上手使用
def subtract(other: RDD[T]): RDD[T]
def subtract(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]该函数类似于intersection,但返回在RDD中出现,并且不在otherRDD中出现的元素,去重(这个帖子里说不去重,但是我在spark1.6.1上运行,发现是会去重的。)。
参数含义同intersection
scala> var rdd1 = sc.makeRDD(Seq(1,2,2,3))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[66] at makeRDD at :21scala> rdd1.collect
res48: Array[Int] = Array(1, 2, 2, 3)scala> var rdd2 = sc.makeRDD(3 to 4)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[67] at makeRDD at :21scala> rdd2.collect
res49: Array[Int] = Array(3, 4)scala> rdd1.subtract(rdd2).collect
res50: Array[Int] = Array(1, 2)原理图
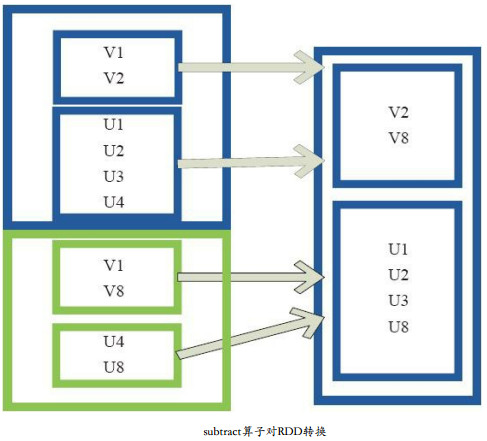
源码
/*** Return an RDD with the elements from `this` that are not in `other`.** Uses `this` partitioner/partition size, because even if `other` is huge, the resulting* RDD will be <= us.*/
def subtract(other: RDD[T]): RDD[T] =subtract(other, partitioner.getOrElse(new HashPartitioner(partitions.size)))/*** Return an RDD with the elements from `this` that are not in `other`.*/
def subtract(other: RDD[T], numPartitions: Int): RDD[T] =subtract(other, new HashPartitioner(numPartitions))/*** Return an RDD with the elements from `this` that are not in `other`.*/
def subtract(other: RDD[T], p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] = {if (partitioner == Some(p)) {// Our partitioner knows how to handle T (which, since we have a partitioner, is// really (K, V)) so make a new Partitioner that will de-tuple our fake tuplesval p2 = new Partitioner() {override def numPartitions = p.numPartitionsoverride def getPartition(k: Any) = p.getPartition(k.asInstanceOf[(Any, _)]._1)}// Unfortunately, since we're making a new p2, we'll get ShuffleDependencies// anyway, and when calling .keys, will not have a partitioner set, even though// the SubtractedRDD will, thanks to p2's de-tupled partitioning, already be// partitioned by the right/real keys (e.g. p).this.map(x => (x, null)).subtractByKey(other.map((_, null)), p2).keys} else {this.map(x => (x, null)).subtractByKey(other.map((_, null)), p).keys}
}参考
- jasonding 博客
- http://lxw1234.com 博客