ChatGPT与代码克隆初探
- 背景
- 源代码克隆检测
- 简单代码片段源代码克隆检测
- 真实案例源代码克隆检测
- 不同语言下ChatGPT检测语义相似度
- 二进制代码相似度检测
- 检测简单二进制代码片段
- 真实案例二进制代码检测
- ChatGPT对抗代码混淆
- 总结
背景
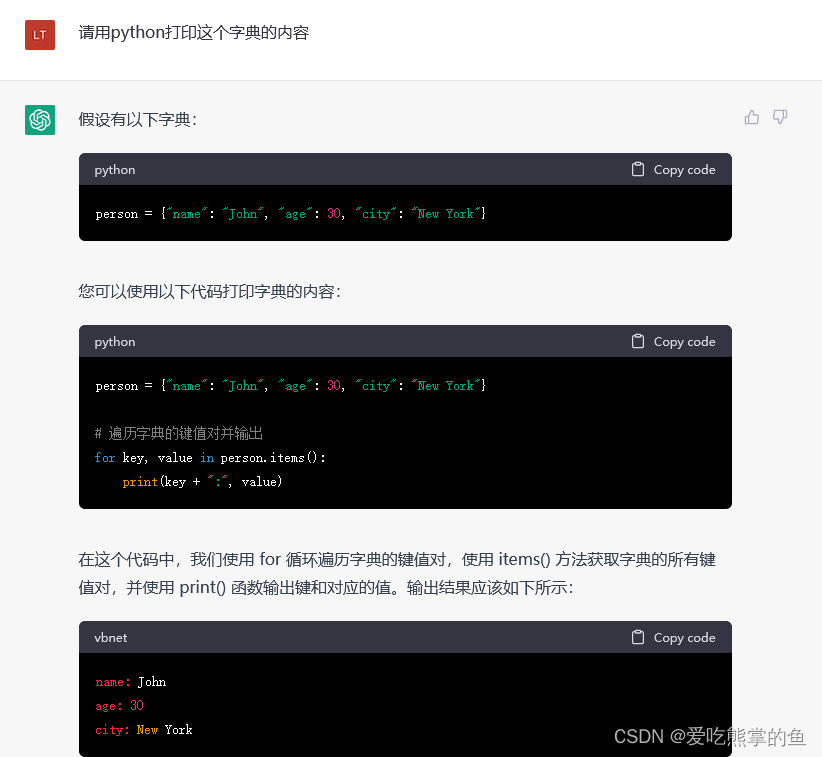
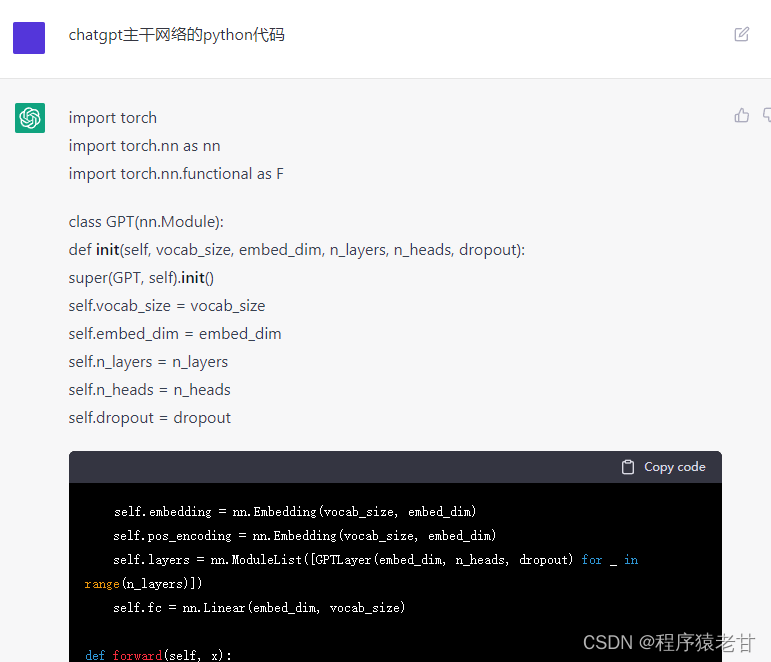
ChatGPT是由OpenAI研发的大型语言模型,可以通过自然语言与人交互,回答问题或者执行任务。虽然ChatGPT已经在多类NLP任务中均取得显著成果,特别是在软件工程领域,但是目前还没有ChatGPT在代码克隆方向的专门测评。本文将使用基于GPT-3.5的ChatGPT 来测评其相似代码检测能力。
代码克隆分为Type1到Type4四种类型,其中Type1、2、3的检测方法已颇为成熟,我们主要聚焦ChatGPT在Type4类克隆的检测效果。
| 克隆类型 | 解释 |
|---|---|
| Type1 | 仅有空行、空格和注释的区别 |
| Type2 | 变量名、函数名、类名不同,其余完全相同 |
| Type3 | 部分代码片段被修改,如增加、删除、移动部分代码片段 |
| Type4 | 语法不同但是语义相似的代码 |
我们将以高级语言的源代码可执行文件的反汇编代码作为测试样例,这也是代码克隆领域通用的测试对象。
源代码克隆检测
我们首先对高级语言的源代码进行测试,希望得到ChatGPT对Type4类型克隆的检测能力。
简单代码片段源代码克隆检测
我们使用for和switch-case创建一些具有简单循环或者分支结构的C代码,然后使用if-else结构和while结构创建语义相同的代码制作匹配对作为正例,将不同语义的代码相互匹配作为反例。最后使用ChatGPT来检测其语法,结构,语义是否相似,以及是否是代码克隆。
我们的提问模板如下:
提问者:我希望你能进行代码克隆检测工作,接下来我将给你两个函数,请你判断两个函数是否是代码克隆?语法是否相似,结构是否相似,语义是否相似,功能是否相似?
Function1的代码
Function2的代码
对于简单的代码片段,ChatGPT不但能准确判断出两个代码片段的语法、结构以及语义相似性,同时能够对其进行简单的解释说明,甚至有时还能推测出代码的意图
以下面一组代码为例,这是分别通过switch-case和if实现的将第一个参数加一并输出的函数。ChatGPT不仅准确无误地判断出两个函数的语法、语义以及结构相似,并且给出了对应的解释说明。
int function1(int a, int b, int c) {switch (a) {case 1:a = 2;case 2:a = 3;case 3:a = 4;case 4:a = 5;default:a = 6;}printf("%d\n", a);return 0;
}
int function2(int a, int b, int c) {if (a == 1) { a = 2; }if (a == 2) { a = 3; }if (a == 3) { a = 4; }if (a == 4) { a = 5; }if (a != 1 && a != 2 && a != 3 && a != 4)a = 6;printf("%d\n", a);return 0;
}
ChatGPT: 语法相似:这两个函数的语法相似,它们都包含了三个参数(int类型的a、b、c),并且都返回了int类型的值。它们的结构也相似,都包含了一个控制流程语句(switch语句和if语句),并且都包含了类似的赋值操作和打印语句。
语义相似:这两个函数的语义也相似,它们的目的都是根据a的不同值,将a的值修改为另一个值,并输出修改后的a的值。尽管它们的实现方式略有不同,但它们的实现目的是相同的。
结构相似:这两个函数的结构相似,它们都包含了一个控制流程语句,且都在结尾处打印a的值,以此输出修改后的结果。
代码克隆:考虑到以上三点,可以认为这两个函数是代码克隆。它们的语法、结构和语义都非常相似,差异只是在实现方式和细节上。
综上所述,根据我对这两个函数的分析,我认为它们是代码克隆。
值得注意的是,随着代码片段长度增加,以及两段代码的差异进一步扩大,ChatGPT虽然也能判断出语义(功能)相似,但是会认为两者不是代码克隆。此现象多次发生,在我们对其引导纠正后,ChatGPT能够发现自己的错误并给予纠正。
如下所示,这对函数的功能是用来计算一年的第几天,分别使用switch-case和if-else来实现,但是ChatGPT虽然辨别出两段代码功能相似,但是不认为两段代码是代码克隆,在经过人工指正后,ChatGPT可以发现自己逻辑上的漏洞并且给出正确答案。
int function1(int a, int b, int c)
{b1=b;int s = 0;switch (b1) {case 12:s += 30;case 11:s += 31;case 10:s += 30;case 9:s += 31;case 8:s += 31;case 7:s += 30;case 6:s += 31;case 5:s += 30;case 4:s += 31;case 3:s += 28;case 2:s += 31;case 1:s += a; break;}if (((c % 4 == 0 && c % 100 != 0) || (c % 400 == 0)) && (b > 2)) s++;return 0;
}
int function2(int a, int b, int c)
{
int s = 0;if (b == 12)s = 30+31+30+31+31+30+31+30+31+28+31+a;
else if(b==11)s= 31 + 30 + 31 + 31 + 30 + 31 + 30 + 31 + 28 + 31 + a;else if(b==10) s= 30 + 31 + 31 + 30 + 31 + 30 + 31 + 28 + 31 + a;else if(b==9)s= 31 + 31 + 30 + 31 + 30 + 31 + 28 + 31 + a;else if(b==8)s= 31 + 30 + 31 + 30 + 31 + 28 + 31 + a;else if(b==7) s= 30 + 31 + 30 + 31 + 28 + 31 + a;else if(b==6)s= 31 + 30 + 31 + 28 + 31 + a;else if(b==5)s= 30 + 31 + 28 + 31 + a;else if(b==4)s= 31 + 28 + 31 + a;else if(b==3) s= 28 + 31 + a;else if (b == 2) s = 31 + a;else if (b == 1)s += a;if (((c % 4 == 0 && c % 100 != 0) || (c % 400 == 0)) && (b > 2)) s++;return 0;
}
ChatGPT: 这两个函数具有相似的结构和语义,都是根据年月日计算出该日期是一年中的第几天,但它们的语法不同。 function1 使用了 switch 语句,而 function2 使用了 if-else 语句。
因为这两个函数的代码不同,所以可以判断它们不是代码克隆。但是,它们执行的任务非常相似,都是计算一年中的某个日期,所以可以认为它们的功能相似。
提问者:语义相同或者功能相同的代码是不是代码克隆?
ChatGPT: 代码克隆的定义是指两个或多个代码片段在形式上或语义上非常相似,以至于它们可以被视为从同一原型衍生而来。因此,如果两个代码片段在语义上或功能上非常相似,则可以被视为代码克隆。
提问者:那么为什么前面两个代码不算代码克隆?
ChatGPT: 前面的两个函数在语法和结构上很相似,但是它们在语义和功能上是不同的。例如,它们使用了不同的方式来计算每个月份的天数,其中一个使用了switch语句,而另一个使用了if-else语句。此外,它们在计算特定日期是否为闰年方面也使用了不同的方式。因此,尽管这两个函数有些相似,但它们并不是代码克隆。
提问者: 可是之前你说两个函数实现了相同的功能,而不是功能不同的函数?
ChatGPT: 非常抱歉,我的回答有误。您是正确的,两个函数实现了相同的功能,因此它们可以被视为代码克隆。我的回答可能引起了困惑。感谢您的纠正。
真实案例源代码克隆检测
我们从LeeCode平台上随机选取题目,并且捕获其评论区相同语言的不同答案作为语义相似的代码片段。为了防止代码注释和代码变量名的字面含义影响结果,我们首先对代码进行预处理:
- 删除注释。
- 将有意义的变量名更改为无意义的变量名。
- 将有意义的字符串统一替换为空串。
ChatGPT对于大部分正例和几乎所有反例都有效,其中,ChatGPT认为代码语义相似但是不是代码克隆的情况依旧大量存在,鉴于ChatGPT并不是专门为了检测代码克隆所设计的模型,所以我们在这里放宽要求,只需要ChatGPT判断出代码语义相似或功能相似即可认为ChatGPT正确识别了代码克隆。
下图是两段题为K 个一组翻转链表的LeeCode代码,ChatGPT虽然认为两段代码不是代码克隆,但是准确识别出两段代码的意图,因此,我们认为ChatGPT识别出了代码语义相似和代码克隆。
K 个一组翻转链表题目详细描述:
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
struct ListNode* a10(struct ListNode* a4, int k){struct ListNode* a1;struct ListNode* a2;struct ListNode* a3;if(a4 == NULL) return NULL;int i = 0;a3 = a4;for(i = 0; i < k; i++){if(a3 != NULL){a3 = a3->next;}else{return a4; }}a2 = a4;a1 = a2;a3 = a2->next;for(i = 1; i < k; i++){if(a3){a1->next = a3->next;a3->next = a2;a2 = a3;a3 = a1->next;}}
a1->next = a10(a3,k);
}
struct ListNode *a10(struct ListNode *a4, int k)
{struct ListNode *a6 = a4;struct ListNode *a5 = NULL;
struct ListNode a7 = {0};struct ListNode **a8 = (struct ListNode **)malloc(sizeof(struct ListNode *) * k);memset(a8, 0, sizeof(struct ListNode *) * k);a7.next = a4;a5 = &a7;while (a6 != NULL) {int a9 = 0;while (a9 < k && a6 != NULL) {a8[a9] = a6;a9++;a6 = a6->next;}if (a9 != k) {break;}while (a9 > 0) {a5->next = a8[a9 - 1];a5 = a5->next;a9--;}a5->next = a6;}free(a8);return a7.next;
}
ChatGPT: 这两个函数的名称和参数列表相同,但是它们的实现是不同的。它们的语法和结构略有不同,但它们的功能和语义相似。这是两个不同的函数,不是代码克隆。
此外,一个有趣的现象是ChatGPT每次的回答似乎并不一致,甚至能得到完全相反的结论,依旧是上面的例子,在多次重复提问后,ChatGPT关于语义相似度和代码克隆的判断上多个截然相反的答案。
ChatGPT: 这两个函数的语法和结构不同,因此它们不是代码克隆。虽然它们的名称和参数相同,但是它们的实现方式不同,使用了不同的变量和逻辑。此外,它们的功能也不完全相同。第一个函数是将链表的每个K个节点进行翻转,而第二个函数是将链表的每个K个节点进行翻转,但是递归地实现了这个过程。因此,虽然它们的名称相同,但它们的语义和功能并不相同。
ChatGPT: 这两个函数的名称和参数列表相同,但是它们的实现是不同的。它们的语法和结构略有不同,但它们的功能和语义相似。这是两个不同的函数,不是代码克隆。
ChatGPT: 这两个函数看起来非常相似,它们都是用来反转链表中每个长度为k的子链表。它们的语法和结构几乎一模一样,都使用了相同的变量名和逻辑结构。但是,第一个函数使用了一个额外的指针,而第二个函数则使用了递归实现。因此,虽然它们的语法和结构非常相似,但它们的语义和功能也略有不同。因此,可以将它们视为代码克隆的变体。
ChatGPT: 这两个函数看起来很相似,但是并不完全相同。它们都接受一个链表和一个整数 k 作为输入,将链表按照每 k 个节点进行反转。然而,它们的具体实现略有不同。
对于语法和结构相似性的检测,这两个函数之间的相似性非常高,它们使用了类似的变量名、数据结构、控制流结构和内存分配等。可以看出这些代码在某种程度上具有一定的复制粘贴的痕迹。
对于语义和功能的相似性检测,我们需要更深入地了解代码的行为。这两个函数的基本逻辑是一致的:对于每个长度为 k 的子链表,将其翻转,然后将它们按照原始顺序重新连接。然而,它们的具体实现略有不同。
在第一个函数中,它首先用一个指针数组 a8 存储子链表中的所有节点。然后,它使用两个 while 循环来反转子链表。在外部循环中,它将节点分组并将它们存储在 a8 数组中,然后在内部循环中将它们反转。在完成反转后,它将子链表重新连接到链表的尾部。
在第二个函数中,它首先使用一个循环来找到第 k 个节点,然后将它保存在变量 a3 中。接下来,它使用 a1 和 a2 指针来迭代地反转子链表,直到最后一个子链表被反转。在这个过程中,它将子链表的头节点和尾节点依次连接起来,形成一个反转后的子链表。在完成整个过程后,它使用递归来连接剩余的子链表。
因此,这两个函数虽然在代码层面上非常相似,但在实现细节和代码风格上有所不同。从功能上看,这两个函数具有相同的目标,但是它们的实现方式不同。因此,我们不能完全将它们视为代码克隆。
不同语言下ChatGPT检测语义相似度
在这里我们选择了一组不同寻常的设置,我们选择LeeCode下同一题目不同语言的实现方案,传统代码克隆仅仅检测相同语言下的代码相似度,比较不同语言下的代码相似度似乎并没有现实意义。但是这进一步降低了语法和结构的相似性,而专注于检测两段代码是否功能相似。结果显示,ChatGPT依旧具有较高的表现。
下图依旧是两段题为K 个一组翻转链表的LeeCode代码,左右两边分别由C语言和Python编写。让我们忽略ChatGPT对于代码克隆部分的判断,仅仅关注其对语义的解析和语义相似度的判断。令人震惊的是,ChatGPT确实能够成功判断出两段代码语义相似。
struct b3 *a10(struct b3 *a4, int k)
{struct b3 *a6 = a4;struct b3 *a5 = NULL;
struct b3 a7 = {0};struct b3 **a8 = (struct b3 **)malloc(sizeof(struct b3 *) * k);memset(a8, 0, sizeof(struct b3 *) * k);a7.next = a4;a5 = &a7;while (a6 != NULL) {int a9 = 0;while (a9 < k && a6 != NULL) {a8[a9] = a6;a9++;a6 = a6->next;}if (a9 != k) {break;}while (a9 > 0) {a5->next = a8[a9 - 1];a5 = a5->next;a9--;}a5->next = a6;}free(a8);return a7.next;
}
class Solution:def b1(self, b2: b3, b6: b3):b7 = b6.nextp = b2while b7 != b6:nex = p.nextp.next = b7b7 = pp = nexreturn b6, b2def b11(self, b2: b3, k: int) -> b3:b4 = b3(0)b4.next = b2b5 = b4while b2:b6 = b5for i in range(k):b6 = b6.nextif not b6:return b4.nextnex = b6.nextb2, b6 = self.b1(b2, b6)b5.next = b2b6.next = nexb5 = b6b2 = b6.nextreturn b4.next
ChatGPT:这是一个很有趣的问题。代码克隆检测是指在不同的代码片段中寻找相似的结构和语法,判断它们是否具有相似的功能和语义。通常,这项任务需要利用计算机科学中的算法和技术来实现。
在这种情况下,给出的两个函数看起来是不同的,它们的语法和结构都不相似。然而,它们可能具有相似的功能和语义,这是一项更为复杂的任务,需要更加深入的分析。
因此,我将对给出的两个函数进行以下分析:
第一个函数的功能是对链表进行k个一组的翻转,并返回新的链表头。它通过循环遍历链表,并使用动态数组来存储每组k个节点,然后将它们翻转并重新链接回原始的链表。
第二个函数的功能是对链表进行k个一组的翻转,并返回新的链表头。它使用递归和双指针的方法,将链表分为k个一组进行翻转,并将它们链接回原始的链表。
因此,这两个函数的功能和语义是相似的,它们都实现了对链表进行k个一组的翻转。然而,它们的实现方式是不同的,语法和结构也是不同的,因此它们不是代码克隆。
总的来说,代码克隆检测是一项非常复杂的任务,需要深入分析代码的语法、结构、功能和语义。在这种情况下,尽管这两个函数具有相似的功能和语义,但是它们的实现方式是不同的,因此它们不是代码克隆。
二进制代码相似度检测
与源代码克隆检测不同的是,二进制代码克隆检测需要将二进制可执行文件转化为汇编文件来进行比较。幸运的是,目前的反汇编工具十分成熟,我们可以直接将gcc编译的二进制文件转化为反汇编文件,来比较其代码相似度。
检测简单二进制代码片段
我们先使用简单的if-else、while和switch-case、for的结构变化来构建源代码克隆,并且将其对应的二进制可执行文件转化为汇编代码,来检测ChatGPT对二进制代码的检测能力。
总体而言,ChatGPT在简单的二进制代码片段下依旧可以发挥不错的效果。下图是两个简单的条件判断函数,分别使用switch-case和if-else来实现,可以看到,ChatGPT能够准确判断出得到两段代码是代码克隆。
public _002a
_002a proc near
var_C = dword ptr -0Ch
var_8 = dword ptr -8
var_4 = dword ptr -4endbr64push rbpmov rbp, rspsub rsp, 10hmov [rbp+var_4], edimov [rbp+var_8], esimov [rbp+var_C], edxcmp [rbp+var_4], 4jz short loc_130Bcmp [rbp+var_4], 4jg short loc_1312cmp [rbp+var_4], 3jz short loc_1304cmp [rbp+var_4], 3jg short loc_1312cmp [rbp+var_4], 1jz short loc_12F6cmp [rbp+var_4], 2jz short loc_12FDjmp short loc_1312
loc_12F6: mov [rbp+var_4], 2
loc_12FD: mov [rbp+var_4], 3
loc_1304: mov [rbp+var_4], 4
loc_130B: mov [rbp+var_4], 5
loc_1312: mov [rbp+var_4], 6mov eax, [rbp+var_4]mov esi, eaxlea rdi, format mov eax, 0call _printfmov eax, 0leaveretn
_002a endp
public _002a
_002b proc near
var_C = dword ptr -0Ch
var_8 = dword ptr -8
var_4 = dword ptr -4endbr64push rbpmov rbp, rspsub rsp, 10hmov [rbp+var_4], edimov [rbp+var_8], esimov [rbp+var_C], edxcmp [rbp+var_4], 1jnz short loc_1358mov [rbp+var_4], 2
loc_1358: cmp [rbp+var_4], 2jnz short loc_1365mov [rbp+var_4], 3
loc_1365: cmp [rbp+var_4], 3jnz short loc_1372mov [rbp+var_4], 4
loc_1372: cmp [rbp+var_4], 4jnz short loc_137Fmov [rbp+var_4], 5
loc_137F: cmp [rbp+var_4], 1jz short loc_139Ecmp [rbp+var_4], 2jz short loc_139Ecmp [rbp+var_4], 3jz short loc_139Ecmp [rbp+var_4], 4jz short loc_139Emov [rbp+var_4], 6
loc_139E: mov eax, [rbp+var_4]mov esi, eaxlea rdi, format mov eax, 0call _printfmov eax, 0leaveretn
_002b endp
ChatGPT:这两个函数非常相似,它们的结构、语法和语义都非常相似,甚至它们的功能也非常相似。虽然函数名不同,但它们的代码非常相似,因此可以认为它们是代码克隆。
这两个函数的主要区别在于以下几点:
函数名称不同;
在 _002a 函数中,有多个条件判断,而在 _002b 函数中,只有一个条件判断;
在 _002a 函数中,每个条件判断后面都有一段重复的代码,而在 _002b 函数中,只有最后一个条件判断后面有一段重复的代码。
因此,可以推断出 _002b 函数是从 _002a 函数中复制和粘贴的代码,只是稍微修改了一些代码,以便更好地满足 _002b 函数的需求。
值得注意的是,ChatGPT在对源码克隆检测结果和对应的二进制代码克隆检测结果存在不一致的情况。两个函数在源代码检测时可能认为是语义相似,而在二进制代码检测时会被认为是语义不同,或者是相反的情况。根据观察,这可能是由于编译器会将源代码相似的结构经过优化,转化成不相似的结构。比如switch-case也可能会被设置为二分查找或者跳转表,从而更改与变量的比较方式,而if-else并不会进行类似优化。
真实案例二进制代码检测
遗憾的是,ChatGPT对于真实情况下的二进制代码克隆检测并不理想,这主要是由于ChatGPT的目的是基于GPT-3模型设计的对话模型,而不是一个专门的代码克隆检测模型。GPT-3模型要求输入的token最多不能超过2048个,而真实案例的汇编代码很容易超过这个限制,即使是一些没有超过这个限制的代码,ChatGPT通常也不会给出期望的回答
ChatGPT:这两个函数都非常长,因此无法直接判断它们是否是代码克隆。一种常见的方法是使用代码克隆检测工具。目前有很多代码克隆检测工具可供选择,例如Simian、CloneDR、CCFinderX、NICAD等。
以Simian为例,您可以在其官方网站(https://www.harukizaemon.com/simian/index.html)上下载Simian的最新版本。安装完毕后,您可以使用以下命令来检测这两个函数是否是代码克隆:
simian --language cplusplus function1.cpp function2.cpp
其中,function1.cpp和function2.cpp是包含这两个函数代码的源文件。如果这两个函数是代码克隆,Simian将输出一条包含相似度和重复行数的信息。
当然,您还可以使用其他代码克隆检测工具进行检测。不同的工具可能具有不同的检测方法和算法,因此检测结果可能会有所不同
ChatGPT:这两个函数在汇编层面的代码非常相似,但是由于缺乏上下文信息,我无法确认它们是否是代码克隆。如果您能提供更多信息,比如两个函数的语言、目的、上下文、来源等等,我就可以更加准确地回答这个问题
ChatGPT对抗代码混淆
代码混淆,是指将计算机程序的代码,转换成一种功能上等价,但是难于阅读和理解的形式的行为。其中一种常见的混淆策略便是流混淆,即模糊代码的控制流,在不改变代码运行行为的基础上增加阅读的困难。我们采取手工添加伪指令流的策略,如下图所示,我们在左边的switch-case里采用了伪路径“case:2”,因为switch里是一个bool类型变量,其值只能是0或1,所以“case:2”是不可能运行的路径。可以观察到,ChatGPT并没有意识到这一点。
int _045a(int a, int b, char c)
{switch (a > 5){case 0:printf("this is 0\n");break;case 1:printf("this is 1\n");break;case 2:printf("this is 2\n");break;default:printf("this is default\n");return 0;}
}
int _045b(int a, int b, char c)
{if(a>5)printf("this is 1\n");else printf("this is 0\n");return 0;
}
ChatGPT:这两个函数并非代码克隆,尽管它们执行相似的操作,但它们的语法、结构和语义不同。具体来说:
语法不同:第一个函数使用了switch语句,而第二个函数使用了if-else语句。这两种语句的语法不同。
结构不同:第一个函数使用了switch语句,其中有三个case语句和一个default语句。而第二个函数只使用了if-else语句。这两个函数的结构不同。
语义不同:尽管这两个函数执行的是相似的操作,但它们的语义不同。第一个函数会打印出不同的消息,具体取决于a是否大于5。而第二个函数只会打印出两个固定的消息,即“this is 0”和“this is 1”。
因此,这两个函数不是代码克隆。
总结
总而言之,ChatGPT作为自然语言模型,在简单代码片段的克隆检测上乃至源代码的一些真实案例上取得了耀眼的表现,不但能够准确识别代码结构,并且能得到代码的语义,甚至能推测出代码的目的。但是在长片段的汇编代码上,ChatGPT的效果会产生显著下滑,经常出现无法判断的情况,哪怕两段代码极其相似。
此外,ChatGPT目前还会被代码混淆所欺骗,并不能得到代码混淆下的真实语义,攻击者很容易通过伪造不可达路径来逃避代码克隆检测。并且需要注意的是,ChatGPT在理解代码语义时,极易受到代码中有意义的字符干扰,如变量名、注释等。并且在解释语义时也会趋向于这些字符的含义,攻击者也可能通过字符串或者变量名替换,乃至添加无意义的长字符串来逃避代码克隆检测。
南开大学软件安全与测试研究室
王乾潞 王佩婕 过辰楷