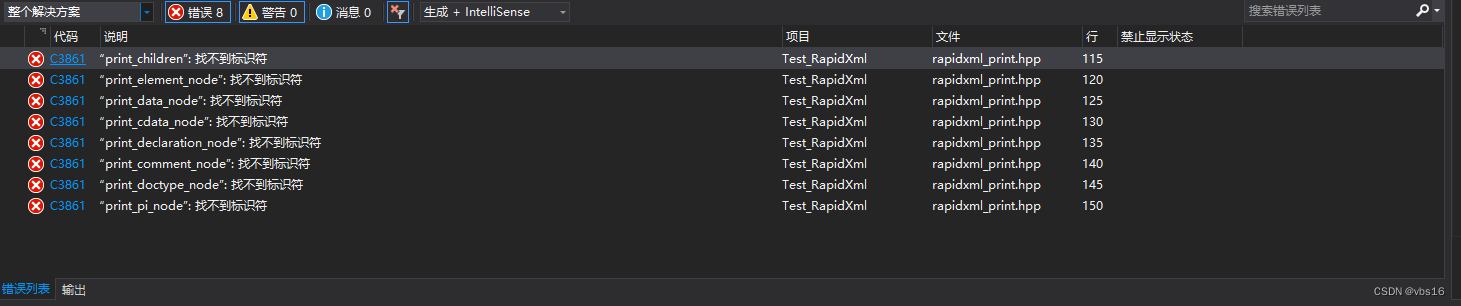
解析效率比Xerces DOM 快50-100倍,tinyxml快30-60 ,作者自己牛逼哄哄的说这是他所知道的最快的xml解析库了~~
作者介绍说:" The table below compares speed of RapidXml to some other parsers, and to strlen() function executed on the same data. On a modern CPU (as of 2007), you can expect parsing throughput to be close to 1 GB/s. As a rule of thumb, parsing speed is about 50-100x faster than Xerces DOM, 30-60x faster than TinyXml, 3-12x faster than pugxml, and about 5% - 30% faster than pugixml, the fastest XML parser I know of. "
项目地址:http://rapidxml.sourceforge.net/
具体介绍可以到这边看看:http://rapidxml.sourceforge.net/manual.html
嘛也不说 通过一个例子来看看这个工具的好用之处。
xml 文件:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<title id="1" qnums="1">
<name color="255,255,50" fontsize="16" >TEST</name>
<question type="math" gentype="auto" desc="because 1+1=2" ><![CDATA[
function matchwo(a,b)
{
if (a < b && a < 0) then{return 1;}
else{return 0;}
}
]]>
</question>
</title>
</root>源码:
// example.cpp : Defines the entry point for the console application.
//#include "stdafx.h"#include "rapidxml/rapidxml.hpp"
#include "vector"
#include "windows.h"
#include "iostream"
using namespace std;
using namespace rapidxml;#include "stdio.h"#define GET_ATTRIBUTE(pRetval,node,val) xml_attribute<> *pAttr##pRetval=(node)->first_attribute((val));\if (pAttr##pRetval){ (pRetval)=pAttr##pRetval->value();} /*
只适用在用parse_default解析的情况下。
*/
const char *GetNodeValue(xml_node<> *node )
{if (node == NULL){return "";}if (node->value()!=NULL && (node->value())[0]!='\0' ){return node->value();}xml_node<> *cdatanode=node->first_node();if (cdatanode !=NULL && cdatanode->type() == node_cdata){return cdatanode->value();}return "";
}/*
parse_default:为了提高效率会将原始数据改变,每个属性值后面加上结束符\0
parse_non_destructive:不会改变原始数据
*/int parseDataXml(const char *szXml)
{try{xml_document<char> doc; // character type defaults to chardoc.parse<parse_default>((char *)szXml); //parse_non_destructive xml_node<> *root = doc.first_node();// 获取跟节点xml_node<> *TitleNode = root->first_node("title"); if (TitleNode){xml_node<> *NameNode = TitleNode->first_node("name");string strName;strName=GetNodeValue(NameNode);printf("strName[%s]\n",strName.c_str());string color;char *pcolor=NULL;GET_ATTRIBUTE(pcolor,NameNode,"color");printf("pcolor[%s]\n",pcolor==NULL?"":pcolor);} }catch(parse_error &e){printf("%s\n",e.what());}return 1;
}int _tmain(int argc, _TCHAR* argv[])
{{FILE *fp=NULL;fp=fopen("data.xml","rb");char buf[1024];string xml="";while ( fgets(buf,1024,fp)!= NULL){xml+=buf;}fclose(fp);parseDataXml(xml.c_str());}getchar();return 1;
}输出:

对于这个开源库,轻量级,dom模型表述清晰 。我实在找不到缺点,因为项目的关系 主要还是用它作为解析用,所以我还是把它封装了多几个接口:
int GetXmlAttrValue(xml_node<> *node,const char *val,std::string &strval);
int GetXmlNodeValue(xml_node<> *node ,string &retVal);
int GetXmlChildNodeValue(const xml_node<> *rootNode,const char* pszChildStr ,string &strRet);
int GetXmlNode(const xml_node<> *rootNode,STR_VECTOR & VecStr , xml_node<> * &stRetNode);
源码下载
不对之处敬请谅解~~ 欢迎交流~~~