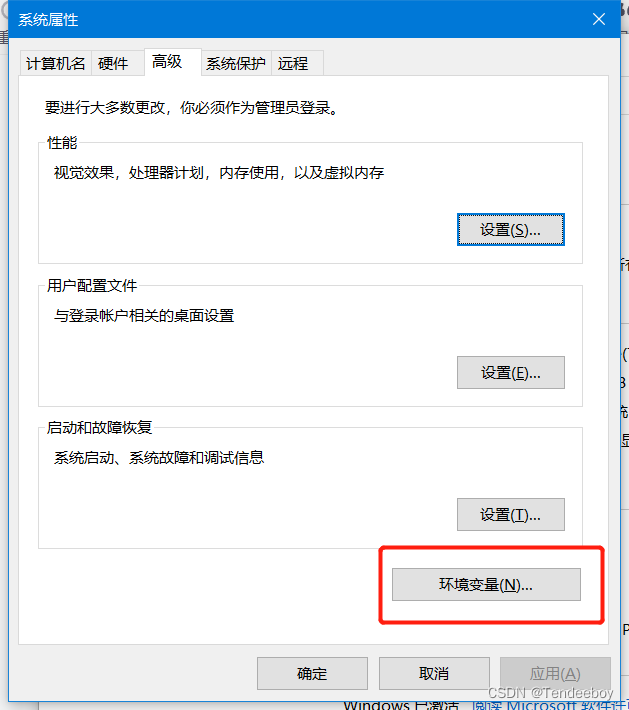
添加变量的方法为右击此电脑点击属性,再点击高级系统设置,点击环境变量。找到两个PATH,将路径复制粘贴即可。

然后win+R,进入cmd进行测试,输入测试命令,如果如下即安装成功。
latex -v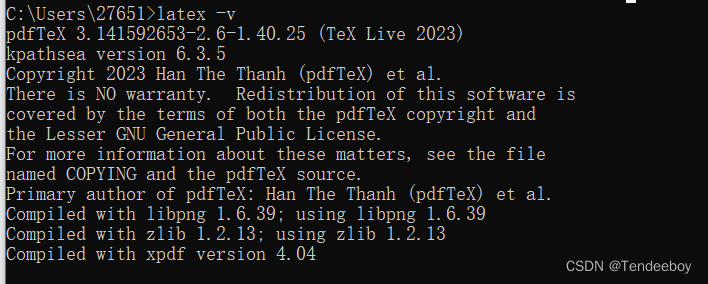
至此,texlive就安装好了。
三、TexStudio的安装
1. 首先下载安装包:TexStudio
这个网页需要梯子才能很进去,如果需要安装包的可以从百度云下载:
链接:https://pan.baidu.com/s/1E16AFZ9bO_CA6z4HpJyT3Q
提取码:1nmf
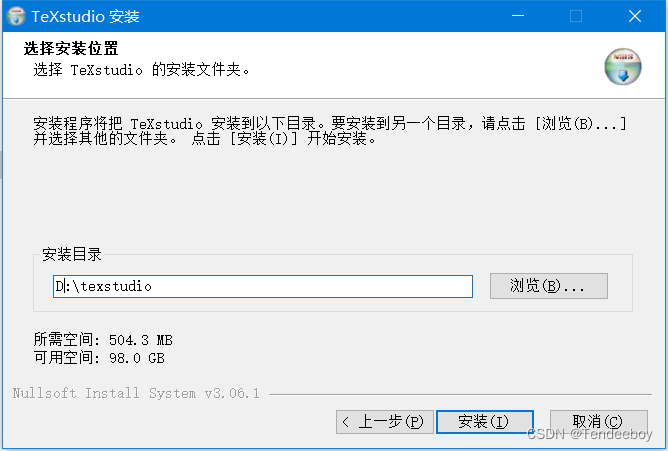
2. 点击安装,修改安装路径
3. 安装完成以后,运行TexStudio并进行相关的配置

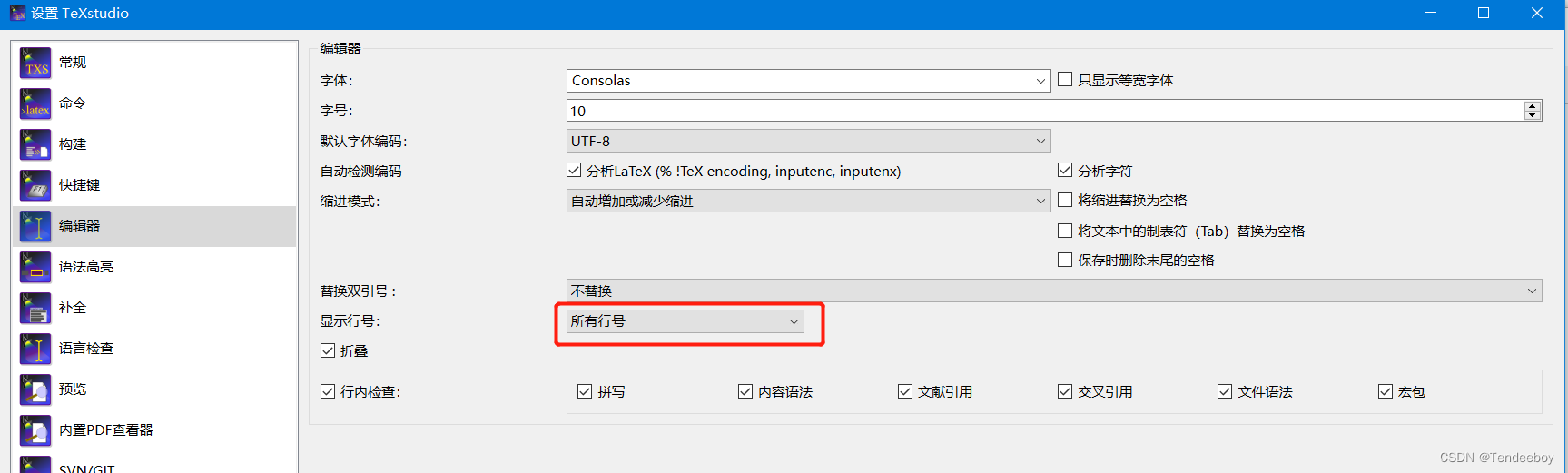
如果撰写英文论文,则默认编译器为PdfLaTex,中文论文,则为XeLaTex。

完结!!!有问题欢迎留言。