低分辨率图像重建
- 任务总览
- 数据加载与配置
- 模型设置
- 生成、判别、特征提取模块调用
- 损失函数与训练
- 测试
今天我们来介绍利用对抗生成网络(GAN)对低分辨率图像进行重构的介绍。再开始今天的任务之前,给大家强调一下,我们需要使用1.x.x版本的tensorflow和tensorlayer,我是用的是3.6版本的python,3.4.1.15版本的opencv以及1.8.0版本的tensorflow和tensorlayer。另外还有其他的一些模块需要安装,直接按照错误提示安装即可。
任务总览
分辨率在图片中的直接反应就是图像的大小,分辨率越高,图像的初始大小越大。如果将不同分辨率的图像放缩到同样的大小,分辨率低的图像会更模糊。超分辨率重构就是将分辨率低的图片重构成清晰的高分辨率图像:

所需要用到的网络结构图为:

数据加载与配置
这个部分对应着生成网络和判别网络的input部分的初始化。
首先需要大家下载srgan任务,打开config文件,我们主要的参数都将在这个文件中进行修改:
from easydict import EasyDict as edict
import json
config = edict()
config.TRAIN = edict()## Adam
# batch设置过大有可能会引发内存不足的报错
config.TRAIN.batch_size = 4 # 可以适当调整
config.TRAIN.lr_init = 1e-4
config.TRAIN.beta1 = 0.9
## 初始化生成器
config.TRAIN.n_epoch_init = 100
## 判别器学习 (SRGAN)
config.TRAIN.n_epoch = 2000
config.TRAIN.lr_decay = 0.1
config.TRAIN.decay_every = int(config.TRAIN.n_epoch / 2)# 训练集路径指定
config.TRAIN.hr_img_path = 'E:\srgan\srdata\srdata\DIV2K_train_HR'
config.TRAIN.lr_img_path = 'E:\srgan\srdata\srdata\DIV2K_train_LR_bicubic\X4'config.VALID = edict()
# 测试集路径制定
config.VALID.hr_img_path = 'E:\srgan\srdata\srdata\DIV2K_valid_HR'
config.VALID.lr_img_path = 'E:\srgan\srdata\srdata\DIV2K_valid_LR_bicubic\X4'def log_config(filename, cfg):with open(filename, 'w') as f:f.write("================================================\n")f.write(json.dumps(cfg, indent=4))f.write("\n================================================\n")
这里改好之后,我们需要对一些main.py文件里的函数进行一些设置,比如传递进batch_size,学习率,epoch等,同时要指定好生成的图像以及模型等文件的存储位置,之后把再图像读取进来:
import os
import time
import pickle, random
import numpy as np
import logging, scipyimport tensorflow as tf
import tensorlayer as tl
from model import SRGAN_g, SRGAN_d, Vgg19_simple_api
from utils import *
from config import config, log_config## Adam
batch_size = config.TRAIN.batch_size # 4
lr_init = config.TRAIN.lr_init # 1e-4
beta1 = config.TRAIN.beta1 # 0.9
## 初始化生成器
n_epoch_init = config.TRAIN.n_epoch_init # 100
## 判别器学习(SRGAN)
n_epoch = config.TRAIN.n_epoch # 2000
lr_decay = config.TRAIN.lr_decay # 0.1
decay_every = config.TRAIN.decay_every # 1000ni = int(np.sqrt(batch_size))def train():## 创建文件夹保存结果图像和训练模型save_dir_ginit = "samples/{}_ginit".format(tl.global_flag['mode'])save_dir_gan = "samples/{}_gan".format(tl.global_flag['mode'])tl.files.exists_or_mkdir(save_dir_ginit)tl.files.exists_or_mkdir(save_dir_gan)checkpoint_dir = "checkpoint" # checkpoint_resize_convtl.files.exists_or_mkdir(checkpoint_dir)# load_file_list可以把所有的文件都加载进来# path指定文件夹的路径# regx='.*.png'代表读取所有.png的文件train_hr_img_list = sorted(tl.files.load_file_list(path=config.TRAIN.hr_img_path, regx='.*.png', printable=False))[:800] # 如果出现memory error可以这样操作减少一次读取的数据量train_lr_img_list = sorted(tl.files.load_file_list(path=config.TRAIN.lr_img_path, regx='.*.png', printable=False)) # 不加切片读取也是可以的,但一定要注意传入的低分高分图像数量要匹配# 读取全部的内容花费时间较长valid_hr_img_list = sorted(tl.files.load_file_list(path=config.VALID.hr_img_path, regx='.*.png', printable=False))valid_lr_img_list = sorted(tl.files.load_file_list(path=config.VALID.lr_img_path, regx='.*.png', printable=False))## 如果计算机内存够大,可以加在全部内容# n_threads可以当成多线程,这里意思是每8张一组一并处理train_hr_imgs = tl.vis.read_images(train_hr_img_list, path=config.TRAIN.hr_img_path, n_threads=8)## 设置生成器、判别器和特征提取模块的输入内容# 制作生成器和判别器的输入数据t_image = tf.placeholder('float32', [batch_size, 96, 96, 3], name='t_image_input_to_SRGAN_generator')# 判别器接收的原始高分辨图像t_target_image = tf.placeholder('float32', [batch_size, 384, 384, 3], name='t_target_image')# vgg特征提取模块初始化设置t_target_image_224 = tf.image.resize_images(t_target_image, size=[224, 224], method=0, # 剪切成对应的大小align_corners=False) t_predict_image_224 = tf.image.resize_images(net_g.outputs, size=[224, 224], method=0, align_corners=False)
这样一来,我们就完成了数据的加载和小部分参数的配置。接下来我们就需要在main.py文件中继续调整生成模块、判别模块、特征提取、损失函数设置和测试模块。
模型设置
以上我们已经完成了读取文件夹内的图像内容的任务,接下来就需要用生成器和判别器分别处理各自的输入内容了。源码中生成器和判别器的具体操作是在model.py文件中执行的,main.py只是负责调用这个模块。因此我们先讲解model中的内容。首先说生成器:

生成器所需要用到的卷积和残差模块,以及对应结果加和处理都需要在这里进行设置:
import tensorflow as tf
import tensorlayer as tl
from tensorlayer.layers import *
import time
import os# 生成网络
def SRGAN_g(t_image, is_train=False, reuse=False):w_init = tf.random_normal_initializer(stddev=0.02)b_init = None # tf.constant_initializer(value=0.0)g_init = tf.random_normal_initializer(1., 0.02)with tf.variable_scope("SRGAN_g", reuse=reuse) as vs:# 输入层,内容+名字n = InputLayer(t_image, name='in')# 进行卷积(初始化)n = Conv2d(n, 64, (3, 3), (1, 1), act=tf.nn.relu, padding='SAME', W_init=w_init, name='n64s1/c')temp = n# 设置16个残差模块for i in range(16):nn = Conv2d(n, 64, (3, 3), (1, 1), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='n64s1/c1/%s' % i)nn = BatchNormLayer(nn, act=tf.nn.relu, is_train=is_train, gamma_init=g_init, name='n64s1/b1/%s' % i)nn = Conv2d(nn, 64, (3, 3), (1, 1), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='n64s1/c2/%s' % i)nn = BatchNormLayer(nn, is_train=is_train, gamma_init=g_init, name='n64s1/b2/%s' % i)nn = ElementwiseLayer([n, nn], tf.add, name='b_residual_add/%s' % i)n = nn# 残差信息整合# 对应网络示意图中的skip connection步骤n = Conv2d(n, 64, (3, 3), (1, 1), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='n64s1/c/m')n = BatchNormLayer(n, is_train=is_train, gamma_init=g_init, name='n64s1/b/m')# 把最开始的结果(temp)加到当前的结果当中n = ElementwiseLayer([n, temp], tf.add, name='add3')# 重构出图n = Conv2d(n, 256, (3, 3), (1, 1), act=None, padding='SAME', W_init=w_init, name='n256s1/1')n = SubpixelConv2d(n, scale=2, n_out_channel=None, act=tf.nn.relu, name='pixelshufflerx2/1')n = Conv2d(n, 256, (3, 3), (1, 1), act=None, padding='SAME', W_init=w_init, name='n256s1/2')n = SubpixelConv2d(n, scale=2, n_out_channel=None, act=tf.nn.relu, name='pixelshufflerx2/2')n = Conv2d(n, 3, (1, 1), (1, 1), act=tf.nn.tanh, padding='SAME', W_init=w_init, name='out')return n
对于判别器,也要在model中进行设置:

def SRGAN_d(input_images, is_train=True, reuse=False): # reuse指定为True意味着输入的图像是从原始数据集中取到的,# False意味着图像是生成器生成的# 参数的初始化指定w_init = tf.random_normal_initializer(stddev=0.02)b_init = None # tf.constant_initializer(value=0.0)gamma_init = tf.random_normal_initializer(1., 0.02)df_dim = 64lrelu = lambda x: tl.act.lrelu(x, 0.2)# 基础的判别网络with tf.variable_scope("SRGAN_d", reuse=reuse):tl.layers.set_name_reuse(reuse)net_in = InputLayer(input_images, name='input/images')net_h0 = Conv2d(net_in, df_dim, (4, 4), (2, 2), act=lrelu, padding='SAME', W_init=w_init, name='h0/c')net_h1 = Conv2d(net_h0, df_dim * 2, (4, 4), (2, 2), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='h1/c')net_h1 = BatchNormLayer(net_h1, act=lrelu, is_train=is_train, gamma_init=gamma_init, name='h1/bn')net_h2 = Conv2d(net_h1, df_dim * 4, (4, 4), (2, 2), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='h2/c')net_h2 = BatchNormLayer(net_h2, act=lrelu, is_train=is_train, gamma_init=gamma_init, name='h2/bn')net_h3 = Conv2d(net_h2, df_dim * 8, (4, 4), (2, 2), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='h3/c')net_h3 = BatchNormLayer(net_h3, act=lrelu, is_train=is_train, gamma_init=gamma_init, name='h3/bn')net_h4 = Conv2d(net_h3, df_dim * 16, (4, 4), (2, 2), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='h4/c')net_h4 = BatchNormLayer(net_h4, act=lrelu, is_train=is_train, gamma_init=gamma_init, name='h4/bn')net_h5 = Conv2d(net_h4, df_dim * 32, (4, 4), (2, 2), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='h5/c')net_h5 = BatchNormLayer(net_h5, act=lrelu, is_train=is_train, gamma_init=gamma_init, name='h5/bn')net_h6 = Conv2d(net_h5, df_dim * 16, (1, 1), (1, 1), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='h6/c')net_h6 = BatchNormLayer(net_h6, act=lrelu, is_train=is_train, gamma_init=gamma_init, name='h6/bn')net_h7 = Conv2d(net_h6, df_dim * 8, (1, 1), (1, 1), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='h7/c')net_h7 = BatchNormLayer(net_h7, is_train=is_train, gamma_init=gamma_init, name='h7/bn')net = Conv2d(net_h7, df_dim * 2, (1, 1), (1, 1), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='res/c')net = BatchNormLayer(net, act=lrelu, is_train=is_train, gamma_init=gamma_init, name='res/bn')net = Conv2d(net, df_dim * 2, (3, 3), (1, 1), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='res/c2')net = BatchNormLayer(net, act=lrelu, is_train=is_train, gamma_init=gamma_init, name='res/bn2')net = Conv2d(net, df_dim * 8, (3, 3), (1, 1), act=None, padding='SAME', W_init=w_init, b_init=b_init, name='res/c3')net = BatchNormLayer(net, is_train=is_train, gamma_init=gamma_init, name='res/bn3')net_h8 = ElementwiseLayer([net_h7, net], combine_fn=tf.add, name='res/add')net_h8.outputs = tl.act.lrelu(net_h8.outputs, 0.2)net_ho = FlattenLayer(net_h8, name='ho/flatten') # 池化net_ho = DenseLayer(net_ho, n_units=1, act=tf.identity, W_init=w_init, name='ho/dense')logits = net_ho.outputsnet_ho.outputs = tf.nn.sigmoid(net_ho.outputs)return net_ho, logits
如果上述内容中有不懂的参数,可以查询文档。
还有,我们需要把特征提取模块(VGG)加进来,这个模块具体的作用会在损失函数里具体介绍,我们这里只需要知道vgg会帮我们提取生成图像和原始高清图像做特征比对,我们把它也写到model里:
def Vgg19_simple_api(rgb, reuse):# 减均值VGG_MEAN = [103.939, 116.779, 123.68]with tf.variable_scope("VGG19", reuse=reuse) as vs:start_time = time.time()print("build model started")rgb_scaled = rgb * 255.0# Convert RGB to BGRred, green, blue = tf.split(rgb_scaled, 3, 3)assert red.get_shape().as_list()[1:] == [224, 224, 1]assert green.get_shape().as_list()[1:] == [224, 224, 1]assert blue.get_shape().as_list()[1:] == [224, 224, 1]bgr = tf.concat([blue - VGG_MEAN[0],green - VGG_MEAN[1],red - VGG_MEAN[2],], axis=3)assert bgr.get_shape().as_list()[1:] == [224, 224, 3] #""" input layer """net_in = InputLayer(bgr, name='input')# 每卷积一轮特征图的大小缩小为原来的1/4(长宽各缩小一半)""" conv1 """network = Conv2d(net_in, n_filter=64, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv1_1')network = Conv2d(network, n_filter=64, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv1_2')network = MaxPool2d(network, filter_size=(2, 2), strides=(2, 2), padding='SAME', name='pool1')""" conv2 """network = Conv2d(network, n_filter=128, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv2_1')network = Conv2d(network, n_filter=128, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv2_2')network = MaxPool2d(network, filter_size=(2, 2), strides=(2, 2), padding='SAME', name='pool2')""" conv3 """network = Conv2d(network, n_filter=256, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv3_1')network = Conv2d(network, n_filter=256, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv3_2')network = Conv2d(network, n_filter=256, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv3_3')network = Conv2d(network, n_filter=256, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv3_4')network = MaxPool2d(network, filter_size=(2, 2), strides=(2, 2), padding='SAME', name='pool3')""" conv4 """network = Conv2d(network, n_filter=512, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv4_1')network = Conv2d(network, n_filter=512, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv4_2')network = Conv2d(network, n_filter=512, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv4_3')network = Conv2d(network, n_filter=512, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv4_4')network = MaxPool2d(network, filter_size=(2, 2), strides=(2, 2), padding='SAME', name='pool4') # (batch_size, 14, 14, 512)conv = network""" conv5 """network = Conv2d(network, n_filter=512, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv5_1')network = Conv2d(network, n_filter=512, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv5_2')network = Conv2d(network, n_filter=512, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv5_3')network = Conv2d(network, n_filter=512, filter_size=(3, 3), strides=(1, 1), act=tf.nn.relu, padding='SAME', name='conv5_4')network = MaxPool2d(network, filter_size=(2, 2), strides=(2, 2), padding='SAME', name='pool5') # (batch_size, 7, 7, 512)""" fc 6~8 """network = FlattenLayer(network, name='flatten')network = DenseLayer(network, n_units=4096, act=tf.nn.relu, name='fc6')network = DenseLayer(network, n_units=4096, act=tf.nn.relu, name='fc7')network = DenseLayer(network, n_units=1000, act=tf.identity, name='fc8')print("build model finished: %fs" % (time.time() - start_time))return network, conv
这样一来,训练所需要的模型我们就设置好了,跑代码的时候就可以直接调用了。
生成、判别、特征提取模块调用
GAN网络是一个由生成器和判别器互相耦合网络,生成器的生成并不直接受训练集的约束,因此生成器输入的内容与训练集输入不同。在上一讲中,由于任务简单,我们直接用随机噪声作为生成器的输入,但今天,为了适应较为复杂的超分辨率任务,srgan网络设计了用低分辨率图像作为生成器的初始化输入。下面我们写代码调用模块完成生成、判别和特征提取(继续补到main.py后面):
# 数据传入网络net_g = SRGAN_g(t_image, is_train=True, reuse=False)net_d, logits_real = SRGAN_d(t_target_image, is_train=True, reuse=False) # 让网络判为真# reuse设置为真可以帮我们自动重新构建网络_, logits_fake = SRGAN_d(net_g.outputs, is_train=True, reuse=True) # 让网络判为假## 可以用以下方式查看网络的各种参数、层数等# net_g.print_params(False)# net_g.print_layers()# net_d.print_params(False)# net_d.print_layers()# reuse和之前一样,表示图像是生成结果(False)或数据集中取出的高清图片(True)net_vgg, vgg_target_emb = Vgg19_simple_api((t_target_image_224 + 1) / 2, reuse=False)_, vgg_predict_emb = Vgg19_simple_api((t_predict_image_224 + 1) / 2, reuse=True)
损失函数与训练
损失函数是可以对生成结果产生关键影响的部分,如何设计好便是关键。这里我们选择用以下三个方面作为损失函数的考量因素:
- MSEloss均方误差损失,用生成图像与训练集中对应的高分辨率图像进行逐个像素点比较,计算对应的损失;
- VGG特征提取模块,将生成模块与原高清图像进行相同的卷积提取特征,然后将提取到的特征进行对比,计算对应损失;
- GANloss,这是经典的损失,用于衡量生成结果经过判别器所产生的损失。
我们先知道需要用到的这些损失即可,它们的作用会在注释中给大家介绍。下面的代码仍是main.py中的内容:
# 判别器loss,传递进数据时给数据打上标号# tf.ones_like(logits_real)生成了与logits_real等大的全1矩阵代表是真实取出的内容d_loss1 = tl.cost.sigmoid_cross_entropy(logits_real, tf.ones_like(logits_real), name='d1')# tf.ones_like(logits_fake)生成了与logits_fake等大的全0矩阵代表是生成器生成的内容d_loss2 = tl.cost.sigmoid_cross_entropy(logits_fake, tf.zeros_like(logits_fake), name='d2')d_loss = d_loss1 + d_loss2# 生成网络希望logits_fake和高分辨率原图更像# logits_fake是判别器对生成图像的特征判别结果,我们将用它与和它等大的全1矩阵进行比较,得到损失值g_gan_loss = 1e-3 * tl.cost.sigmoid_cross_entropy(logits_fake, tf.ones_like(logits_fake), name='g')# 生成图像与真实高清图做逐帧比较mse_loss = tl.cost.mean_squared_error(net_g.outputs, t_target_image, is_mean=True)# 进行vgg特征图的比较vgg_loss = 2e-6 * tl.cost.mean_squared_error(vgg_predict_emb.outputs, vgg_target_emb.outputs, is_mean=True)g_loss = mse_loss + vgg_loss + g_gan_lossg_vars = tl.layers.get_variables_with_name('SRGAN_g', True, True)d_vars = tl.layers.get_variables_with_name('SRGAN_d', True, True)# 初始化学习率with tf.variable_scope('learning_rate'):lr_v = tf.Variable(lr_init, trainable=False)# 预训练g_optim_init = tf.train.AdamOptimizer(lr_v, beta1=beta1).minimize(mse_loss, var_list=g_vars)## SRGANg_optim = tf.train.AdamOptimizer(lr_v, beta1=beta1).minimize(g_loss, var_list=g_vars)d_optim = tf.train.AdamOptimizer(lr_v, beta1=beta1).minimize(d_loss, var_list=d_vars)##================重建模型====================sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=False))tl.layers.initialize_global_variables(sess)# 查看checkpoint中是否有训练好的模型,有则加载,没有模型从0开始训练if tl.files.load_and_assign_npz(sess=sess, name=checkpoint_dir + '/g_{}.npz'.format(tl.global_flag['mode']), network=net_g) is False:tl.files.load_and_assign_npz(sess=sess, name=checkpoint_dir + '/g_{}_init.npz'.format(tl.global_flag['mode']), network=net_g)tl.files.load_and_assign_npz(sess=sess, name=checkpoint_dir + '/d_{}.npz'.format(tl.global_flag['mode']), network=net_d)##===============加载特征提取模型===============vgg19_npy_path = "vgg19.npy"if not os.path.isfile(vgg19_npy_path):print("Please download vgg19.npz")exit()npz = np.load(vgg19_npy_path, encoding='latin1').item()params = []for val in sorted(npz.items()): # 提取vgg模块中的参数W = np.asarray(val[1][0])b = np.asarray(val[1][1])print(" Loading %s: %s, %s" % (val[0], W.shape, b.shape))params.extend([W, b])tl.files.assign_params(sess, params, net_vgg)print ('ok')## 开始训练## 在训练过程中使用训练集的第一个batch_size进行快速测试sample_imgs = train_hr_imgs[0:batch_size]sample_imgs_384 = tl.prepro.threading_data(sample_imgs, fn=crop_sub_imgs_fn, is_random=False)print('sample HR sub-image:', sample_imgs_384.shape, sample_imgs_384.min(), sample_imgs_384.max())sample_imgs_96 = tl.prepro.threading_data(sample_imgs_384, fn=downsample_fn)print('sample LR sub-image:', sample_imgs_96.shape, sample_imgs_96.min(), sample_imgs_96.max())tl.vis.save_images(sample_imgs_96, [ni, ni], save_dir_ginit + '/_train_sample_96.png')tl.vis.save_images(sample_imgs_384, [ni, ni], save_dir_ginit + '/_train_sample_384.png')tl.vis.save_images(sample_imgs_96, [ni, ni], save_dir_gan + '/_train_sample_96.png')tl.vis.save_images(sample_imgs_384, [ni, ni], save_dir_gan + '/_train_sample_384.png')## 固定学习率学习sess.run(tf.assign(lr_v, lr_init))print(" ** fixed learning rate: %f (for init G)" % lr_init)for epoch in range(0, n_epoch_init + 1):epoch_time = time.time()total_mse_loss, n_iter = 0, 0for idx in range(0, len(train_hr_imgs), batch_size):step_time = time.time()b_imgs_384 = tl.prepro.threading_data(train_hr_imgs[idx:idx + batch_size], fn=crop_sub_imgs_fn, is_random=True)b_imgs_96 = tl.prepro.threading_data(b_imgs_384, fn=downsample_fn)## 更新生成器errM, _ = sess.run([mse_loss, g_optim_init], {t_image: b_imgs_96, t_target_image: b_imgs_384})print("Epoch [%2d/%2d] %4d time: %4.4fs, mse: %.8f " % (epoch, n_epoch_init, n_iter, time.time() - step_time, errM))total_mse_loss += errMn_iter += 1log = "[*] Epoch: [%2d/%2d] time: %4.4fs, mse: %.8f" % (epoch, n_epoch_init, time.time() - epoch_time, total_mse_loss / n_iter)print(log)## 快速测试if (epoch != 0) and (epoch % 10 == 0):out = sess.run(net_g_test.outputs, {t_image: sample_imgs_96}) print("[*] save images")tl.vis.save_images(out, [ni, ni], save_dir_ginit + '/train_%d.png' % epoch)## 每十个epoch保存一次模型if (epoch != 0) and (epoch % 10 == 0):tl.files.save_npz(net_g.all_params, name=checkpoint_dir + '/g_{}_init.npz'.format(tl.global_flag['mode']), sess=sess)###========================= train GAN (SRGAN) =========================###for epoch in range(0, n_epoch + 1):## 更新学习率if epoch != 0 and (epoch % decay_every == 0):new_lr_decay = lr_decay**(epoch // decay_every)sess.run(tf.assign(lr_v, lr_init * new_lr_decay))log = " ** new learning rate: %f (for GAN)" % (lr_init * new_lr_decay)print(log)elif epoch == 0:sess.run(tf.assign(lr_v, lr_init))log = " ** init lr: %f decay_every_init: %d, lr_decay: %f (for GAN)" % (lr_init, decay_every, lr_decay)print(log)epoch_time = time.time()total_d_loss, total_g_loss, n_iter = 0, 0, 0for idx in range(0, len(train_hr_imgs), batch_size):step_time = time.time()b_imgs_384 = tl.prepro.threading_data(train_hr_imgs[idx:idx + batch_size], fn=crop_sub_imgs_fn, is_random=True)b_imgs_96 = tl.prepro.threading_data(b_imgs_384, fn=downsample_fn)## 更新判别器errD, _ = sess.run([d_loss, d_optim], {t_image: b_imgs_96, t_target_image: b_imgs_384})## 更新生成器errG, errM, errV, errA, _ = sess.run([g_loss, mse_loss, vgg_loss, g_gan_loss, g_optim], {t_image: b_imgs_96, t_target_image: b_imgs_384})print("Epoch [%2d/%2d] %4d time: %4.4fs, d_loss: %.8f g_loss: %.8f (mse: %.6f vgg: %.6f adv: %.6f)" %(epoch, n_epoch, n_iter, time.time() - step_time, errD, errG, errM, errV, errA))total_d_loss += errDtotal_g_loss += errGn_iter += 1log = "[*] Epoch: [%2d/%2d] time: %4.4fs, d_loss: %.8f g_loss: %.8f" % (epoch, n_epoch, time.time() - epoch_time, total_d_loss / n_iter,total_g_loss / n_iter)print(log)## quick evaluation on train setif (epoch != 0) and (epoch % 10 == 0):out = sess.run(net_g_test.outputs, {t_image: sample_imgs_96}) #; print('gen sub-image:', out.shape, out.min(), out.max())print("[*] save images")tl.vis.save_images(out, [ni, ni], save_dir_gan + '/train_%d.png' % epoch)## 保存模型if (epoch != 0) and (epoch % 10 == 0):tl.files.save_npz(net_g.all_params, name=checkpoint_dir + '/g_{}.npz'.format(tl.global_flag['mode']), sess=sess)tl.files.save_npz(net_d.all_params, name=checkpoint_dir + '/d_{}.npz'.format(tl.global_flag['mode']), sess=sess)def evaluate():## create folders to save result imagessave_dir = "samples/{}".format(tl.global_flag['mode'])tl.files.exists_or_mkdir(save_dir)checkpoint_dir = "checkpoint"valid_hr_img_list = sorted(tl.files.load_file_list(path=config.VALID.hr_img_path, regx='.*.png', printable=False))valid_lr_img_list = sorted(tl.files.load_file_list(path=config.VALID.lr_img_path, regx='.*.png', printable=False))valid_lr_imgs = tl.vis.read_images(valid_lr_img_list, path=config.VALID.lr_img_path, n_threads=8)valid_hr_imgs = tl.vis.read_images(valid_hr_img_list, path=config.VALID.hr_img_path, n_threads=8)
测试
测试部分主要是检查生成器跑出的模型(保存在checkpoint里的g_srgan.npz文件)是否实用,而判别器的学习结果我们并没有进行保存。想要进行测试,就需要传入低分辨率图像,让图像经过模型生成高分辨率图像,在与真实的高分辨率图像进行对比。先来看看代码,这部分代码依然是main.py的后续部分:
imid = 9 # 输入待超分的低分辨率图像序号valid_lr_img = valid_lr_imgs[imid]valid_hr_img = valid_hr_imgs[imid]valid_lr_img = (valid_lr_img / 127.5) - 1size = valid_lr_img.shapet_image = tf.placeholder('float32', [1, None, None, 3], name='input_image')net_g = SRGAN_g(t_image, is_train=False, reuse=False)###========================== RESTORE G =============================###sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=False))tl.layers.initialize_global_variables(sess)tl.files.load_and_assign_npz(sess=sess, name=checkpoint_dir + '/g_srgan.npz', network=net_g)###======================= EVALUATION =============================###start_time = time.time()out = sess.run(net_g.outputs, {t_image: [valid_lr_img]})print("took: %4.4fs" % (time.time() - start_time))print("LR size: %s / generated HR size: %s" % (size, out.shape))print("[*] save images")tl.vis.save_image(out[0], save_dir + '/valid_gen.png')tl.vis.save_image(valid_lr_img, save_dir + '/valid_lr.png')tl.vis.save_image(valid_hr_img, save_dir + '/valid_hr.png')out_bicu = scipy.misc.imresize(valid_lr_img, [size[0] * 4, size[1] * 4], interp='bicubic', mode=None)tl.vis.save_image(out_bicu, save_dir + '/valid_bicubic.png')if __name__ == '__main__':import argparseparser = argparse.ArgumentParser()parser.add_argument('--mode', type=str, default='evaluate', help='srgan, evaluate')# 这个参数可以选择srgan或evaluateargs = parser.parse_args()tl.global_flag['mode'] = args.modeif tl.global_flag['mode'] == 'srgan':# 先训练后输出train()evaluate()elif tl.global_flag['mode'] == 'evaluate':evaluate()else:raise Exception("Unknow --mode")
这样我们就可以借助训练出的模型对图像进行超分了,运行的结果会给我们保存到evaluate文件夹中,我们可以来对比一下:

从左至右依次为原低分辨率图像、超分图像、原高分辨率图像。如果大家觉得结果对比不是很明显的话,可以自己运行一下试试看啦~
下面给大家贴一些训练时的部分pycharm终端内容:
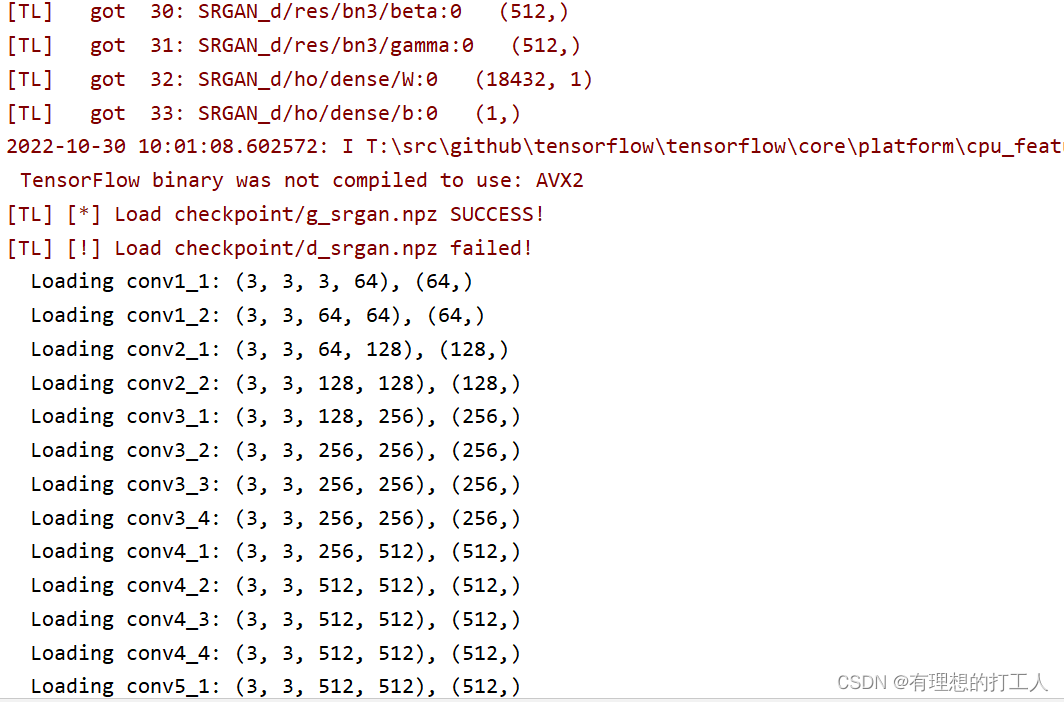
(这后面还有一个2000epoch的训练我忘记截了,真的很难难跑…都看到这里了确定不点个赞嘛)
今天的内容就到这里了,代码很多,但是我们需要修改的地方并不太多,希望对大家有所帮助。