日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
搜索引擎:Elasticsearch、Solr、Lucene
- ELK中的ES:Elasticsearch
- SolrCloud 的搭建、使用
- Solr 高亮显示
- Spring Data Solr 使用
- Solr的安装与配置
- Solr 原理、API 使用
- Lucene 原理、API使用
- Lucene 得分算法
Solr的概述

1.Solr的下载:官网:http://lucene.apache.org历史版本下载网址:http://archive.apache.org/dist/lucene/solr/2.Solr的安装:右键解压到当前文件夹即可,注意:解压的目录中一定不要中文和空格。
Solr的的目录结构
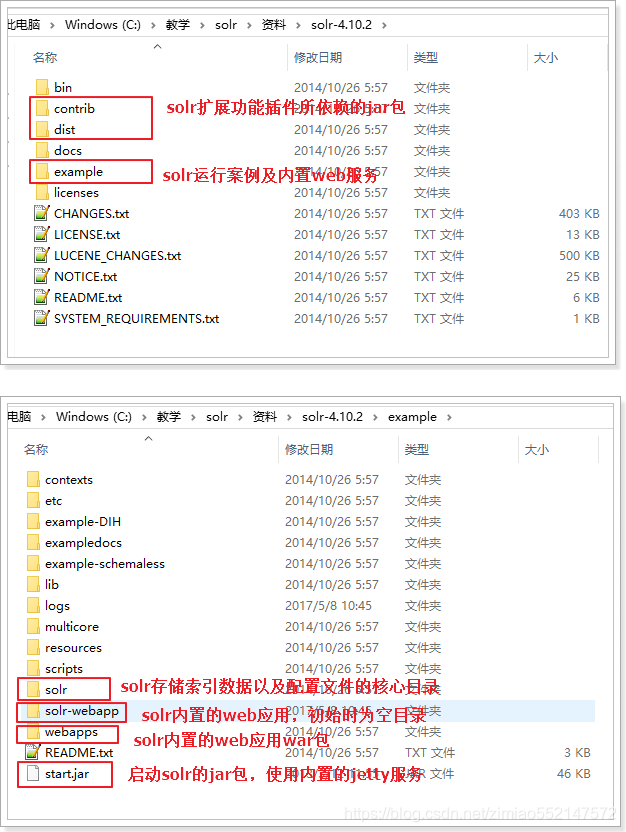
1.我们最需要关注的就是:example目录。其中就有搭建Solr服务的详细案例。
2.启动Solr的jar包:需要使用内置的Jetty服务。Jetty是一个WEB容器。
3.Solr目录:包含全文检索要存储的索引数据以及相关的一些配置文件。
4.solr-webapp和webapps:其实包含的是一样的内容,都是Solr的内置Web应用,我们可以通过Http请求访问该应用,实现对Solr服务的管理和访问
5.start.jar包:web应用需要一个Web容器来启动,而这个jar包会使用一个叫做Jetty的WEB容器(类似与Tomcat),来启动Solr的Web服务。
启动Solr的
第一种方式:码头服务器启动的Solr
步骤:1.第一步:进入 \solr-4.10.2\example 目录,该目录下存在“start.jar”用于 Jetty服务器启动Solr2.第二步:打开命令行窗口,执行“java –jar start.jar”命令,即可启动Solr服务3.第三步:打开浏览器,通过“http://localhost:8983/solr”来访问Solr管理页面。(Jetty服务的默认端口是8983)
第二种方式:Tomcat的服务器启动
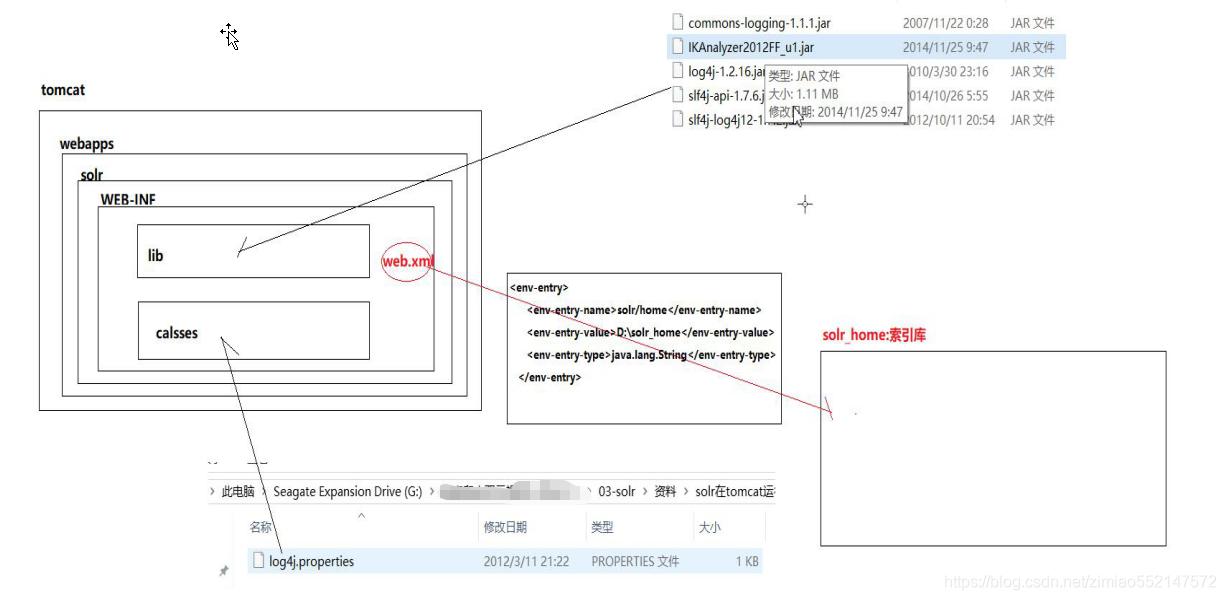
步骤:1.第一步:部署Web服务。1.将 \solr-4.10.2\example\webapps目录下的“solr.war”拷贝到自己的 \apache-tomcat-8.5.16\webapps目录中。2.两种方式解压“solr.war”:第一种解压方式:直接右键解压“solr.war”第二种解压方式:运行\apache-tomcat-8.5.16\bin目录下的“startup.bat”,便会自动解压webapps目录中的“solr.war”3.解压完毕后可以删除“solr.war”。注意:如果是使用第二种解压方式启动了“startup.bat”的话,则必须先执行“shutdown.bat”关闭Tomcat之后,才能再删除“solr.war”,否则在删除“solr.war”时,会连解压后的目录也一起删除的2.第二步:1.将“\资料\solr在tomcat运行需要导入的jar包\classes”文件夹下的“log4j.properties”拷贝到“\apache-tomcat-8.5.16\webapps\solr\WEB-INF”目录下2.将“\资料\solr在tomcat运行需要导入的jar包\lib”文件夹下的jar包拷贝到“\apache-tomcat-8.5.16\webapps\solr\WEB-INF\lib”目录下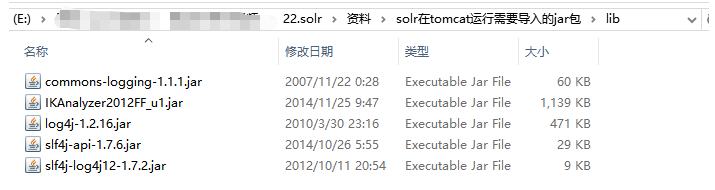
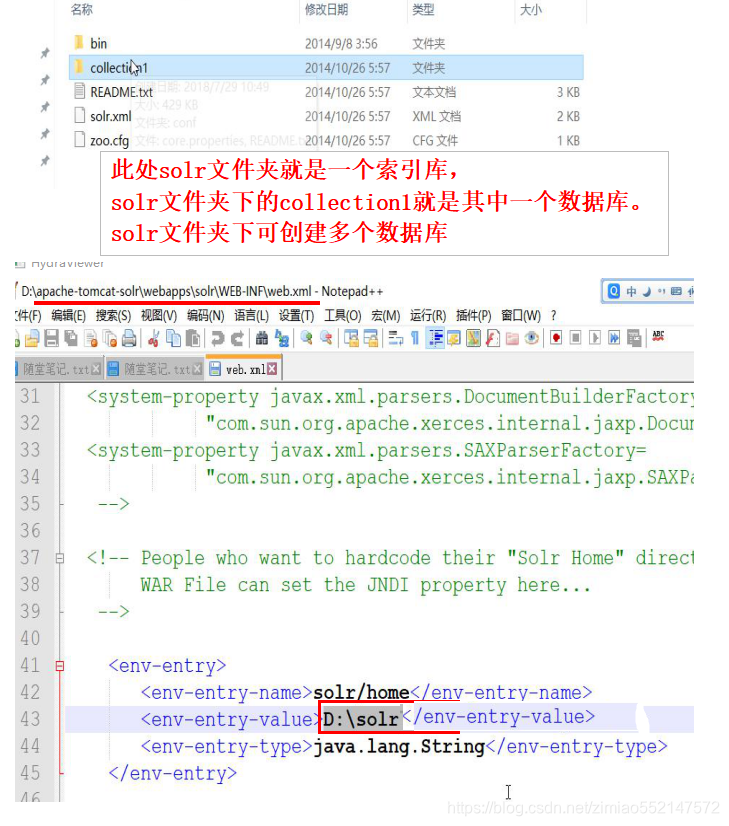
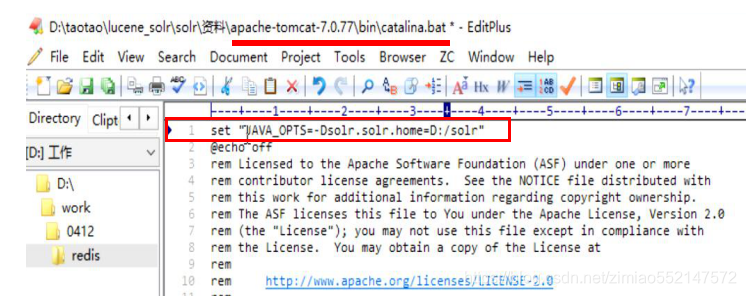
3.第三步:1.将“\solr-4.10.2\example”目录下的(索引库)“solr”文件夹 拷贝到 不带中文/空格的目录下。比如说拷贝到“E:\solr”(索引库)。2.到“\apache-tomcat-8.5.16\bin”目录下,编辑“catalina.bat”文件。在“catalina.bat”文件中的第一行处添加一条配置信息,用于指向我们的索引库及配置目录:set "JAVA_OPTS=-Dsolr.solr.home=E:/solr"
3.到“\apache-tomcat-8.5.16\webapps\solr\WEB-INF”下 编辑“web.xml”文件,编辑如下:
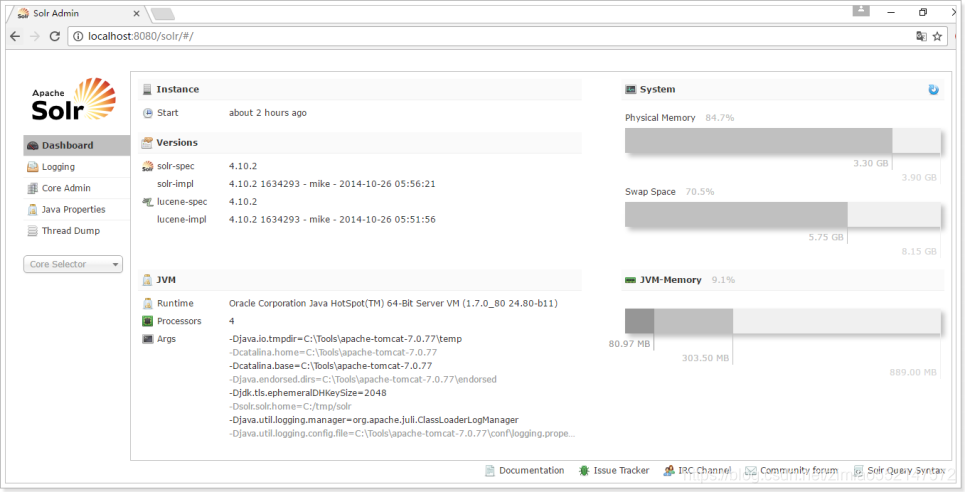
4.第四步:1.运行\apache-tomcat-8.5.16\bin目录下的“startup.bat”2.打开浏览器,访问 http://localhost:8080/solr 进入Solr管理页面
Solr的教学文档
2.1、启动Solr服务的方式
2.1.1、方式一,Jetty服务器启动Solr(了解)
步骤:
1)进入solr-4.10.2/example目录
2)打开命令行,执行java –jar start.jar命令,即可启动Solr服务
3)打开浏览器,通过http://localhost:8983/solr来访问Solr管理页面。(Jetty服务的默认端口是8983)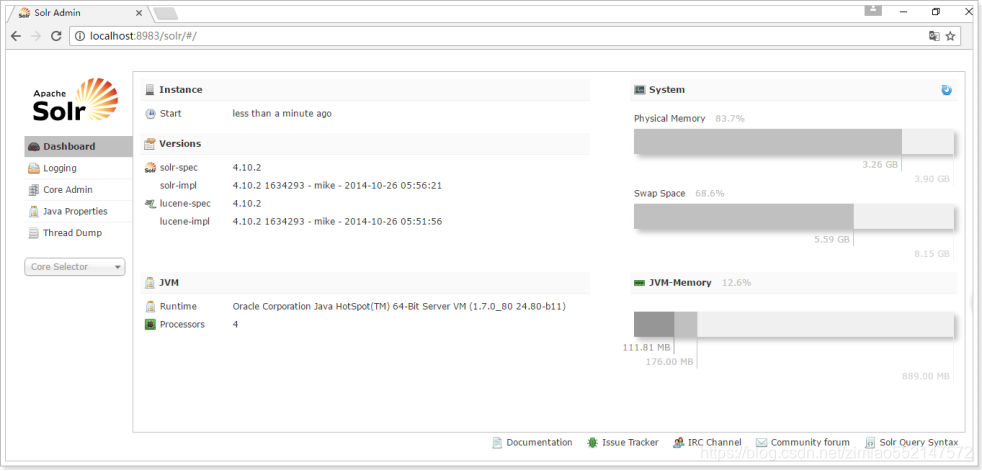
2.1.2、方式二,Tomcat服务器启动
步骤:
1)部署Web服务,将solr-4.10.2/example/webapps/solr.war复制到自己的tomcat/webapps目录中,并解压,然后删除solr.war文件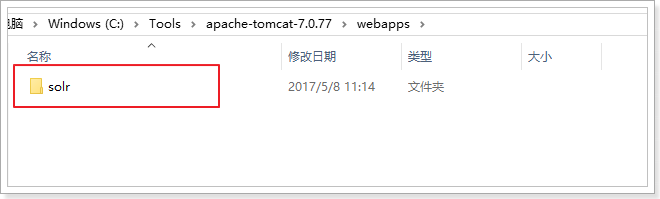
2)在Tomcat中加入相关jar包:将“resource\solr在tomcat运行需要导入的jar包\lib”下的jar包复制tomcat/webapps/solr/WEB-INF/lib下。
并且把class/log4j.properties复制到tomcat/webapps/solr/WEB-INF下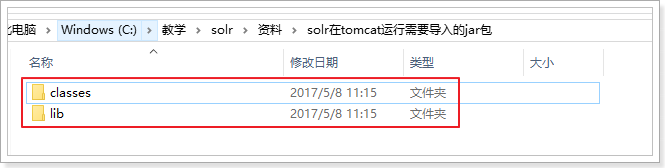
3)修改Tomcat配置文件,指向Solr的索引库及配置目录。
注意,这里可以指向solr-4.10.2/example/solr目录,如果想独立出来,也可以将这个solr文件夹复制出来到任意位置(不要出现中文),例如:例如:C:/tmp/solr我们这里就把这个文件夹复制出来,独立使用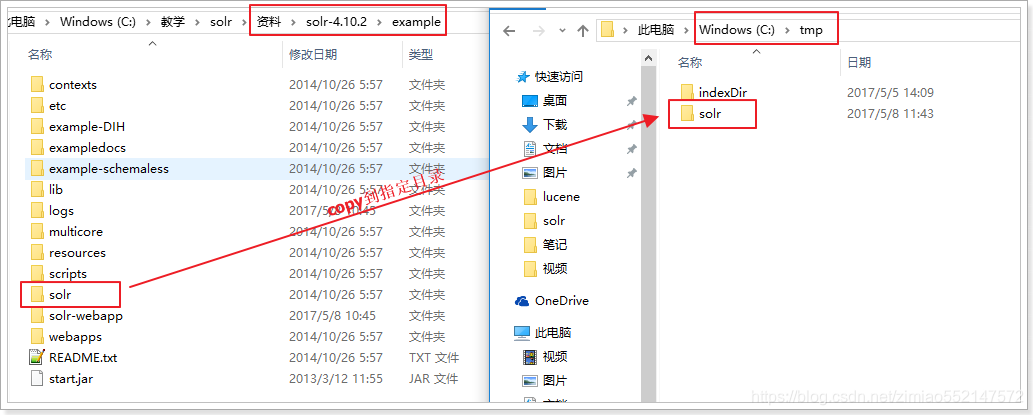
进入Tomcat文件夹,用记事本打开:tomcat/bin/catalina.bat文件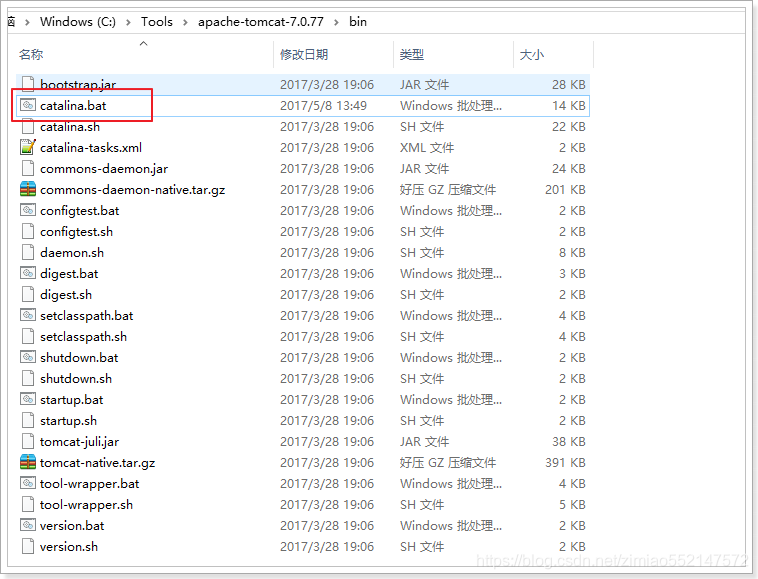
添加一条配置信息,指向我们的索引库及配置目录:set "JAVA_OPTS=-Dsolr.solr.home=C:/tmp/solr"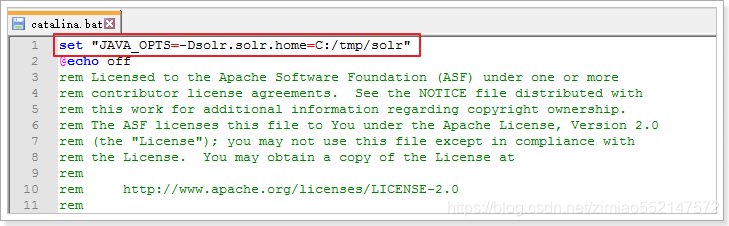
4)进入tomcat/bin目录,双击 startup.bat文件启动服务器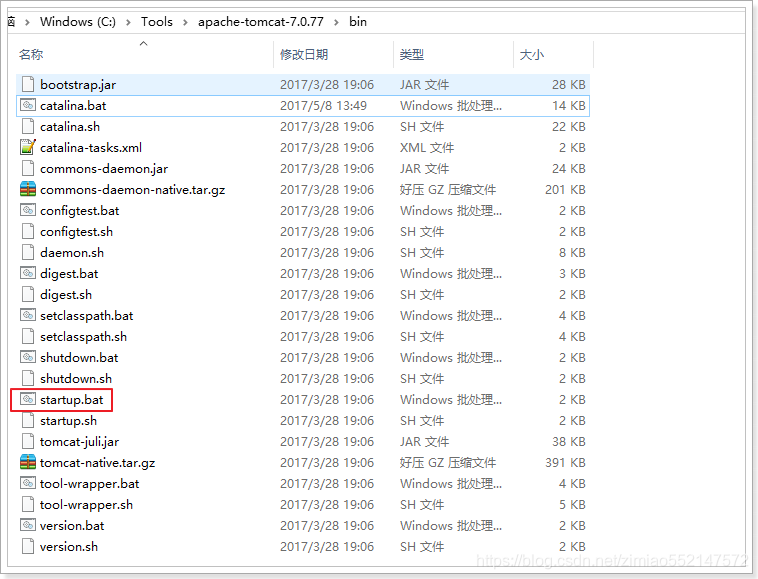
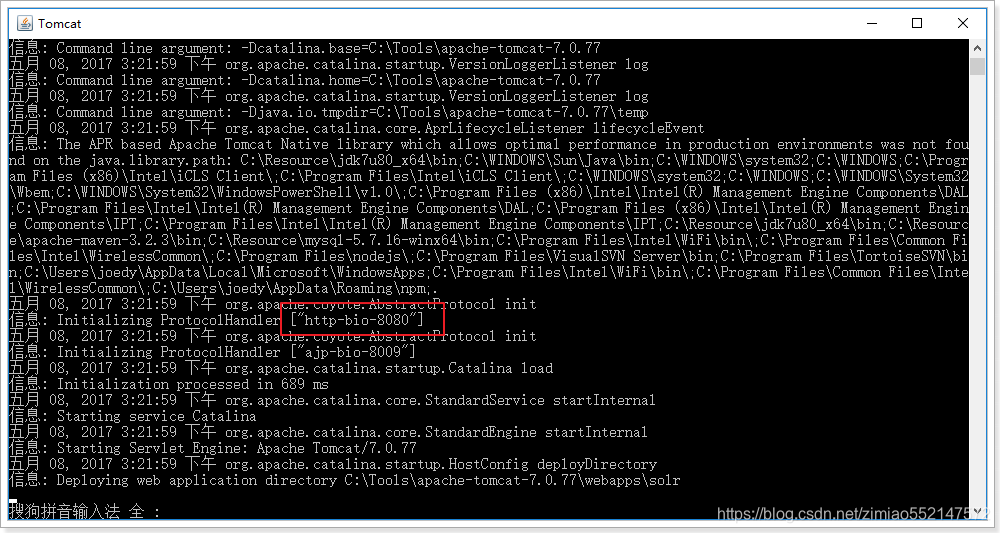
5)打开浏览器,访问 http://localhost:8080/solr 进入Solr管理页面
第一种启动方式:java -jar start.jar
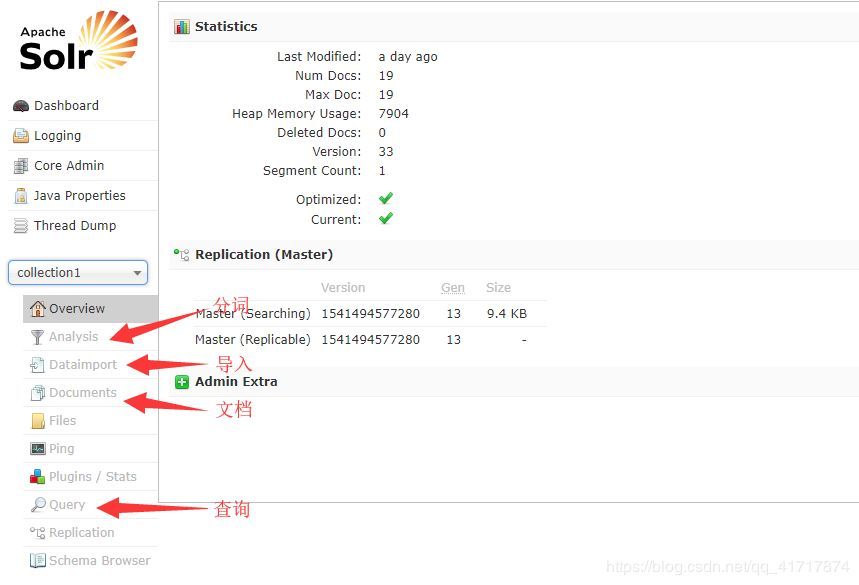
Solr的管理页面
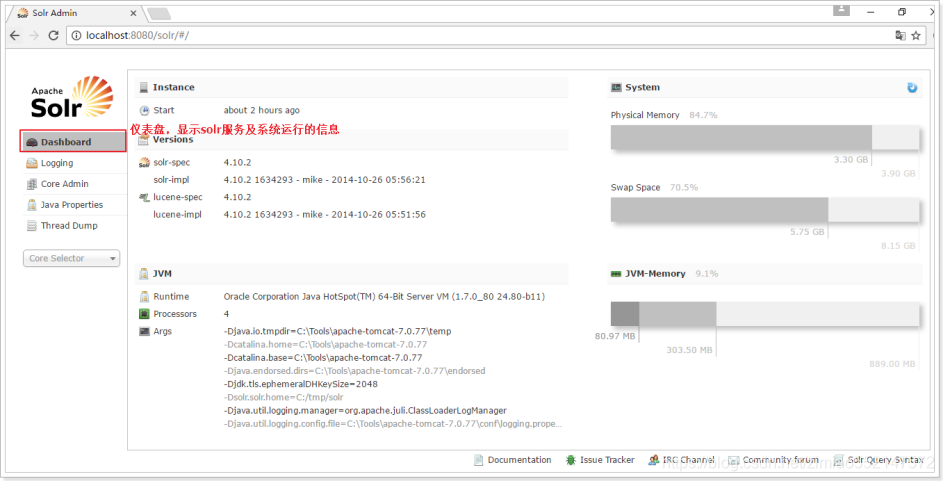
面板(仪表盘)
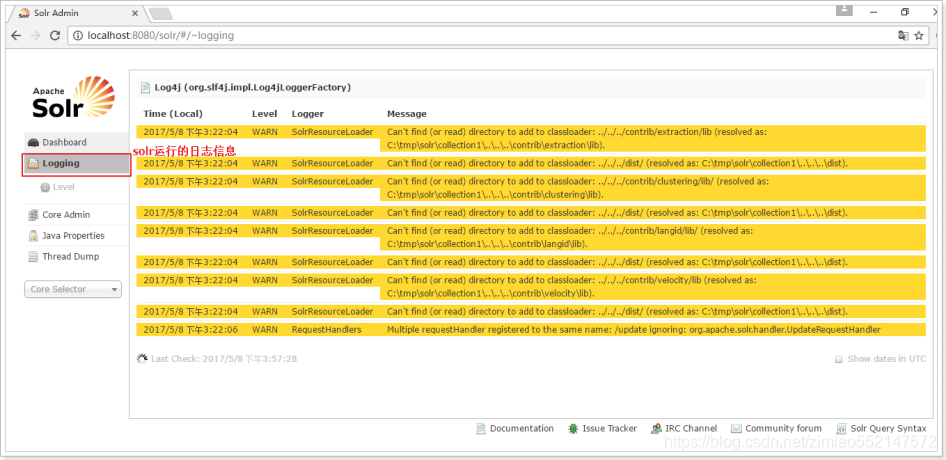
日志(日志)
核心管理员(核心管理)
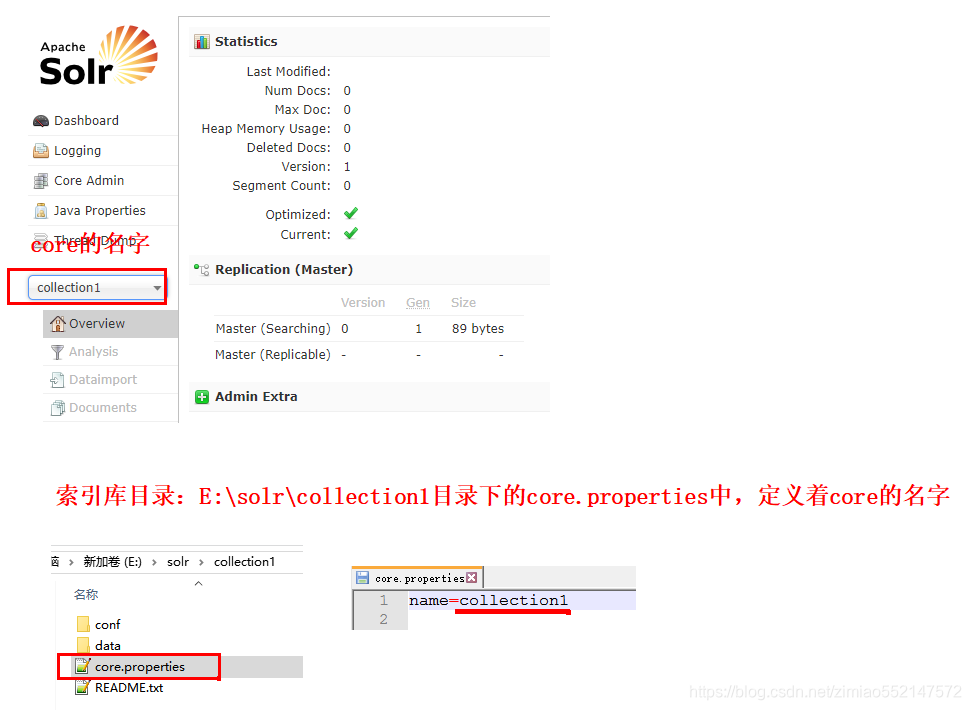
在Solr中,每一个Core,代表一个索引库,里面包含索引数据及其配置信息。 Solr中可以拥有多个Core,也就同时管理多个索引库!就像在MySQL中可以有多个database一样!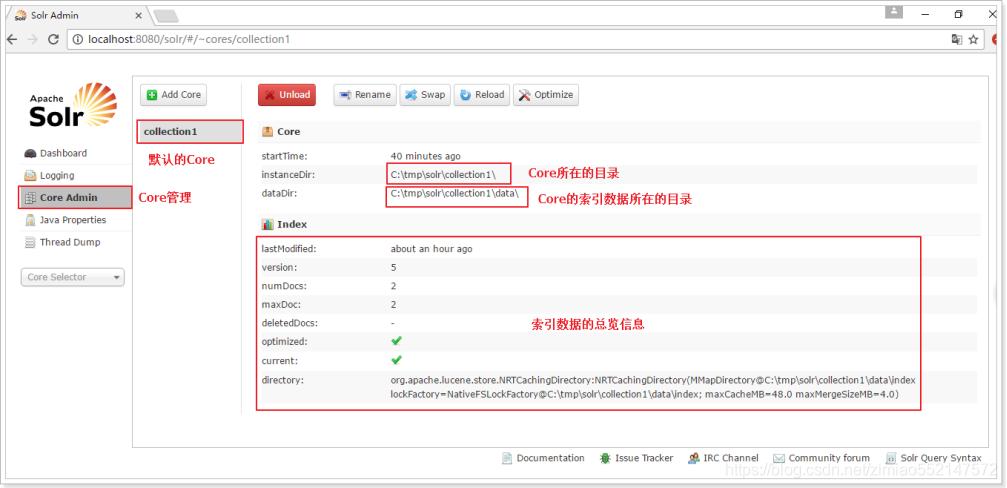
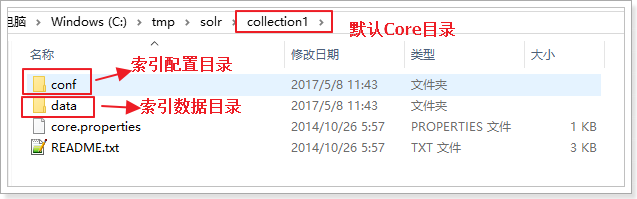
默认核心的目录

JavaProperties和ThreadDump
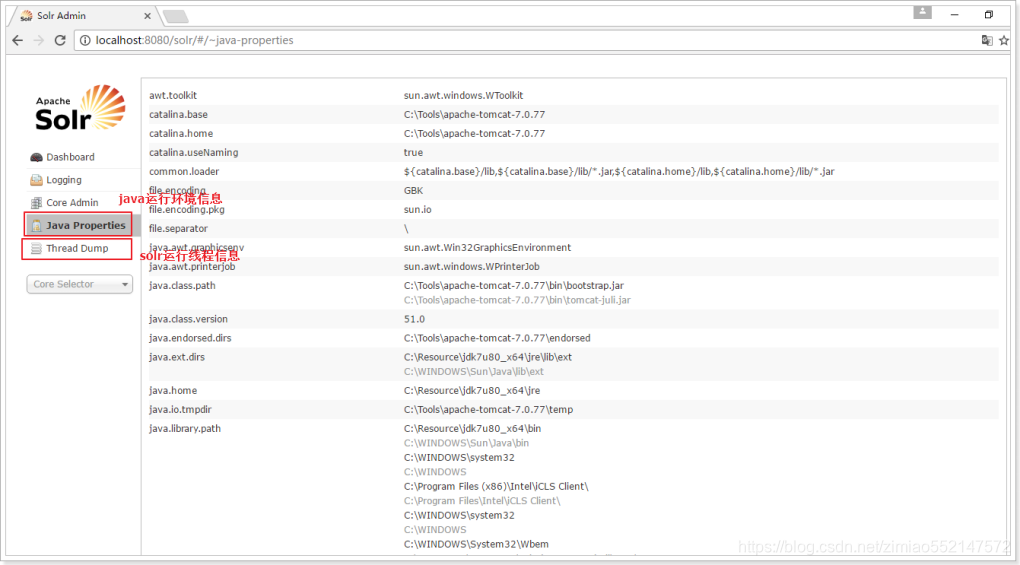
管理索引库的控制台
CoreSelector(核心选择器)
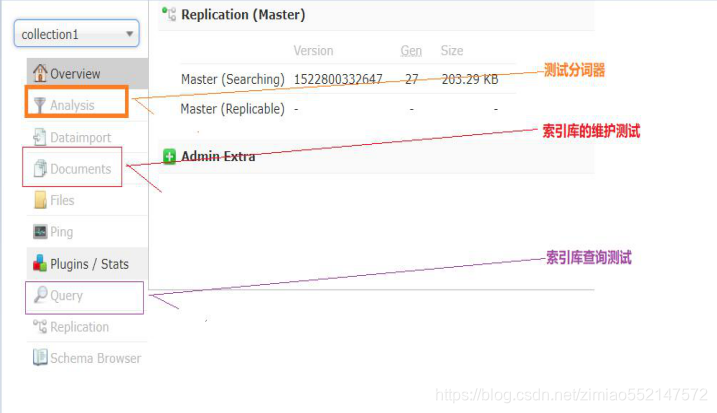

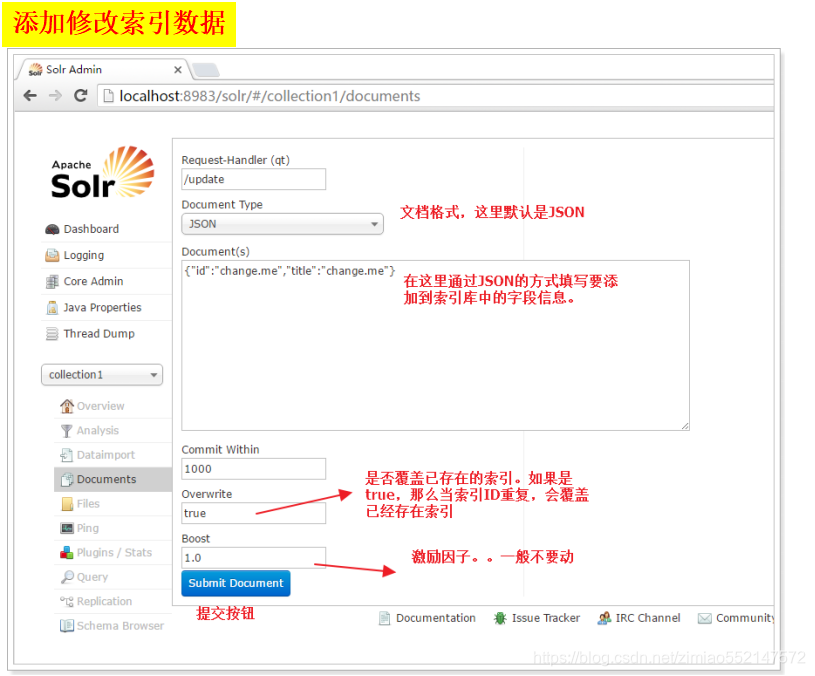
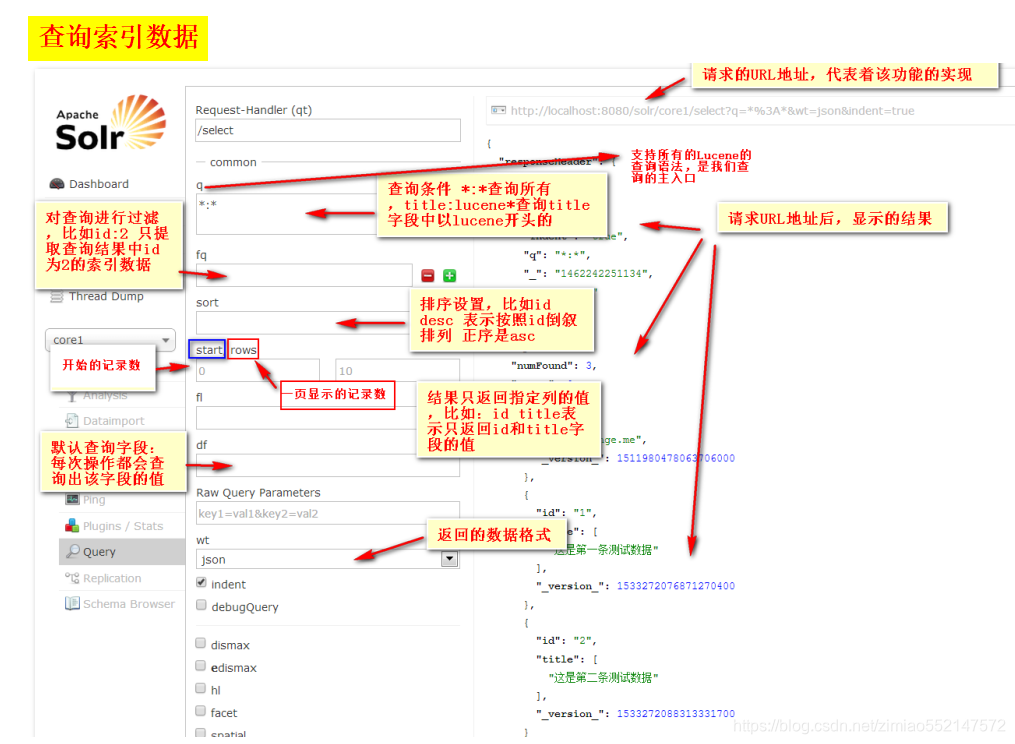
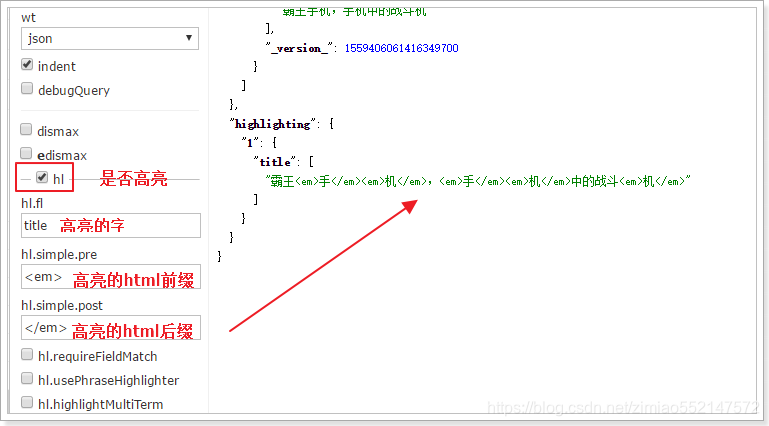
核心的配置文件详解
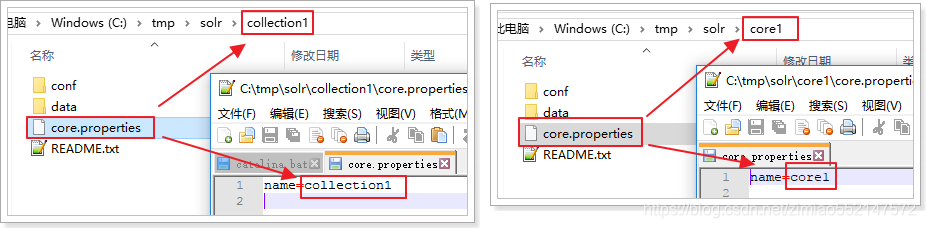
1.Core的配置文件详解:1.core.properties2.schemal.xml3.solrconfig.xml2.core.properties 的作用:Core的属性文件,记录当前core的名称、索引位置、配置文件名称等信息,也可以不写。一般要求Core名称跟Core的文件夹名称一致!这里都是collection1,我们可以手动修改这个属性,把Core的名字改成我们喜欢的。
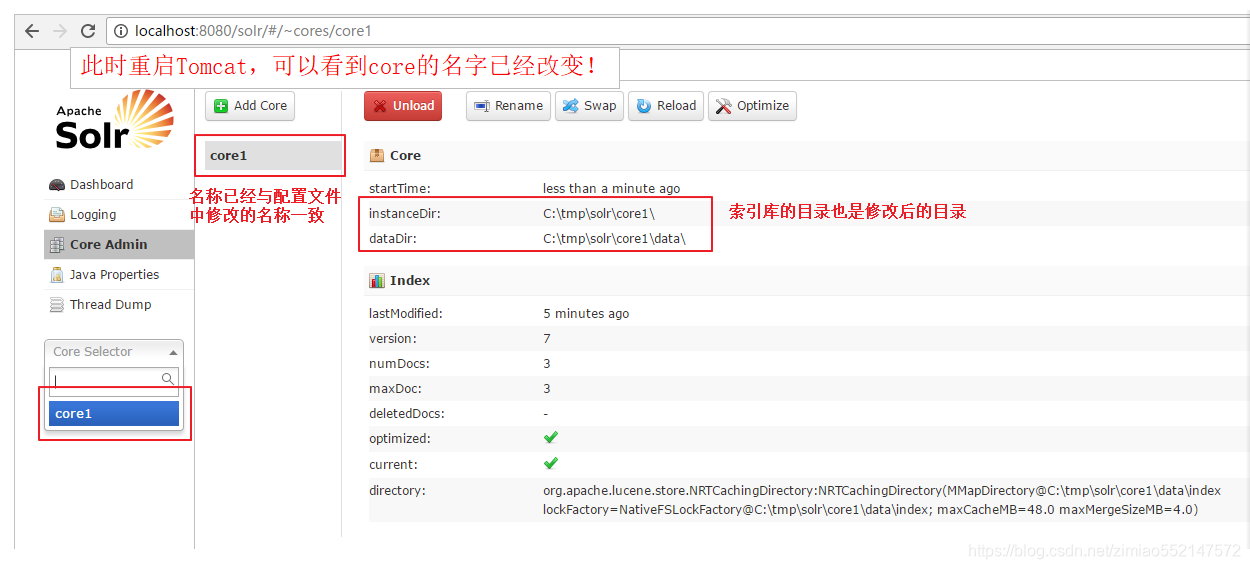
添加多个核心
1.在solr的目录下创建新的文件夹的Core2,作为新的核心目录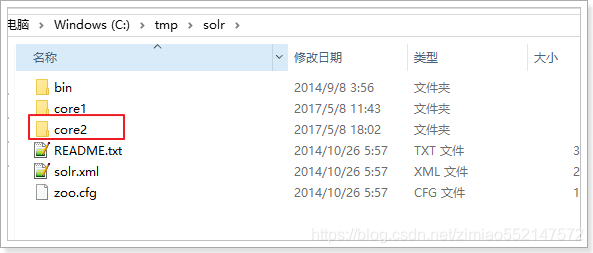
2)在核2下创建的conf目录和数据目录,并且创建文件core.properties,添加属性:名称= core2的
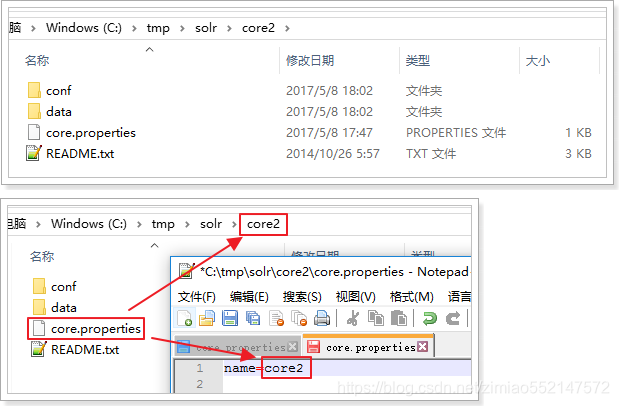
3)从核心-1 / CONF目录下复制配置文件的Core2 / CONF /下
4)重启的Tomcat,访问管理页面
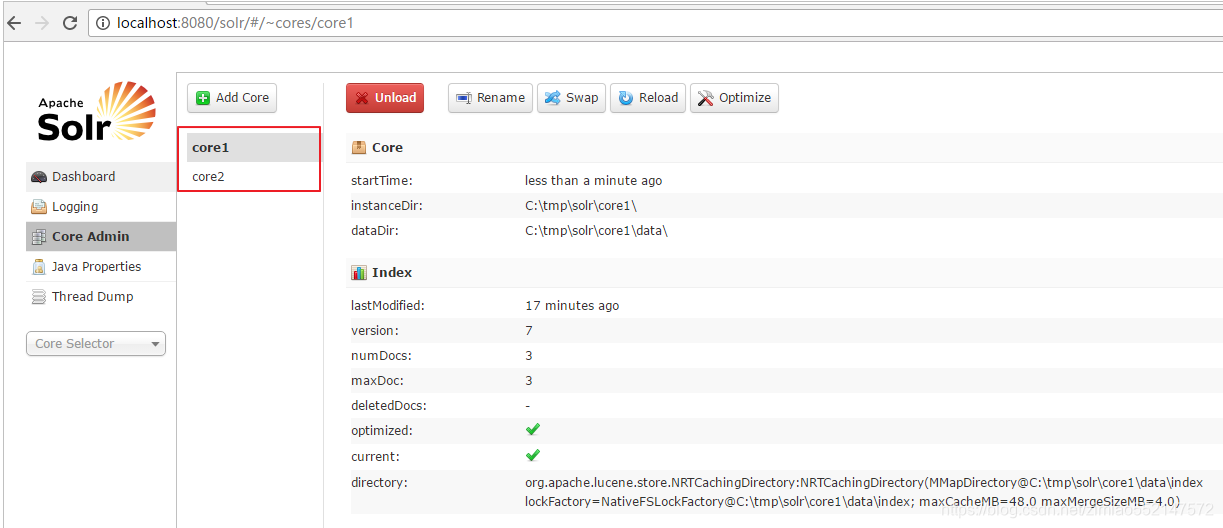
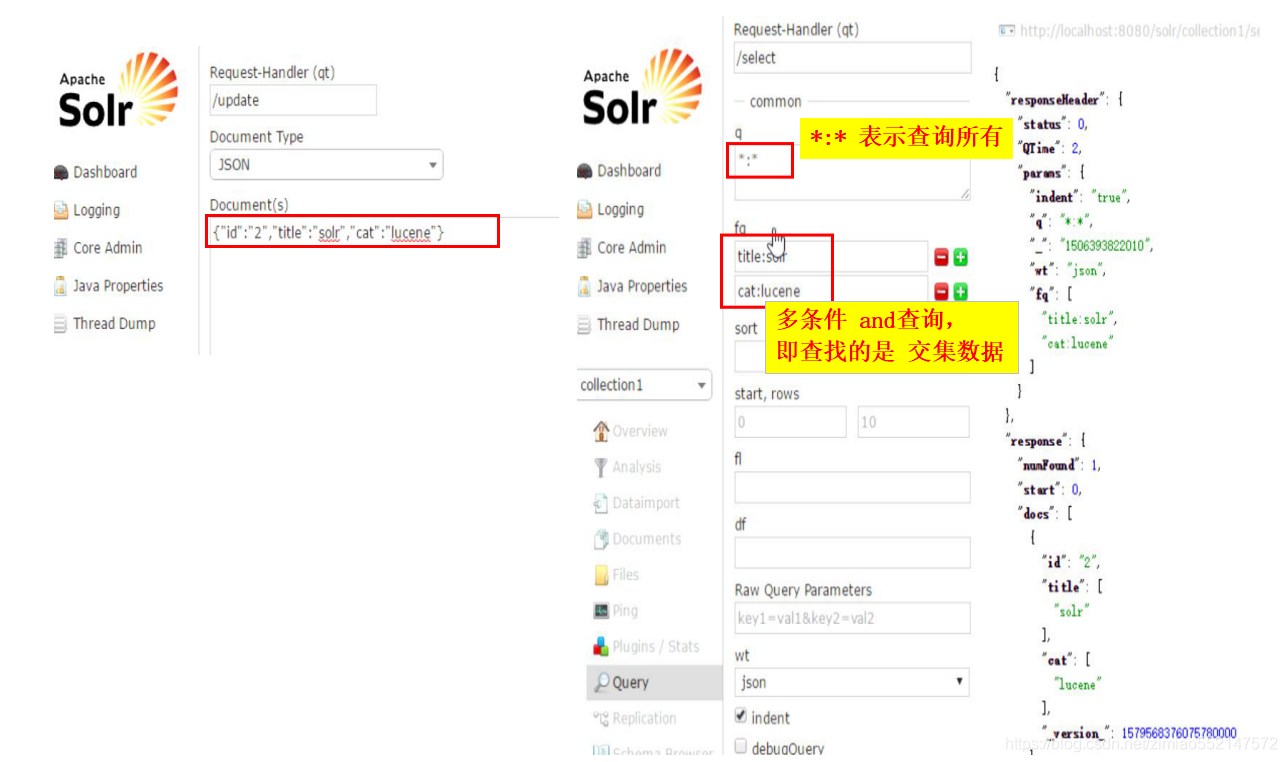
schema.xml中配置详解
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5"><!-- "_version_" 和 "_root_" 不能删--> <field name="_version_" type="long" indexed="true" stored="true"/><field name="_root_" type="string" indexed="true" stored="false"/><!-- 唯一键id:必须是 type="string"。indexed="true" 创建索引。stored="true" 存储。multiValued="false" 该字段不能有多个值。 --> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="age" type="long" indexed="true" stored="true"/><field name="name" type="string" indexed="true" stored="true"/><!-- 使用IK分词器(中文分词器):type="text_ik" 关联 <fieldType name="text_ik" >--> <field name="title" type="text_ik" indexed="true" stored="true"/><!--"text"字段是solrconfig.xml中默认定义的默认搜索字段,由solrconfig.xml中的这一句话来定义:<str name="df">text</str>。如果删除不使用"text"字段的话,那么也必须修改solrconfig.xml的默认搜索字段。 --><field name="text" type="text_ik" indexed="true" stored="true" multiValued="true"/><!-- 当新插入的字段名 并没有在schema.xml所定义的话,但只要符合以下规则,照样可以保存该字段名和字段值数据:新插入字段名的末尾字符 符合“<dynamicField name=“*_s”>规定的”后缀名/末尾字符 为“_s”的话,那么就能动态插入该字段名和字段值数据。 --> <dynamicField name="*_s" type="string" indexed="true" stored="true" /><!-- 唯一主键 --> <uniqueKey>id</uniqueKey><!--1.<copyField source=“普通字段名” dest=“复制域字段名text”>:表示把普通字段名 关联到 复制域字段“text”中。2.此处表示把"title"字段 和 "name"字段 关联到"text"字段,那么当查询时,默认把 "title"字段的值 和 "name"字段的值 赋值给"text"字段。3.当不指定查询字段时,默认查询"text"字段,也即相当于查询"text"字段所关联的 "title"字段的值 和 "name"字段的值 --><copyField source="title" dest="text"/><copyField source="name" dest="text"/><fieldType name="string" class="solr.StrField" sortMissingLast="true" /><fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/> <!-- 定义了IK中文分词器,那么只要有字段中使用type="text_ik" 关联 <fieldType name="text_ik" >,那么该字段既可以进行中文分词 --> <fieldType name="text_ik" class="solr.TextField"><analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/></fieldType>
</schema>Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,
例如:字段数据类型、字段是否索引、是否存储、是否分词等等。1.通过Field字段定义字段的属性信息:
1.属性及含义:name:字段名称,最好以下划线或者字母开头type:字段类型,指向的是本文件中的<fieldType>标签indexed:是否创建索引stored:是否被存储multiValued:是否可以有多个值,如果字段可以有多个值,设置为true2.注意:在本文件中,有两个字段是Solr自带的字段,绝对不要删除:_version_节点和_root_节点
2)通过FieldType指定数据类型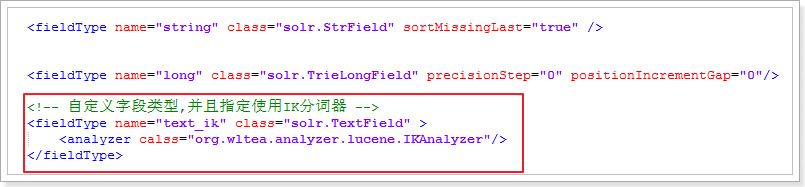
1.<fieldType name="" class="">1.name:字段类型的名称,可以是系统定义的数据类型,也可以是自定义的类型。<field type="">标签的type属性则负责引用<fieldType name="">中的name值,用于来指定数据类型或自定义的类型。2.class:字段类型在Solr中的类。class="solr.StrField":字段自动创建索引,但不会进行分词。class="solr.TextField":字段自动创建索引,并且自动进行分词,因此必须指定分词器,比如中文分词器(IK分词器)。2.<analyzer>:在<fieldType>标签体中 使用 <analyzer>子标签 用来指定分词器,比如中文分词器(IK分词器)。3)唯一主键Lucene中本来是没有主键的。删除和修改都需要根据词条进行匹配。而Solr却可以设置一个字段为唯一主键,这样删改操作都可以根据主键来进行!
4)动态字段
Solr的中的修改:本质是先删除,再插入新的数据
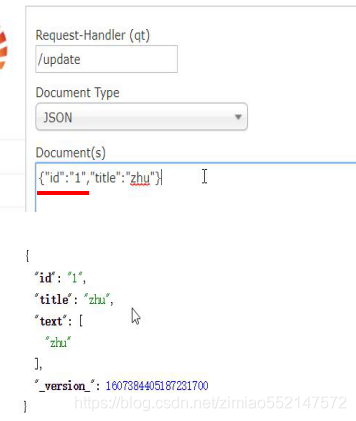
动态域(动态产生域):动态插入字段名和字段值

动态插入字段名和字段值的规则:只要插入字段名的末尾字符 符合“<dynamicField name=“*_s”>规定的”后缀名/末尾字符为_s的话,那么就能动态插入字段名和字段值。

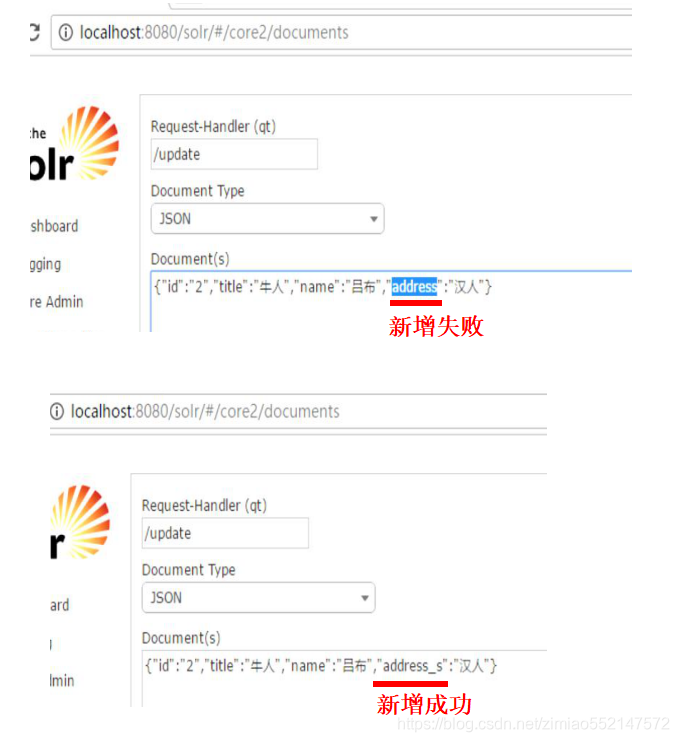
复制域:“文本”字段

复制域的用法:1.首先在schema.xml中配置把其他字段关联到“text”字段。2.上图分别有两个普通字段<field name=“字段名name”>、<field name=“字段名title”>, 和 一个复制域字段<field name=“复制域字段名text”>;使用<copyField source=“普通字段名” dest=“复制域字段名text”>:表示把普通字段名 关联到 复制域字段“text”中。3.作用:1.普通字段名 关联到 复制域字段“text”之后,便能自动把所关联的普通字段的值 赋值给 复制域字段“text”中。2.在查询时不指定要查询的具体字段的话,默认使用复制域字段“text”来作为查询字段,因为在\solr\collection1\conf\solrconfig.xml中配置了<str name="df">text</str>。因为会自动把所关联的普通字段的值 赋值给 复制域字段“text”,所以当默认使用复制域字段“text”来作为查询字段进行查询时,相当于查询复制域字段“text”所关联的普通字段的值。
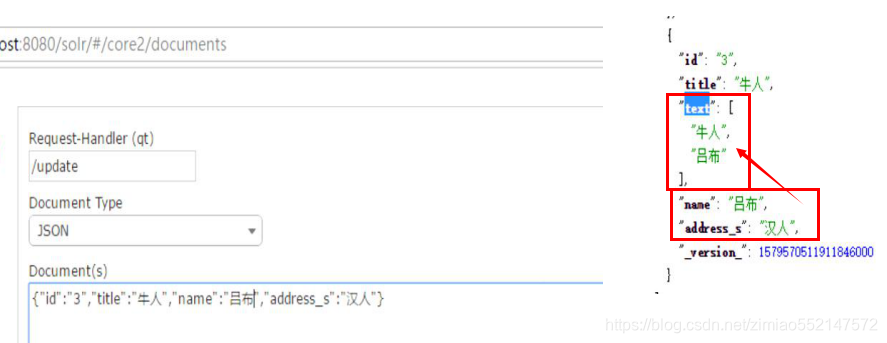
在插入数据时无需给“text”字段插入数据,而在查询时,自动把“title”和“name”的数据作为“text”字段的数据。
因为schema.xml中配置了“text”字段指定关联了“title”和“name”字段。

IK分词器(中文分词器)
1.引入IK分词器的jar包<!-- 引入IK分词器 --><dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version></dependency>2.下面三个配置文件 拷贝到 Tomcat根目录下的\webapps\solr\WEB-INF\classes 文件中
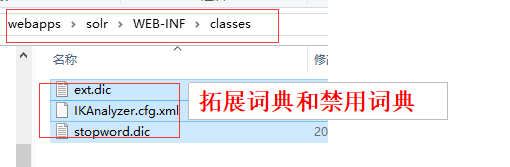
3.在schemal.xml中自定义fieldType,引入IK分词器
<fieldType name="text_ik" class="solr.TextField"><analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/></fieldType>4.让字段使用我们的自定义数据类型,引入IK分词器
5.可以正确分词了: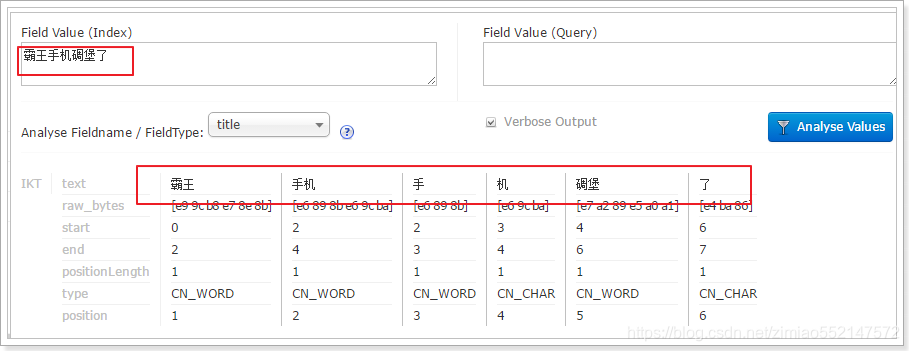
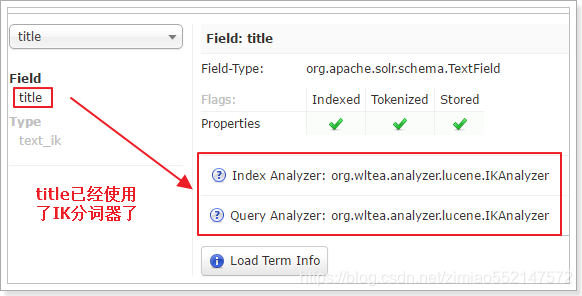
自定义字段的数据类型:定义有IK分词器(中文分词器)

<field type="text_ik">标签的type属性则负责引用<fieldType name="text_ik">中的name值,用于来指定数据类型或自定义的类型。
该字段使用到“带有IK分词器的”字段类型,那么该字段“title”就能分词了。
如果字段不使用“带有IK分词器的”字段类型,而使用string类型声明(type=string)的话,是无法中文分词的。
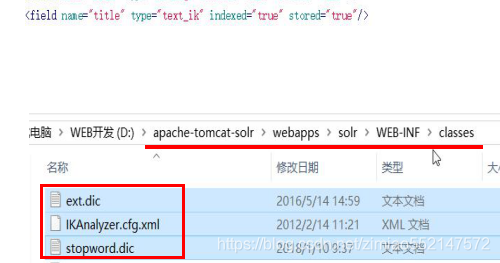
solrconfig.xml中
这个配置文件主要配置跟索引库和请求处理相关的配置。
solr服务的优化主要通过这个配置文件进行。
<LIB />标签
1.用途:配置插件依赖的jar包
2.注意事项:如果引入多个jar包,要注意包和包的依赖关系,被依赖的包配置在前面这里的jar包目录如果是相对路径,那么是相对于core所在目录。3.例如 在配置文件中默认有以下配置:这些是Solr中插件所依赖的Jar包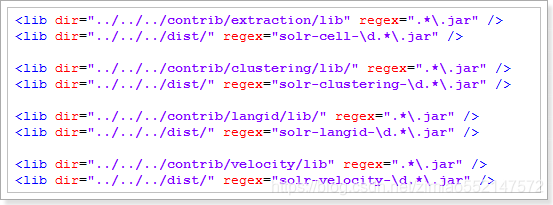
4.这里的相对路径其实是相对于 core所在目录。我们把所引来的Jar包复制到solr的HOME中: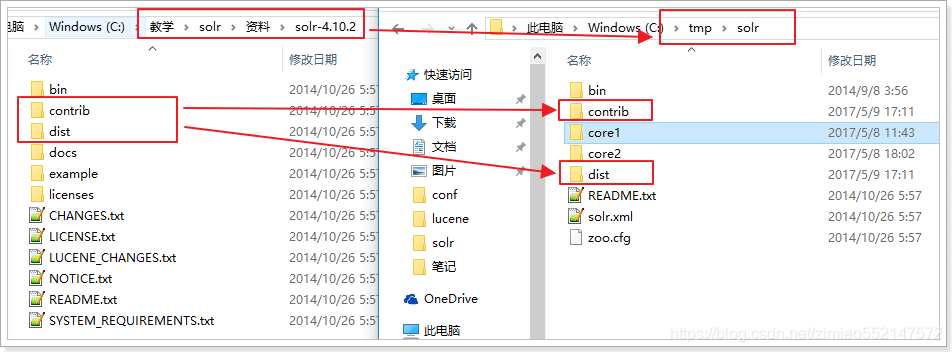
然后修改配置文件: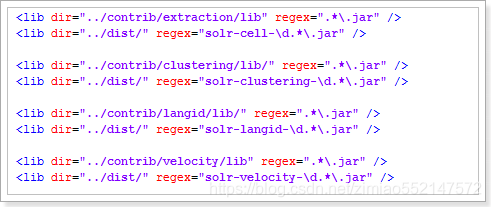
效果:
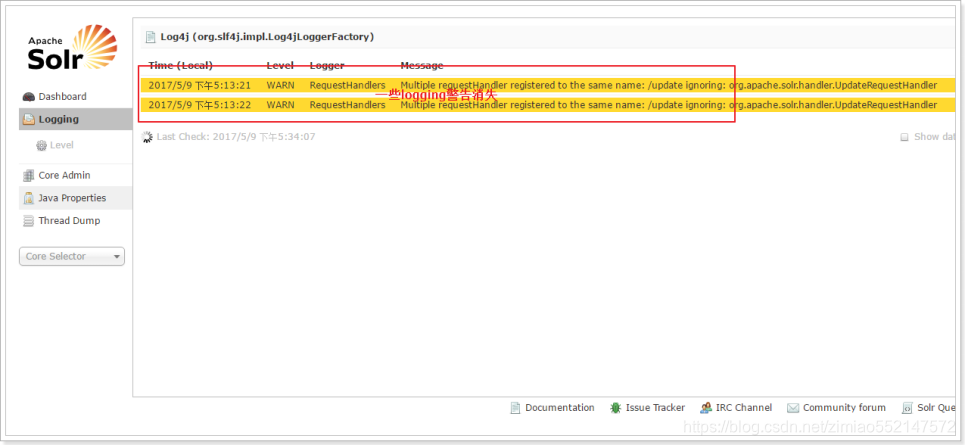
处理日志中的警告信息
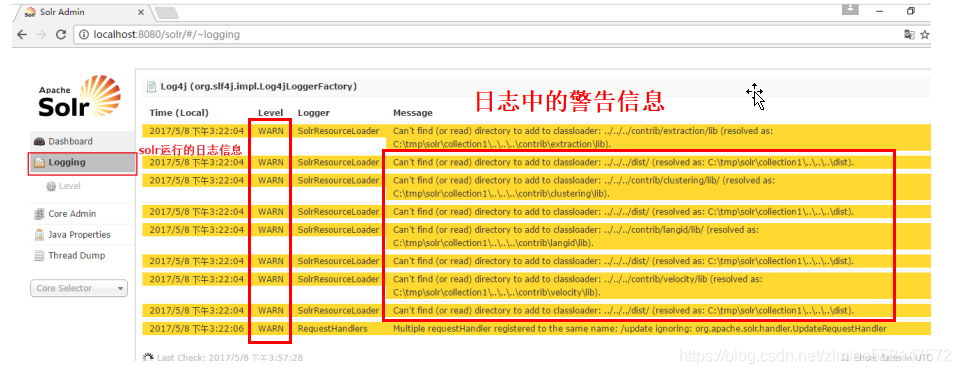
该警告信息:表示索引库目录(E:\solr\collection1\conf)下找不到contrib和dist文件夹。
解决:1.第一步:把“\solr-4.10.2”目录下的contrib和dist文件夹 拷贝到 索引库目录(E:\solr\collection1\conf)下即可。2.第二步:修改“E:\solr\collection1\conf”下的solrconfig.xml文件:将“../../../”修改为“../”。
索引库目录:E:\ Solr的\ collection1 \的conf目录下的solrconfig.xml中
修改“E:\ Solr的\ collection1 \的conf”下的solrconfig.xml中文件:将“../../../”修改为“../”
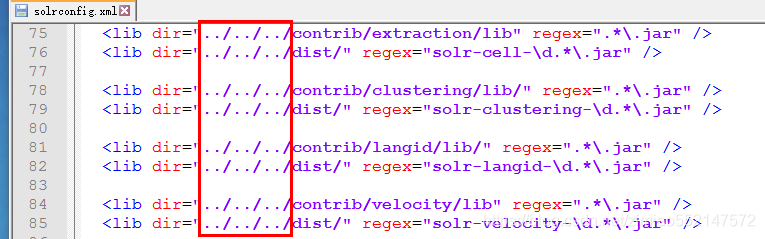
最终修改为“../”

1.到\apache-tomcat-8.5.16\bin目录下,先执行“shutdown.bat”停止Tomcat,再执行“startup.bat”启动Tomcat
2.打开浏览器,访问 http://localhost:8080/solr 进入Solr管理页面

<requestHandler />标签
1.用途:配置Solr处理各种请求(搜索/select、更新索引/update、等)的各种参数
2.主要参数:name:请求类型,例如:select、query、get、updateclass:处理请求的类initParams:可选。引用<initParams>标签中的配置<lst name="defaults">:定义各种缺省的配置,比如缺省的parser、缺省返回条数3.例子:负责搜索请求的Handler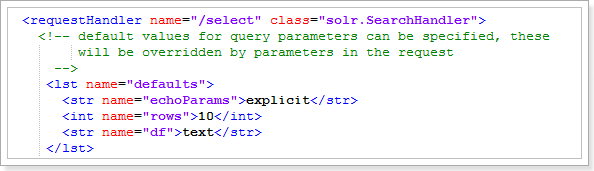
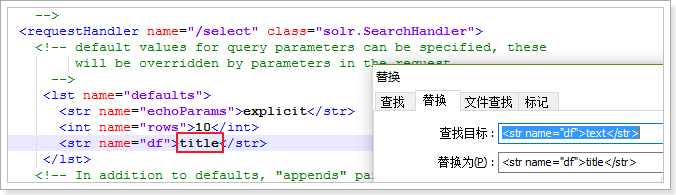
1.<int name="rows">10</int>:不进行分页查询的话,默认只查询出10条数据2.<str name="df">text</str>:1.在查询时不指定要查询的具体字段的话,默认使用复制域字段“text”来作为查询字段,因为会自动把所关联的普通字段的值 赋值给 复制域字段“text”,所以当默认使用复制域字段“text”来作为查询字段进行查询时,相当于查询复制域字段“text”所关联的普通字段的值。2.<str name="df">默认搜索的字段</str> 默认设置为:text。我们可以设置为title:
<initParams在/>标签
1.用途:为一些requestHandlers定义通用的配置,以便在一个地方修改后,所有地方都生效
2.主要参数:path:指明该配置应用于哪些请求路径,多个 的话用逗号分开,可以用通配符(*表示一层子路径,**表示无限层)name:如果不指定path,可以指定一个name,然后在<requestHander>配置中可以引用这个name
3.例子(配置一个缺省的df): <initParams path="/update/**,/query,/select,/tvrh,/elevate,/spell,/browse"> <lst name="defaults"> <str name="df">_text_</str> </lst> </initParams>如果配置name,在<requestHander>中引用的例子:<requestHandler name="/dump1" class="DumpRequestHandler" initParams="myParams"/>
<updateHandler />标签
1.用途:定义一些更新索引相关的参数,比如定义commit的时机
2.主要参数:autoCommit:定义自动commit的触发条件。如果没配置这个参数,则每次都必须手动commit
maxDocs
maxTime(毫秒)
penSearcher:autoCommit结束后,是否开启一个新的searcher让更改生效。缺省为falseautoSoftCommit:定义自动softCommit的触发条件。相关参数同autoCommitlistener:配置事件监听器
event:监听哪个事件,比如:event="postCommit", event="postOptimize"
class:处理的类,可以是自己的实现类。如果是RunExecutableListener,可以配置下面的参数:
exe:可执行文件,包括Solr Home的相对路径和文件名
dir:工作目录,缺省是“.”
wait: 调用者是否等待可执行文件执行结束,缺省是true
args:传递给可执行文件的参数
env:其他所需要的环境变量updateLog:配置log的保存路径、等
dir:保存路径
numRecordsToKeep:一个log保存的记录数,缺省为100
maxNumLogsToKeep:log的数量,缺省为10
numversionBuckets:追踪max version的bucket数量(?),缺省为65535配置这些参数要考虑到搜索的准确度和性能的平衡。^_^注:commit和softCommit:
commit:正式提交、对索引的修改会被保存到永久存储中(比如磁盘),会比较耗时
softCommit:软提交,对索引的修改会被立即应用到工作中的索引中,即立即生效,但没有保存进磁盘
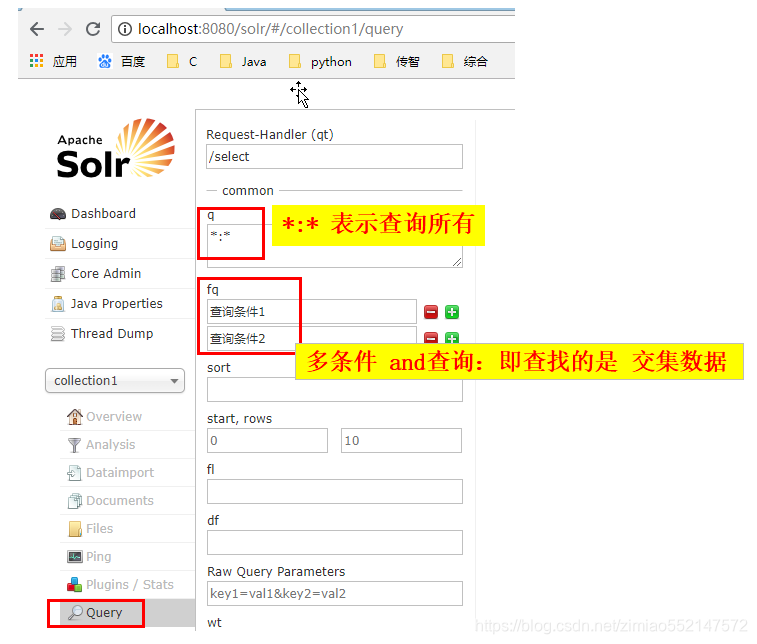
<查询/>标签
1.用途:配置Solr如何处理和返回搜索的相关参数
2.主要参数:filterCache:当搜索带有“fq”参数时,使用这个配置,它保存未经过排序的所有文档
class:实现类,有三种:solr.search.LRUCache, solr.search.FastLRUCache, solr.search.LFUCache
size:最大保存的记录数量
initialSize:初始数量
autowarmCount:新Index Searcher启动的时候从旧的Index Searcher缓存拷贝过来的数据量queryResultCache:存储最终的搜索结果(排序后的、有范围的文档id)
class:实现类,有三种:solr.search.LRUCache, solr.search.FastLRUCache, solr.search.LFUCache
size:最大保存的记录数量
initialSize:初始数量
autowarmCount:新Index Searcher启动的时候从旧的Index Searcher缓存拷贝过来的数据量
maxRamMB:最大分配的容量(兆)documentCache:缓存Lucene Document对象(就是每个文档的fields)
class:实现类,有三种:solr.search.LRUCache, solr.search.FastLRUCache, solr.search.LFUCache
size:最大保存的记录数量
initialSize:初始数量
autowarmCount:因为Lucene的内部文档 id 是临时的,所以这个缓存不应该被auto-warm,这个值应该为“0”cache:配置自定义的缓存,通过SolrIndexSearcher类的getCache()方法和name参数调用这个缓存
name:被调用时的标识
其他参数同上maxBooleanClauses:BooleanQuery的最大子句数量enableLazyFieldLoading:没有知道被请求的field是否懒加载,true/falseuseFilterForSortedQuery:如果不是按照score排序,是否从filterCache中获取数据queryResultWindowsize:配合queryResultCache使用,缓存一个超集。如果搜索请求第10到19条记录,而这个参数是50,那么会缓存0到49条记录queryResultMaxDocsCached:queryResultCache缓存的最大文档数量useColdSearcher:但一个新searcher正在warm-up的时候,新请求是使用旧是searcher(true)还是等待新的search(false)maxWarmingSearchers:定义同时在warn-up的searcher的最大数量listener:监听一些事件并指定处理的类,比如在solr启动时加载一些数据到缓存中,相关参数:
event:被监听的事件,比如:firstSearcher是第一个searcher启动、也就是solr启动的事件,newSearcher是当已经有searcher在运行的时候有新searcher启动的事件
class:处理类
name:="queries"就是需要处理的是query
lst, name:针对哪些搜索条件需要处理
<RequestDispatcher的/>标签
1.用途:控制Solr HTTP RequestDispatche r响应请求的方式,比如:是否处理/select url、是否支持对流的处理、上传文件的大小、如何处理带有cache头的HTTP请求、等等
2.主要参数:handleSelect:true/false,如果是false,则由requestHandler来处理/select请求。因为现在的requestHandler中/select是标配,所以这里应该填falserequestParsers:
enableRemoteStreaming:是否接受流格式的内容,缺省为ture
multipartUploadLimitInKB:multi-part POST请求,上传文件的大小上限(K)
formdataUploadLimitInKB:HTTP POST的form data大小上限(K)
addHttpRequestToContext:原始的HttpServletRequest对象是否应该被包含在SolrQueryRequest的httpRequest中……一般自定义的插件使用这个参数……httpCaching:如何处理带有cache control头的HTTP请求
nerver304:如果设为true(开发阶段),则就算所请求的内容没被修改,也不会返回304,并且下面两个参数会失效
lastModFrom:最后修改时间的计算方式,openTime:Searcher启动的时刻;dirLastMod:索引更新的时刻
etagSeed:HTTP返回的ETag头内容
cacheControl:HTTP返回的Cache-Control头内容
<updateProcessor />和<updateProcessorChain />标签
1.用途:配置处理update请求的处理器、处理器链。如果不配置的话,Solr会使用缺省的三个处理器:LogUpdateProcessorFactory:追踪和记录日志DistributedUpdateProcessorFactory:分流update请求到不同的node,比如SolrCloud的情况下把请求分配给一个shard的leader,然后把更新应用到所有replica中RunUpdateProcessorFactory:调用Solr的内部API执行update操作
2.如果需要自定义update处理器:updateProcessor:
class:负责处理的类
name:名字,给updateProcessorChain引用是使用updateProcessorChain:
name:自己的名字标记
processor:指定updateProcessor的name,多个的话用逗号“,”分开
SolrJ的使用(用于操作的Solr)
pom.xml中添加依赖:<dependencies><!-- Junit单元测试 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.apache.solr</groupId><artifactId>solr-solrj</artifactId><version>4.10.2</version></dependency><!-- Solr底层会使用到slf4j日志系统 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.22</version></dependency><dependency><groupId>commons-logging</groupId><artifactId>commons-logging</artifactId><version>1.2</version></dependency></dependencies><build><plugins><!-- java编译插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.2</version><configuration><source>1.7</source><target>1.7</target><encoding>UTF-8</encoding></configuration></plugin></plugins></build>
1.添加数据到solr中的某个core(数据库)中//当前处于java程序,solr core交由tomcat启动的solr服务器管理//solr对外提供接口,用户通过http请求调用接口,进行数据的CRUD@Testpublic void addDateToSolr() throws SolrServerException, IOException{// URL为http://localhost:8080/solr项目名/core的名字String url = "http://localhost:8080/solr/core2";//solrj连接对象:连接到solr中的某个core(数据库)中,然后可以往该core(数据库)中对数据进行增删查改HttpSolrServer server = new HttpSolrServer(url);//数据封装对象: SolrInputDocumentSolrInputDocument document = new SolrInputDocument();// 新增数据:SolrInputDocument数据封装对象 提供了addField("字段名称", "字段值")设置数据document.addField("id", 2);document.addField("name", "solr");document.addField("age", 27L);document.addField("title", "solr是独立的企业级搜索服务器");//第一种保存方式:单个SolrInputDocument 插入保存//server.add(document);//第二种保存方式:批量多个SolrInputDocument 插入保存List<SolrInputDocument> list = new ArrayList<SolrInputDocument>();list.add(document);//批量添加数据server.add(list);//提交数据server.commit();}2.使用javaBean向solr中的某个core(数据库)中添加数据//使用注解:先定义JavaBean对象中的字段 和 core(数据库)中的字段名 相关联public class User {//@Field("core中的字段名"):使用 @Field注解显示声明javaBean中属性所对应的solr中的core(数据库)中的字段名@Field("id")private String id;@Field("name")private String name;@Field("title")private String title;@Field("age")private Long age;}@Testpublic void addJavaBeanToSolrCore() throws IOException, SolrServerException{// URL为http://localhost:8080/solr项目名/core的名字String url = "http://localhost:8080/solr/core2";//solrj连接对象:连接到solr中的某个core(数据库)中,然后可以往该core(数据库)中对数据进行增删查改HttpSolrServer server = new HttpSolrServer(url);//同时新增多条数据,批量多条数据插入保存List<User> list = new ArrayList<User>();for(int i = 3;i<30;i++){User user = new User();user.setId(""+i);user.setName("程序员"+i+"号");user.setAge(Long.valueOf(""+i));user.setTitle("机智聪明勤奋工程师"+i);list.add(user);}//第一种保存方式:直接插入保存单个javaBean对象,添加单条数据//server.addBean(user);//第二种保存方式:批量插入保存多个javaBean对象,添加多条数据server.addBeans(list);//提交server.commit();}3.修改/更新solr中的某个core(数据库)中的数据//solr中并没有更新数据的方法,没有更新这个概念。//通过唯一字段来判断:schema.xml中定义了uniqueKey,uniqueKey就是唯一字段。//如果新增数据的唯一键已经存在,新增时会直接全覆盖,即存在的话便便先删除原来的数据再增加新的数据。//如果新增数据时唯一键不存在,直接新增。@Testpublic void updateSolrCore() throws IOException, SolrServerException{// URL为http://localhost:8080/solr项目名/core的名字String url = "http://localhost:8080/solr/core2";//solrj连接对象:连接到solr中的某个core(数据库)中,然后可以往该core(数据库)中对数据进行增删查改HttpSolrServer server = new HttpSolrServer(url);//使用JavaBean对象封装数据User user = new User();user.setId("7");user.setName("典韦");user.setTitle("勇战士典韦");//直接插入保存单个javaBean对象,添加单条数据server.addBean(user);server.commit();}4.删除solr中的某个core(数据库)中的数据//根据id删除对应的数据@Testpublic void deleteById() throws SolrServerException, IOException{// URL为http://localhost:8080/solr项目名/core的名字String url = "http://localhost:8080/solr/core2";//solrj连接对象:连接到solr中的某个core(数据库)中,然后可以往该core(数据库)中对数据进行增删查改HttpSolrServer server = new HttpSolrServer(url);//根据id删除对应的数据server.deleteById("2");server.commit();}//根据 集合中保存的多个id 同时删除多条数据@Testpublic void deleteByIds() throws SolrServerException, IOException{// URL为http://localhost:8080/solr项目名/core的名字String url = "http://localhost:8080/solr/core2";//solrj连接对象:连接到solr中的某个core(数据库)中,然后可以往该core(数据库)中对数据进行增删查改HttpSolrServer server = new HttpSolrServer(url);//根据id删除对应的数据List<String> ids = new ArrayList<String>();ids.add("1");ids.add("3");//根据 集合中保存的多个id 同时删除多条数据server.deleteById(ids);server.commit();}//根据查询条件删除@Testpublic void deleteByQuery() throws SolrServerException, IOException{// URL为http://localhost:8080/solr项目名/core的名字String url = "http://localhost:8080/solr/core2";//solrj连接对象:连接到solr中的某个core(数据库)中,然后可以往该core(数据库)中对数据进行增删查改HttpSolrServer server = new HttpSolrServer(url);//查询条件的格式:"*:*"。会删除所有数据,能够成功执行。安全越界,慎用。String query = "*:*"; //String query = "title:聪明"; //查询条件的格式:“字段名:字段值”//deleteByQuery(查询条件):根据指定的查询条件删除所有匹配的结果server.deleteByQuery(query);server.commit();}5.查询solr中的某个core(数据库)中的数据\solr\collection1\conf\solrconfig.xml中配置了如下信息:<lst name="defaults"><str name="echoParams">explicit</str><int name="rows">10</int>//不进行分页查询的话,默认只查询出10条数据<str name="df">text</str>//不写指定查询的字段名的话,则默认查询text字段的字段值数据,即查询符合该“text字段名=字段值”的数据</lst>//@Testpublic void searchSolrCore() throws SolrServerException{// URL为http://localhost:8080/solr项目名/core的名字String url = "http://localhost:8080/solr/core2";//solrj连接对象:连接到solr中的某个core(数据库)中,然后可以往该core(数据库)中对数据进行增删查改HttpSolrServer server = new HttpSolrServer(url);//-----------------------------------------//1.new SolrQuery("*:*"):查询该core(数据库)中的所有//2.new SolrQuery("字段名:字段值"):指定查询符合该“字段名=字段值”的数据//3.new SolrQuery("字段值"):不写指定查询的字段名的话,则默认查询text字段的字段值数据,即查询符合该“text字段名=字段值”的数据。SolrQuery query = new SolrQuery("*:*");//4.new SolrQuery("字段名:字段值?"):表示匹配出现的位置//5.new SolrQuery("字段名:字段值*"):表示匹配任意字符SolrQuery query = new SolrQuery("title:互*");//布尔搜索:AND、OR和NOT布尔操作(推荐使用大写,区分普通字段)//例子:new SolrQuery("字段名:字段值 OR 字段名:字段值")。//使用OR表示:表示并集,符合任意一个"字段名:字段值"的数据 都能查询出来//使用AND表示:表示交集,符合两方的"字段名:字段值"的数据 才能查询出来SolrQuery query = new SolrQuery("title:solr OR title:iphone");//子表达式查询:(字段名:字段值 OR 字段名:字段值) OR (字段名:字段值)SolrQuery query = new SolrQuery("(title:solr OR title:聪明) OR (title:iphone)");//相似度搜索:使用“~”字符,表示最大允许编辑次数为2次//core数据库中存储的是“iphone”,那么输入要搜索的"iphon~q",编辑两次后,仍然可以得到“iphone” SolrQuery query = new SolrQuery("iphon~q");//数字范围搜索,包含起始值和结束值:"字段名:[字段值 TO 字段值]"。//[字段值 TO 字段值]:表示包含两边字段值//{字段值 TO 字段值}:表示不包含两边字段值SolrQuery query = new SolrQuery("age:[1 TO 5]");//-----------------------------------------//根据id字段倒叙排列query.setSort("id", ORDER.desc);//-----------------------------------------//执行查询,获取出查询结果集QueryResponse response = server.query(query);//---------------- 解析查询结果集的方式一 -------------------------SolrDocumentList list = response.getResults(); //默认只查询出10条数据:因为\solr\collection1\conf\solrconfig.xml中配置了<int name="rows">10</int>//不进行分页查询的话,默认只查询出10条数据for(SolrDocument sd : list){System.out.println("id===="+sd.get("id"));System.out.println("name===="+sd.get("name"));System.out.println("title===="+sd.get("title"));System.out.println("===========next===========");}//---------------- 解析查询结果集的方式二 -------------------------//解析搜索结果集的方式二:// 直接返回javaBean的方式。// JavaBean类中的字段上必须定义有@Field("core中的字段名")List<User> list = response.getBeans(User.class);for(User u : list){System.out.println(u);}}6.分页查询:\solr\collection1\conf\solrconfig.xml中配置了如下信息:<lst name="defaults"><str name="echoParams">explicit</str><int name="rows">10</int>//不进行分页查询的话,默认只查询出10条数据<str name="df">text</str>//不写指定查询的字段名的话,则默认查询text字段的字段值数据,即查询符合该“text字段名=字段值”的数据</lst>//搜索结果集的分页// 分页关键:需要页码和每页显示条数// 获取结果集时,指定开始位置start和结束位置end@Testpublic void searchSolrCorePageList() throws SolrServerException{// URL为http://localhost:8080/solr项目名/core的名字String url = "http://localhost:8080/solr/core2";HttpSolrServer server = new HttpSolrServer(url);Integer page = 2;//页码Integer pageSize = 15;//每页显示条数Integer start = (page -1 ) * pageSize;//从第几条开始获取Integer end = page * pageSize;//获取到第几条结束//字段名:参数值SolrQuery query = new SolrQuery("title:聪明");//分页查询:设置从第几条开始获取 和 每页显示条数query.setStart(start);//从第几条开始获取query.setRows(pageSize);//每页显示条数//根据id字段倒叙排列query.setSort("id", ORDER.desc);//开启高亮显示query.setHighlight(true);//高亮显示的标签前缀query.setHighlightSimplePre("<em color='red'>");//高亮显示的标签后缀query.setHighlightSimplePost("</em>");//添加需要高亮显示的字段query.addHighlightField("title");query.addHighlightField("name");QueryResponse response = server.query(query);//解析搜索结果集的方式一:获取高亮显示的结果集Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();//遍历的方式获取高亮的结果集for(String key : highlighting.keySet()){Map<String, List<String>> map = highlighting.get(key);for(String key2 : map.keySet()){List<String> list = map.get(key2);for(String str : list){System.out.println(str);}}}//解析搜索结果集的方式二:// 直接返回javaBean的方式。// JavaBean类中的字段上必须定义有@Field("core中的字段名")List<User> list = response.getBeans(User.class);for(User u : list){String highlightTilte = highlighting.get(u.getId()).get("title").get(0);System.out.println(highlightTilte);u.setTitle(highlightTilte);System.out.println(u);}}