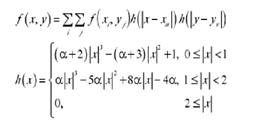Lightweight Image Super-Resolution with Information Multi-distillation Network

IMDB模块,

class IMDModule(nn.Module):def __init__(self, in_channels, distillation_rate=0.25):super(IMDModule, self).__init__()self.distilled_channels = int(in_channels * distillation_rate)self.remaining_channels = int(in_channels - self.distilled_channels)self.c1 = conv_layer(in_channels, in_channels, 3)self.c2 = conv_layer(self.remaining_channels, in_channels, 3)self.c3 = conv_layer(self.remaining_channels, in_channels, 3)self.c4 = conv_layer(self.remaining_channels, self.distilled_channels, 3)self.act = activation('lrelu', neg_slope=0.05)self.c5 = conv_layer(in_channels, in_channels, 1)self.cca = CCALayer(self.distilled_channels * 4)def forward(self, input):out_c1 = self.act(self.c1(input))distilled_c1, remaining_c1 = torch.split(out_c1, (self.distilled_channels, self.remaining_channels), dim=1)out_c2 = self.act(self.c2(remaining_c1))distilled_c2, remaining_c2 = torch.split(out_c2, (self.distilled_channels, self.remaining_channels), dim=1)out_c3 = self.act(self.c3(remaining_c2))distilled_c3, remaining_c3 = torch.split(out_c3, (self.distilled_channels, self.remaining_channels), dim=1)out_c4 = self.c4(remaining_c3)out = torch.cat([distilled_c1, distilled_c2, distilled_c3, out_c4], dim=1)out_fused = self.c5(self.cca(out)) + inputreturn out_fusedContrast-aware channel attention layer

# contrast-aware channel attention module
class CCALayer(nn.Module):def __init__(self, channel, reduction=16):super(CCALayer, self).__init__()self.contrast = stdv_channelsself.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv_du = nn.Sequential(nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),nn.ReLU(inplace=True),nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),nn.Sigmoid())def forward(self, x):y = self.contrast(x) + self.avg_pool(x)y = self.conv_du(y)return x * y结果