DeepWalk算法报告
Deepwalk是网络表示学习的经典算法之一,是用来学习网络中顶点的向量表示(学习学习图的结构特征即属性,并且属性个数为向量的维数)。
该算法通过截断随机游走学习出一个网络的社会表示,输入是一张图或者网络,输出为网络中顶点的向量表示。
本文的主要贡献为:
1.深度游走可以学习短随机有洞中存在的结构规律。
2.在标签稀疏性存在情况下,显著提高了分类性能。
3.通过使用并行实现构建网络规模的图的表示来演示我们算法的可伸缩性。
本文处理网络节点的表示利用了word2vec中词嵌入的思想。该思想的基本处理元素就是单词,对应网络节点的表示即网络节点。而词嵌入就是对一个句子中的单词序列进行分析,而这个序列就是随机游走所产生的。
所谓的随机游走,就是在网络上不断重复地随机选择游走路径,最终形成一条贯穿网络的路径。从某个特定的端点开始,游走的每一步都从与当前节点相连的边中随机选择一条,沿着选定的边移动到下一个顶点,不断重复这个过程。
整个DeepWalk算法包含俩个部分,一部分是随机游走的生成,另一部分是参数的更新
算法为:
 算法的输入:
算法的输入:
图G(V,E)其中V是顶点集,E是边集合。w为窗口大小,d是嵌入的维度大小。γ是在每个顶点开始随机游动的次数。t是随机游走的长度,即所生成的序列的最大长度。
算法的输出即是网络中顶点的向量表示
算法解析:
第1步是初始化顶点嵌入表示。第2步是构建Hierarchical Softmax即哈夫曼树,第3步开始是对每个节点做γ次随机游走,在循环中,第4步是打乱网络顶点集合中的节点,第5,6步是以每个节点为根节点生成长度为t的随机游走,该函数在后面代码解析中有会提到,第7步是将生成的随机游走序列用skip-gram模型中利用梯度的方法来对参数进行更新。其中参数更新的细节就是算法2,如下图。
‘’
算法2主要是对参数的更新,即对于每个参数进行求导得出梯度,再根据梯度进行更新参数,即所谓的梯度下降。
对于代码的分析:
__main__.py分析

这是运行时候的命令行参数,

其中format允许三种类型输入(adjlist,edgelist,mat),默认是adjlist。

如果数据量小,则直接调用build_deep_corpus,从每个节点开始进行多次随机游走。
num_path:设置了从一个节点开始的次数
path_length:设置了一个随机游走的长度
alpha:以概率1-alpha从当前节点继续走下去,或者以alpha的概率停止。
然后开始训练模型,将随机游走得到的walks放入word2vec模型中进行训练,从而得到对应节点的嵌入。

如果内存不够放随机游走的结果,则该路径会被保存到output.walks.x中
其实和之前的操作一样,也是在调用graph的randwalk,只不过加入了并行化代码和写到磁盘的程序。
Graph.py
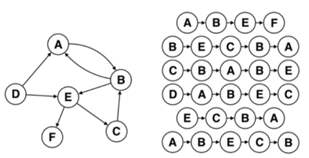
 在graph类中,该函数是初始化函数,构建2出一个字典来当图,其例子就是如下图所示:
在graph类中,该函数是初始化函数,构建2出一个字典来当图,其例子就是如下图所示:


该俩个函数检查生成的随机游走是否为自循环并且删除。

该函数是创建截断的随机游走,其中path_length代表游走的长度Alpha代表重启的概率
Start代表随机游走的开始节点。
 该函数对一个图生成一个语料库,即对于图G生成每个节点开始的多次的随机游走列表,
该函数对一个图生成一个语料库,即对于图G生成每个节点开始的多次的随机游走列表,

该函数也是生成语料库函数,但是不一样的是该函数采用yield函数进行迭代生成,是用于内存不足以保存路径的情况。
该类后面的函数主要作用就是将列表分成大小均匀的块。
Walks.py

上面俩个函数是计算词频的函数。
其中count_words的参数f中每行都是一个随机游走walk,函数最终返回这个file中每个单词出现的次数。
Count_textfiles使用了多线程的方法,也是返回每个单词出现的次数
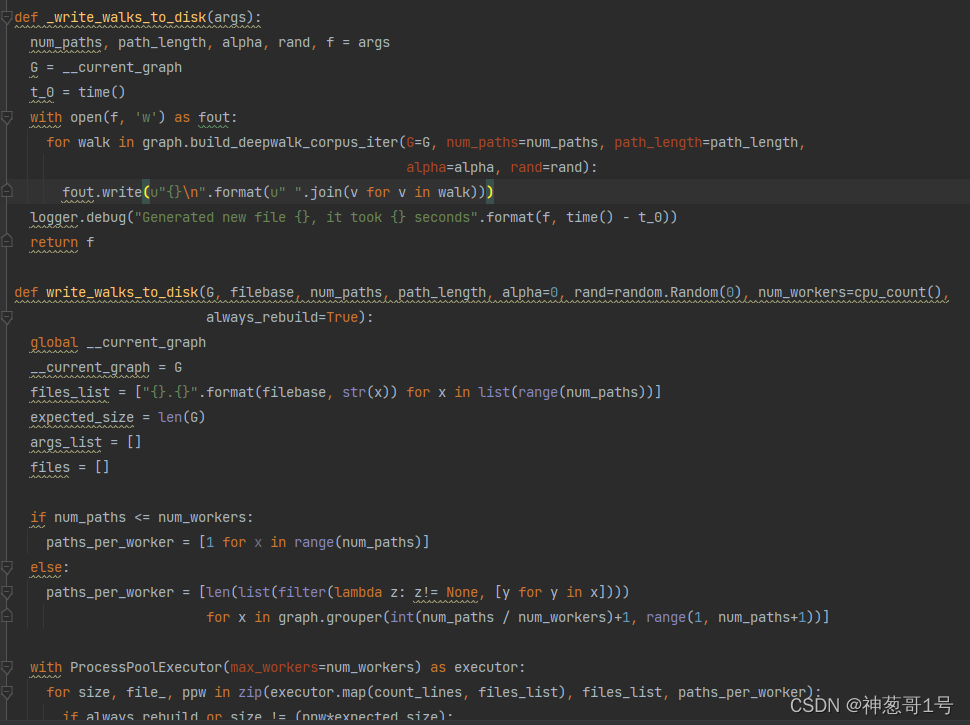
上面俩个函数是将walks写入文件,一个是直接写入,另一个是采用多线程方式。
Grouper函数的大致含义
grouper(3, 'abcdefg', 'x') --> ('a','b','c'), ('d','e','f'), ('g','x','x')
第一个参数是整数int,第二个参数是可迭代对象,例如range(1,7+1) (返回1,2,3,4,5,6,7的迭代对象)如果第三个参数不写,则default为None,这样
grouper(3, range(1,7+1))-->(1,2,3),(4,5,6),(7,None,None)
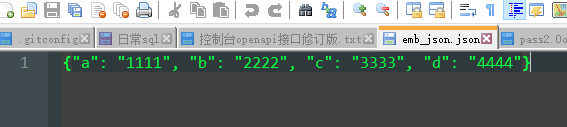
图的数据:
邻接矩阵为:

运行结果为:

2.总结:
Deepwalk算法我觉得是最经典的图嵌入算法之一。它采用了word2vec的方法思想,通过将一组组随机截断游走所生成的顶点序列当做一个个句子,然后去用word2vec进行训练,即用图中节点与节点的共现关系来学习节点的向量表示。
总的来说,这篇论文我认为是network embedding的开山之作,通过将NLP中word2vec的词向量的思想借鉴过来,来实现社交网络中的节点表示,因此提供了一种新的思路。因为社交网络中的节点分布太过于稀疏,所以deepwalk算法非常适用于标签稀疏的情况。其中随机截断游走的思想就是一种可重复访问已访问节点的深度优先遍历算法:
给定当前访问起始节点,从该起始节点中的所有邻居节点中随机采样作为下一个访问节点,并且有一定的概率返回原节点,重复此过程,直到序列长度等于给定的长度。在分析代码的过程中,依旧有些函数没怎么看懂,如多线程运行、评估那一块,但是关键的函数,包括生成随机截断游走、运用word2vec模型进行训练等这些已经领会
个人的看法:
算法优点:
1、在信息较少的稀疏网络表现优越
2、在线学习:DeepWalk是可扩展的
3、容易实现并行性。几个随机游走者(不同的线程,进程或机器)可以同时探索同一网络的不同部分。
4、适应性。当图变化后,不需要全局重新计算,可以迭代地更新学习模型。
算法缺点:
我觉得deepwalk只适用于无向图即无权边,因为它是概率性地选择自己的邻居顶点进行访问,而没有考虑到边的权重大小,但是在社交网络中边的权重是非常重要的。就比如说在一个学校的社交网络中,可能一个班级的同学他们的节点是相邻的,但是同寝室的他们的关系会更密切一点,也就是边的权重会更大一点,而deepwalk没有考虑到这些,这是我的看法。
DeepWalk算法报告
Deepwalk是网络表示学习的经典算法之一,是用来学习网络中顶点的向量表示(学习学习图的结构特征即属性,并且属性个数为向量的维数)。
该算法通过截断随机游走学习出一个网络的社会表示,输入是一张图或者网络,输出为网络中顶点的向量表示。
本文的主要贡献为:
1.深度游走可以学习短随机有洞中存在的结构规律。
2.在标签稀疏性存在情况下,显著提高了分类性能。
3.通过使用并行实现构建网络规模的图的表示来演示我们算法的可伸缩性。
本文处理网络节点的表示利用了word2vec中词嵌入的思想。该思想的基本处理元素就是单词,对应网络节点的表示即网络节点。而词嵌入就是对一个句子中的单词序列进行分析,而这个序列就是随机游走所产生的。
所谓的随机游走,就是在网络上不断重复地随机选择游走路径,最终形成一条贯穿网络的路径。从某个特定的端点开始,游走的每一步都从与当前节点相连的边中随机选择一条,沿着选定的边移动到下一个顶点,不断重复这个过程。
整个DeepWalk算法包含俩个部分,一部分是随机游走的生成,另一部分是参数的更新
算法为:
 算法的输入:
算法的输入:
图G(V,E)其中V是顶点集,E是边集合。w为窗口大小,d是嵌入的维度大小。γ是在每个顶点开始随机游动的次数。t是随机游走的长度,即所生成的序列的最大长度。
算法的输出即是网络中顶点的向量表示
算法解析:
第1步是初始化顶点嵌入表示。第2步是构建Hierarchical Softmax即哈夫曼树,第3步开始是对每个节点做γ次随机游走,在循环中,第4步是打乱网络顶点集合中的节点,第5,6步是以每个节点为根节点生成长度为t的随机游走,该函数在后面代码解析中有会提到,第7步是将生成的随机游走序列用skip-gram模型中利用梯度的方法来对参数进行更新。其中参数更新的细节就是算法2,如下图。
‘’
算法2主要是对参数的更新,即对于每个参数进行求导得出梯度,再根据梯度进行更新参数,即所谓的梯度下降。
对于代码的分析:
__main__.py分析

这是运行时候的命令行参数,

其中format允许三种类型输入(adjlist,edgelist,mat),默认是adjlist。

如果数据量小,则直接调用build_deep_corpus,从每个节点开始进行多次随机游走。
num_path:设置了从一个节点开始的次数
path_length:设置了一个随机游走的长度
alpha:以概率1-alpha从当前节点继续走下去,或者以alpha的概率停止。
然后开始训练模型,将随机游走得到的walks放入word2vec模型中进行训练,从而得到对应节点的嵌入。

如果内存不够放随机游走的结果,则该路径会被保存到output.walks.x中
其实和之前的操作一样,也是在调用graph的randwalk,只不过加入了并行化代码和写到磁盘的程序。
Graph.py
 在graph类中,该函数是初始化函数,构建2出一个字典来当图,其例子就是如下图所示:
在graph类中,该函数是初始化函数,构建2出一个字典来当图,其例子就是如下图所示:


该俩个函数检查生成的随机游走是否为自循环并且删除。
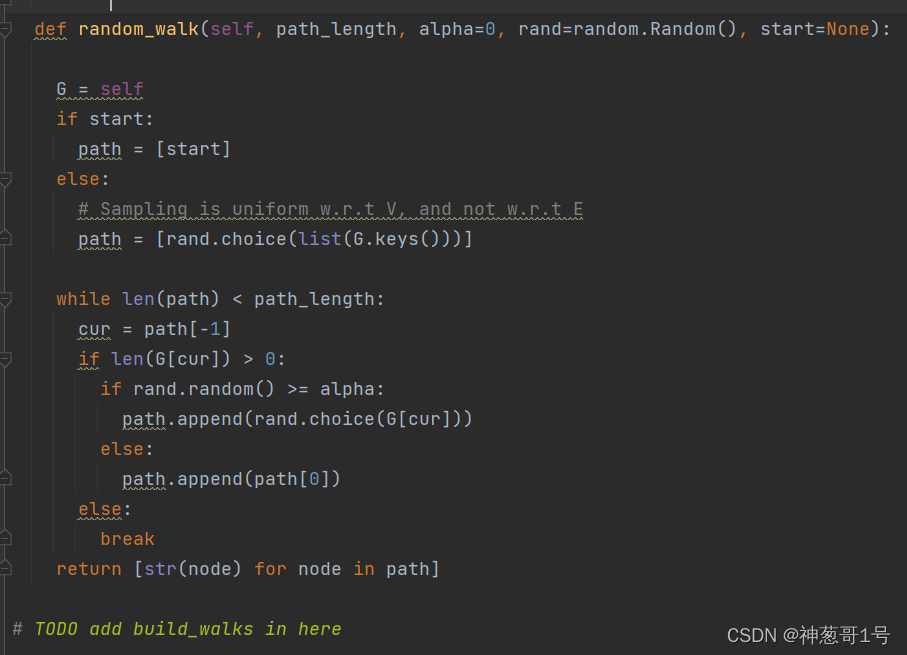
该函数是创建截断的随机游走,其中path_length代表游走的长度Alpha代表重启的概率
Start代表随机游走的开始节点。
 该函数对一个图生成一个语料库,即对于图G生成每个节点开始的多次的随机游走列表,
该函数对一个图生成一个语料库,即对于图G生成每个节点开始的多次的随机游走列表,
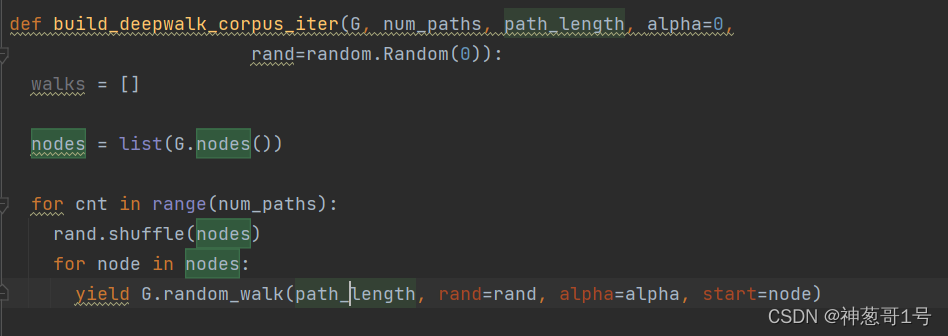
该函数也是生成语料库函数,但是不一样的是该函数采用yield函数进行迭代生成,是用于内存不足以保存路径的情况。
该类后面的函数主要作用就是将列表分成大小均匀的块。
Walks.py

上面俩个函数是计算词频的函数。
其中count_words的参数f中每行都是一个随机游走walk,函数最终返回这个file中每个单词出现的次数。
Count_textfiles使用了多线程的方法,也是返回每个单词出现的次数

上面俩个函数是将walks写入文件,一个是直接写入,另一个是采用多线程方式。
Grouper函数的大致含义
grouper(3, 'abcdefg', 'x') --> ('a','b','c'), ('d','e','f'), ('g','x','x')
第一个参数是整数int,第二个参数是可迭代对象,例如range(1,7+1) (返回1,2,3,4,5,6,7的迭代对象)如果第三个参数不写,则default为None,这样
grouper(3, range(1,7+1))-->(1,2,3),(4,5,6),(7,None,None)
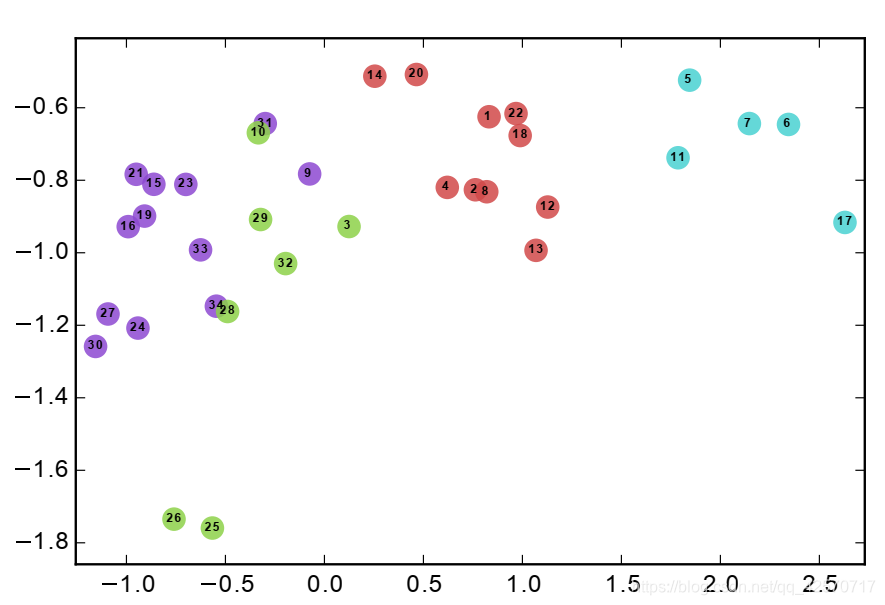
图的数据:
邻接矩阵为:

运行结果为:

2.总结:
Deepwalk算法我觉得是最经典的图嵌入算法之一。它采用了word2vec的方法思想,通过将一组组随机截断游走所生成的顶点序列当做一个个句子,然后去用word2vec进行训练,即用图中节点与节点的共现关系来学习节点的向量表示。
总的来说,这篇论文我认为是network embedding的开山之作,通过将NLP中word2vec的词向量的思想借鉴过来,来实现社交网络中的节点表示,因此提供了一种新的思路。因为社交网络中的节点分布太过于稀疏,所以deepwalk算法非常适用于标签稀疏的情况。其中随机截断游走的思想就是一种可重复访问已访问节点的深度优先遍历算法:
给定当前访问起始节点,从该起始节点中的所有邻居节点中随机采样作为下一个访问节点,并且有一定的概率返回原节点,重复此过程,直到序列长度等于给定的长度。在分析代码的过程中,依旧有些函数没怎么看懂,如多线程运行、评估那一块,但是关键的函数,包括生成随机截断游走、运用word2vec模型进行训练等这些已经领会
个人的看法:
算法优点:
1、在信息较少的稀疏网络表现优越
2、在线学习:DeepWalk是可扩展的
3、容易实现并行性。几个随机游走者(不同的线程,进程或机器)可以同时探索同一网络的不同部分。
4、适应性。当图变化后,不需要全局重新计算,可以迭代地更新学习模型。
算法缺点:
我觉得deepwalk只适用于无向图即无权边,因为它是概率性地选择自己的邻居顶点进行访问,而没有考虑到边的权重大小,但是在社交网络中边的权重是非常重要的。就比如说在一个学校的社交网络中,可能一个班级的同学他们的节点是相邻的,但是同寝室的他们的关系会更密切一点,也就是边的权重会更大一点,而deepwalk没有考虑到这些,这是我的看法。


![[论文阅读] (24) 向量表征:从Word2vec和Doc2vec到Deepwalk和Graph2vec,再到Asm2vec和Log2vec(一)](https://img-blog.csdnimg.cn/4d4a9a2edc814a68bfb40eac06927424.png#pic_center)