Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching
论文链接:[2305.13310] Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching (arxiv.org)
代码链接:aim-uofa/Matcher: Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching (github.com)[Code尚未开源]
文章目录
- Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching
- 1. 背景和动机
- 1.1 Integrating Foundation Models
- 1.2 Matcher
- 2. 方法
- 2.1 Overview
- 2.2 Correspondence Matrix Extraction
- 2.3 Prompts Generation
- 2.3.1 Patch-Level Matching
- 2.3.2 Robust Prompt Sampler
- 2.3.3 Controllable Masks Generation
- Instance-Level Matching
- Controllable Masks Merging
- 3. 结果
- 3.1 One-shot Semantic Segmentation
- 3.2 One-shot Object Part Segmentation
- 3.3 Video Object Segmentation
- 3.4 Ablation Study
- 3.4.1 Effect of Different Image Encoders
- 3.4.2 Ablation Study of ILM
- 3.4.3 Ablation Study of Bidirectional Matching
- 3.4.4 Ablation Study of Different Mask Proposal Metrics
- 3.4.5 Effect of the Number of Frames for VOS
- 3.5 Qualitative Results
1. 背景和动机
1.1 Integrating Foundation Models
在大规模数据集上预训练后,大语言模型(Large Language Model,LLMs),例如ChatGPT,革新了NLP领域,在一些zero-shot以及few-shot任务上,展现出了极强的迁移和泛化能力。
计算机视觉领域近期也出现了一些类似的基础模型:
- Large-Scale Image-Text Contrast Pre-Training
- [2103.00020] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org)(CLIP)
- [2102.05918] Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision (arxiv.org)(ALIGN)
- Learns All-Purpose Visual Features From Raw Image Data Alone
- [2304.07193] DINOv2: Learning Robust Visual Features without Supervision (arxiv.org)
- Class-agnostic Segmentation
- [2304.02643] Segment Anything (arxiv.org)
类似于CLIP、ALIGN、DINOv2这类基础模型,虽然其在一些下游任务中表现出了较强的zero-shot迁移能力,但是其在下游任务中使用时,仍然需要配合任务特定的heads作为ImageEncoder来使用,这限制了其在真实世界中的泛化应用。
而SAM本身是一个Class-Agnostic Segmenter,无法提取高级的语义信息,这也限制了其在真实开放图像理解中的应用。
本文指出,虽然这些基础模型独立使用还存在一定的有限性,但将其结合起来,可以取得协同增效效应,同时提升分割质量和在开放世界中的泛化能力。
目前已经有一些优秀的工作进行了相关尝试:
- Grounded-Segment-Anything
但这些工作中的各个模型仍然是独立运行的,一个模型的输出会直接作为另一个模型的输入,在模型运行过程中的累积误差无法被消除。因此,需要探索更为高效、合理的基础模型集成方案。
1.2 Matcher
基于以上发现,本文重新思考了不同视觉基础模型的集成策略。
作者指出,SAM其实用性受到两个方面的限制:
- 缺乏语义信息
- 分割结果以模棱两可的Mask呈现
为了解决这些问题,本文提出仅使用一个示例并且不进行任何训练的情况下,实现Segment Anything,即OneShot Segment Anything。
在实现OneShot Segment Anything时,本文考虑了两种特征多样性:
- Semantic Diversity
- Semantic Diversity包括实例级别和语义级别感知
- 本文主要是通过一个All-purpose Feature Matching方案实现
- Structural Diversity
- Structural Diversity意味着多种语义粒度,从部分到整体,再到多个实例
- 本文主要是通过Prompt-based SAM来实现
基于以上考虑,本文提出了Matcher,一个无需训练的OneShot Segment Anything框架,其结合了一个通用特征提取模型(例如DINOv2)和一个无类别分割模型(例如SAM)。
但是简单地结合DINOv2和SAM无法取得令人满意的效果,例如,模型倾向去生成匹配的异常值和假阳性的Mask预测。
为了解决以上问题,本文提出了以下策略:
- Bidirectional Matchting Strategy:用于实现准确的图像间语义密集匹配
- Robust Prompt Sampler:用于进行Mask Propose,提升Mask Proposals的多样性,同时抑制由于异常匹配点带来的假阳性Mask预测
- Instance-Level Matching:用于选择高质量的masks
- Controllable Masks Merging:通过控制Merged Mask的数量,Matcher可以生成可控的Mask输出。
2. 方法
2.1 Overview
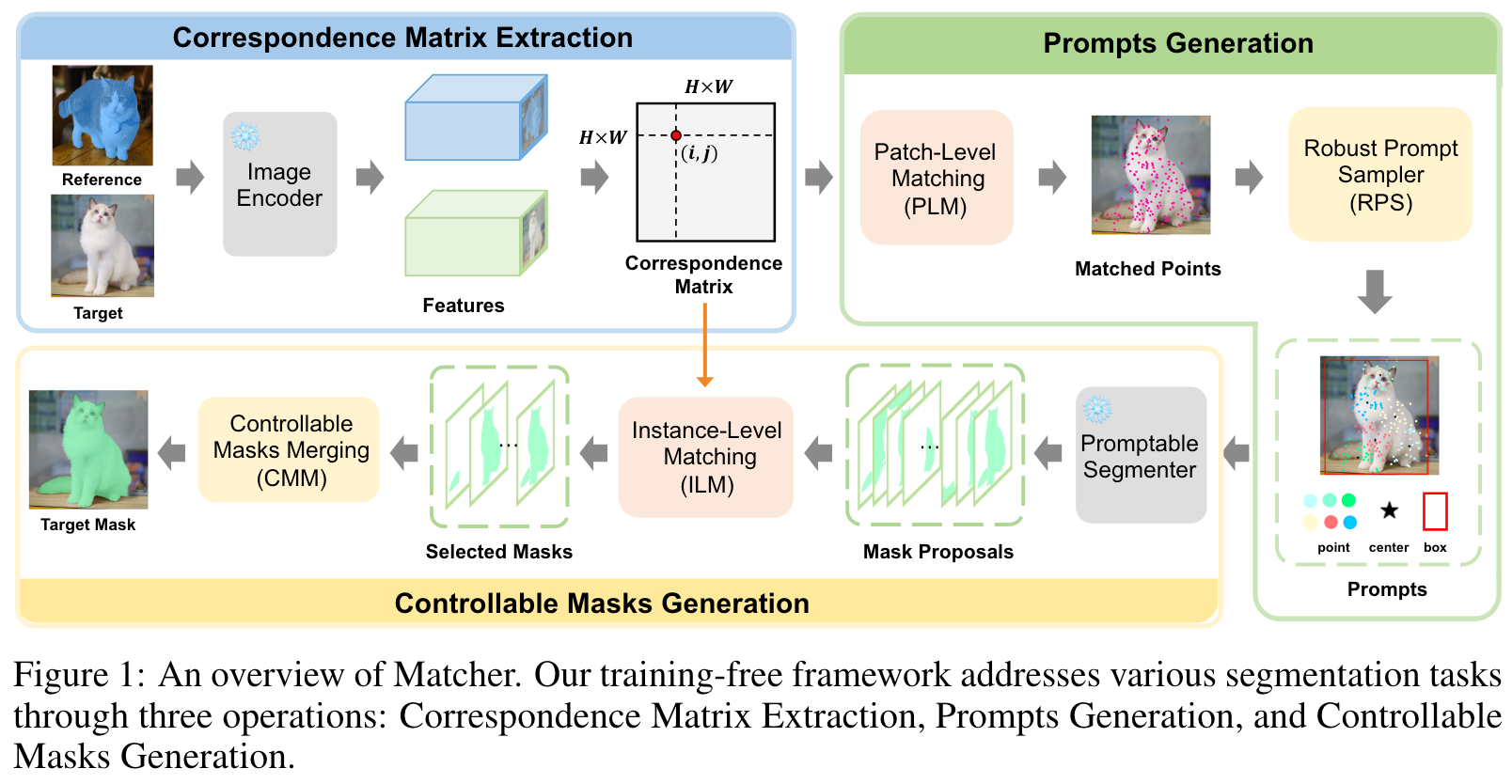
Matcher 是一个无需训练的框架,通过集成一个通用特征提取模型(例如 DINOv]、CLIP 和 MAE )和一个无类别分割模型(SAM),其可以实现OneShot Segment Anything。
对于一个给定的参考图像 x r x_r xr及其Mask m r m_r mr,Matcher可以在目标图像 x t x_t xt中分割具有相同语义信息的目标或者部位。
上图是Matcher的概览图,其主要包括三个部件:
- Correspondence Matrix Extraction (CME)
- Prompts Generation (PG)
- Controllable Masks Generation (CMG)
其OneShot Segment Anything流程大致如下:
- 通过计算 x r x_r xr和 x t x_t xt图像特征之间的的相似度,来提取Correspondence Matrix。
- 进行Patch-Level Matching (PLM) 获取匹配点,再采用Robust Prompt Sampler来采样部分质量高的匹配点,用于生成一些prompts(Point、Center以及Box)。
- 将上述prompts输入到SAM中,生成初始的Mask Proposals。
- 进行参考图像和Mask Proposals之间的Instance-Level Matching (ILM),以选取高质量的Masks
- 使用**Controllable Masks Merging (CMM)**完成最终的Mask的生成
2.2 Correspondence Matrix Extraction
Matcher使用一些开箱即用的Image Encoders去提取参考图像和目标图像的特征。
对于 x r x_r xr和 x t x_t xt,Image Encoder将会输出Patch-Level的features z r , z t ∈ R H × W × C z_r,z_t \in \mathbb{R}^{H \times W \times C} zr,zt∈RH×W×C。
Matcher会通过计算两个特征Patch-wise的相似度来探索目标图像上参考Mask的最佳匹配区域。
Correspondence Matrix S ∈ R H W × H W \mathbf{S} \in \mathbb{R}^{HW \times HW} S∈RHW×HW定义如下:
( S ) i j = z r i ⋅ z t j ∥ z r i ∥ × ∥ z t j ∥ (\mathbf{S})_{i j}=\frac{\mathbf{z}_r^i \cdot \mathbf{z}_t^j}{\left\|\mathbf{z}_r^i\right\| \times\left\|\mathbf{z}_t^j\right\|} (S)ij=∥zri∥× ztj zri⋅ztj
其中 ( S ) i j (S)_{ij} (S)ij表示第 i − t h i-th i−th 来自 z r z_r zr的Patch Feature z r i z_r^i zri 和第 j − t h j-th j−th 个来自 z t z_t zt的Patch Feature z t j z_t^j ztj之间的余弦相似度,上式可以以一个更为紧凑形式表示为: S = sim ( z r , z t ) \mathbf{S}=\operatorname{sim}\left(\mathbf{z}_r, \mathbf{z}_t\right) S=sim(zr,zt)
2.3 Prompts Generation
对于一个给定的Dense Correspondence Matrix,可以通过选取目标图像中最相似的一些Patch来获取一个粗糙的分割Mask。然而这种简单的方式,会导致不准确、支离破碎以及其他异常分割结果。
因此,本文考虑使用Correspondence Feature去生成高质量的Point、Box,以用于promptable segmentation,该流程包括一个Bidirectional Patch Matching以及一个Diverse Prompt Sampler。
2.3.1 Patch-Level Matching
在一些困难场景,例如相似的上下文信息、多个实例等,Image Encoder可以会预测一些错误的匹配结果,本文提出了一个Bidirectional Patch Matching策略,去减少这些异常匹配。
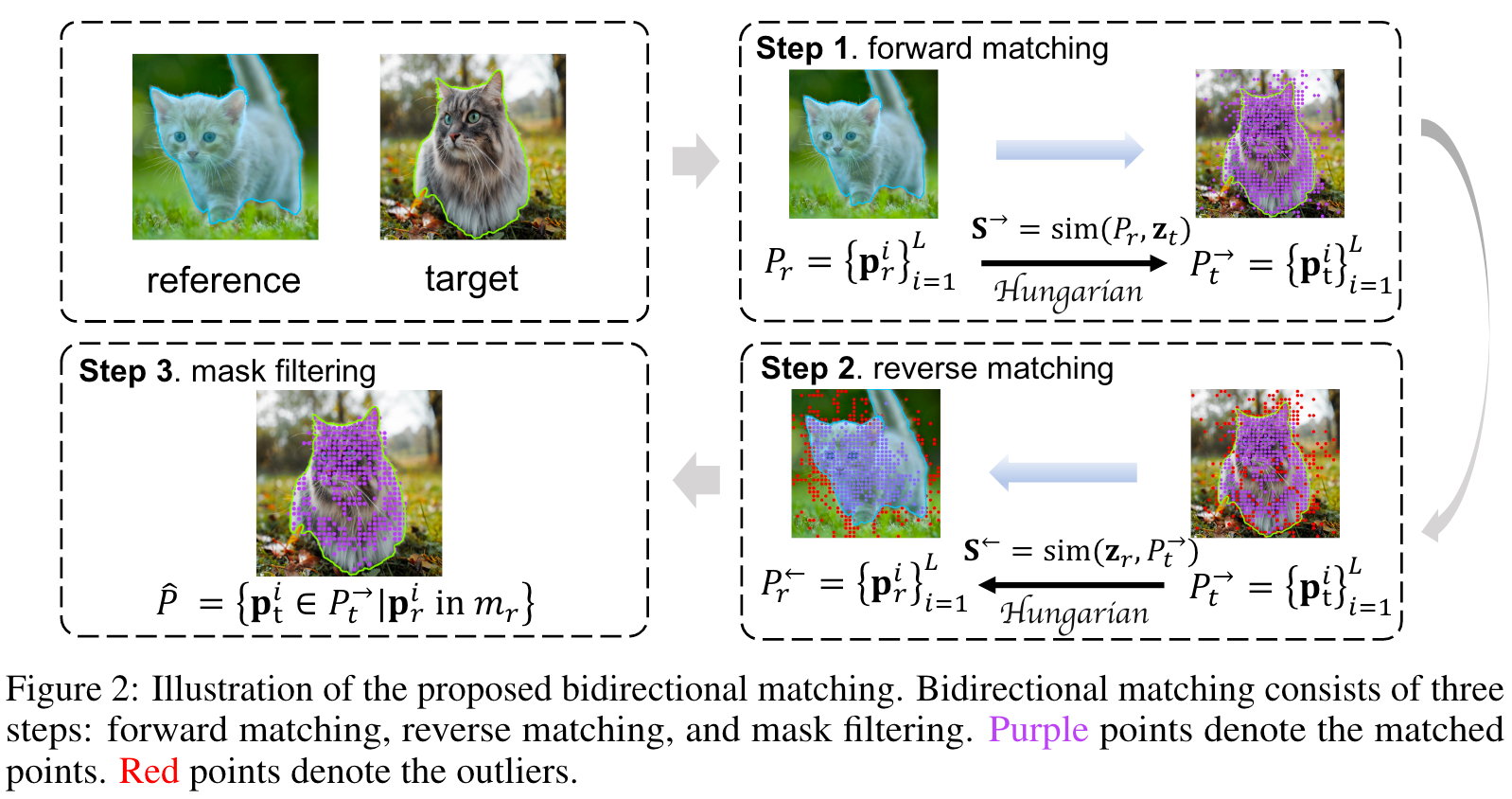
上图是Bidirectional Patch Matching策略的流程图,其大致步骤如下:
- 使用Forward Correspondence Matrix S → = sim ( P r , z t ) \mathbf{S}^{\rightarrow}=\operatorname{sim}\left(P_r, \mathbf{z}_t\right) S→=sim(Pr,zt) 在参考Mask的所有点 P r = { p r i } i = 1 L P_r=\left\{\mathbf{p}_r^i\right\}_{i=1}^L Pr={pri}i=1L 和 z t z_t zt之间进行二分匹配(和DETR上进行Object和Target进行匹配的方式一样,可以参考DETR | 基于匈牙利算法的样本分配策略_detr 匈牙利_Clichong的博客-CSDN博客),在目标图像上获得Forward Matched Points P t → = { p t i } i = 1 L P_t^{\rightarrow}=\left\{\mathbf{p}_t^i\right\}_{i=1}^L Pt→={pti}i=1L。
- 然后再进行另一个二分匹配,即 P t → P_t^{\rightarrow} Pt→和 z t z_t zt之间的反向匹配,使用Reverse Correspondence Matrix S ← = sim ( z r , P t → ) \mathbf{S}^{\leftarrow}=\operatorname{sim}\left(\mathbf{z}_r, P_t^{\rightarrow}\right) S←=sim(zr,Pt→)去获得在参考图像上的Reversed Matched Points P r ← = { p r i } i = 1 L P_r^{\leftarrow}=\left\{\mathbf{p}_r^i\right\}_{i=1}^L Pr←={pri}i=1L。
- 最终过滤掉那些对应Reverse Points不在参考Mask区域内的前向点,最终的匹配点集合为 P ^ = { p t i ∈ P t → ∣ p r i \hat{P}=\left\{\mathbf{p}_t^i \in P_t^{\rightarrow} \mid \mathbf{p}_r^i\right. P^={pti∈Pt→∣pri in m r } \left.m_r\right\} mr}。
简单来说:
根据二分匹配,将参考图像对应Mask上的所有点投射到目标图像上,再根据二分匹配将投射到目标图像上的所有点再投射回原参考图像上,检查哪些点经过投射后,不再再落在参考图像原Mask区域内了,这些点就不是匹配点。
2.3.2 Robust Prompt Sampler
为了使得Matcher可以在不同语义粒度(部分、整体以及多实例)上实现鲁棒的分割,本文提出了一个Robust Prompt Sampler去生成多样且有意义的Mask Proposals。
其步骤如下:
- 使用k-means++算法,根据位置将匹配点 P ^ \hat{P} P^聚类为 K K K个簇 P ^ k \hat{P}_k P^k
- 接下来采样以下三种子集作为prompts
- Patch-Level Prompts P p ⊂ P ^ k P^p \subset \hat{P}_k Pp⊂P^k :在每个簇内采样
- Instance-Level Prompts P i ⊂ P ^ P^i \subset \hat{P} Pi⊂P^ :在所有匹配点内采样
- Global Prompts P g ⊂ C P^g \subset C Pg⊂C :在所有簇中心点 C = { c 1 , c 2 , … , c k } C=\left\{c_1, c_2, \ldots, c_k\right\} C={c1,c2,…,ck}内进行采样
- 最后增加参考点 P ^ \hat{P} P^的Bounding Box作为Box Proposal
Robust Prompt Sampler这种策略不仅增加了Mask Proposals的多样性,而且还抑制了由匹配异常值引起的碎片化假阳性Mask预测。
2.3.3 Controllable Masks Generation
Image Encoder 提取的目标边缘特征会混淆背景信息,导致一些异常激活,这些异常激活点可能会被选择作为prompt,从而生成一些假阳性Mask预测。
为了解决该问题,Matcher进一步通过Instance-Level Matching模块从Mask Proposals中选择高质量的Mask,然后合并选择的Masks以获得最终的目标Mask。
Instance-Level Matching
Matcher进行参考Mask和Mask Proposals之间的Instance-Level Matching,用于选择好的Masks。
本文将该匹配问题看作是Optimal Transport问题,并且使用Earth Mover’s Distance (EMD)去计算Masks内密集语义特征之间的结构距离(记作 e m d emd emd),以确定Masks之间的相关性(这个部分可以参考:机器学习工具(二)Notes of Optimal Transport - 知乎 (zhihu.com))。
除此之外,本文还提出了额外两个Mask Proposal Metrics,用于衡量Mask Proposal的质量:
purity = Num ( P ^ m p ) Area ( m p ) \text { purity }=\frac{\operatorname{Num}\left(\hat{P}_{m p}\right)}{\operatorname{Area}\left(m_p\right)} purity =Area(mp)Num(P^mp)
coverage = Num ( P ^ m p ) Num ( P ^ ) \text { coverage }=\frac{\operatorname{Num}\left(\hat{P}_{m p}\right)}{\operatorname{Num}(\hat{P})} coverage =Num(P^)Num(P^mp)
其中 P ^ m p = { p t i ∈ P t → ∣ p t i in m p } \hat{P}_{m p}=\left\{\mathbf{p}_t^i \in\right.\left.P_t \rightarrow \mid \mathbf{p}_t^i \text { in } m_p\right\} P^mp={pti∈Pt→∣pti in mp}, Num ( ⋅ ) \operatorname{Num}(\cdot) Num(⋅)表示Points的数目, Area ( ⋅ ) \operatorname{Area}(\cdot) Area(⋅)表示Mask的面积, m p m_p mp表示Mask Proposal。
score = α ⋅ ( 1 − emd ) + β ⋅ purity ⋅ coverage λ , \text { score }=\alpha \cdot(1-\text { emd })+\beta \cdot \text { purity } \cdot \text { coverage }{ }^\lambda, score =α⋅(1− emd )+β⋅ purity ⋅ coverage λ,
其中 α , β \alpha, \beta α,β以及 λ \lambda λ都是平衡系数。
Matcher可以使用提出的度量指标score,通过适当的阈值过滤假阳性Mask预测,然后可以TopK个分数最高的Mask进行输出。
Controllable Masks Merging
通过控制最终合并的Masks的数目,Matcher 可以为目标图像中具有相同语义的实例生成可控的Mask输出。
3. 结果
Matcher默认使用DINOv2(ViT-L/14)作为Image Encoder,SAM(ViT-H)作为Segmenter。
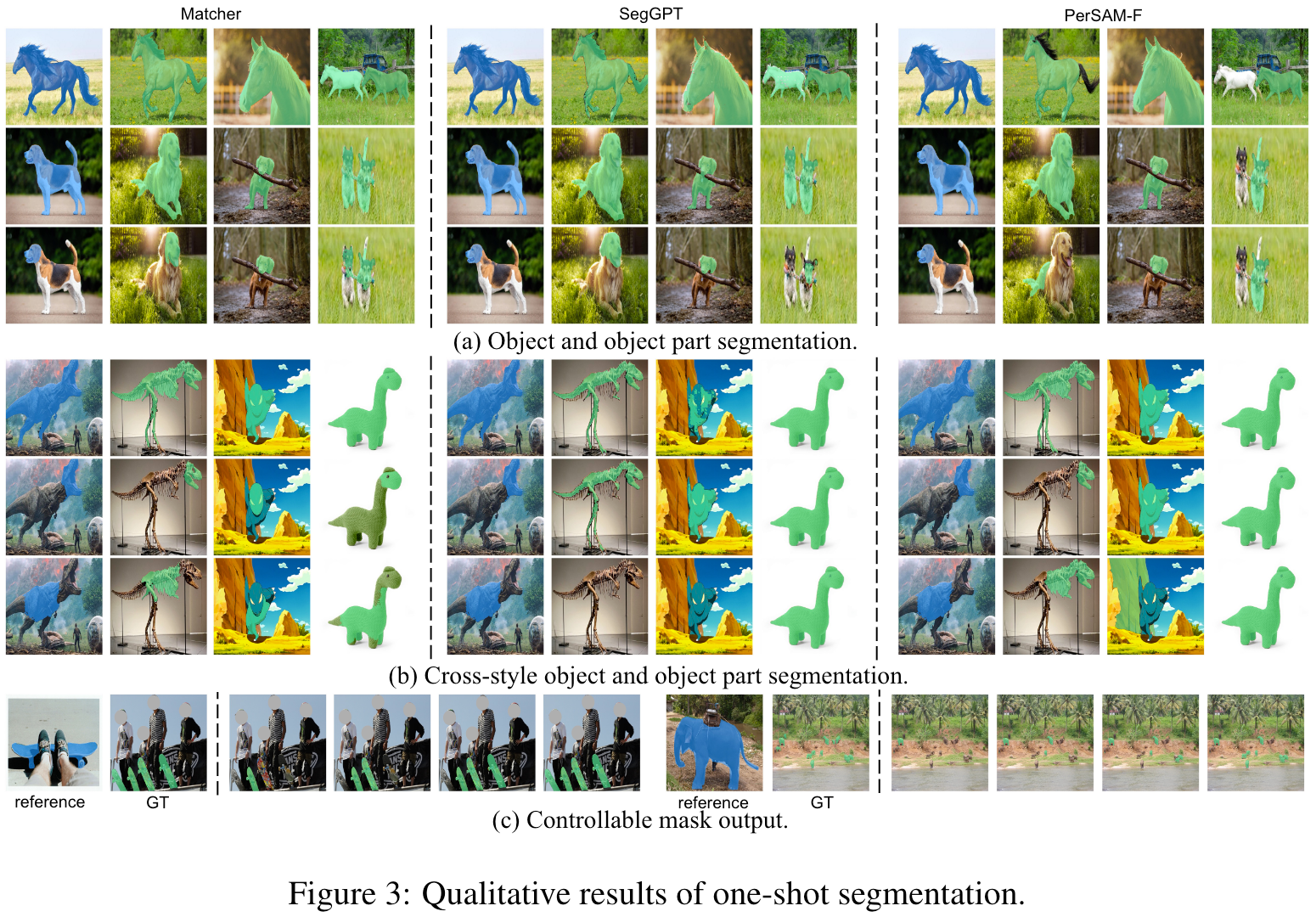
3.1 One-shot Semantic Segmentation
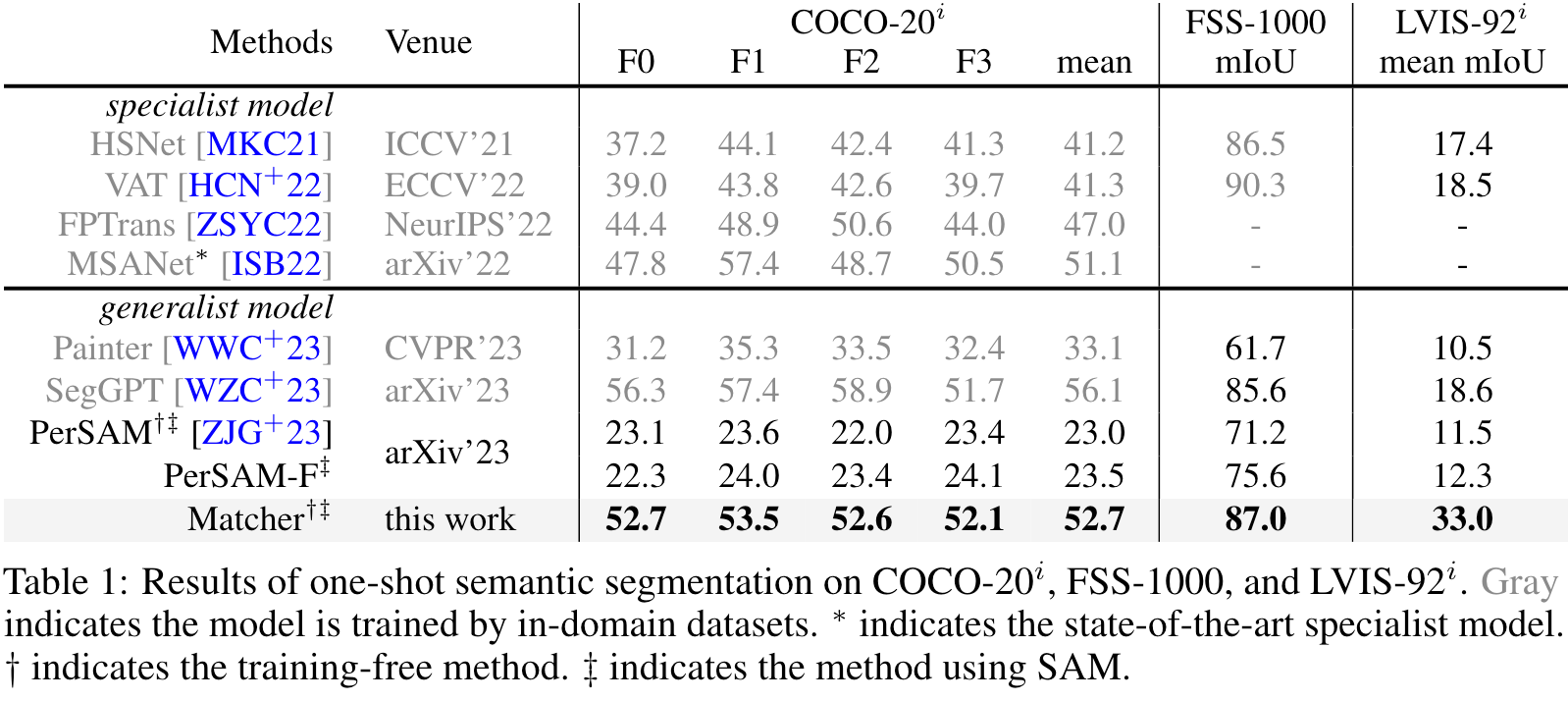
可以看出,Matcher在无需任何训练微调的情况下,超越了其他SOTA结果,接近SegGPT(SegGPT的训练数据包括COCO)结果。
对比PerSAM的结果可以看出,仅依赖于SAM输出的结果对于语义任务泛化能力较差。
3.2 One-shot Object Part Segmentation

即使SAM具有在三个层次(whole, part, and subpart)上分割任意物体的能力,但是由于其缺乏语义信息,其无法区分一些模棱两可的Masks。
而Matcher则通过结合All-Purpose Feature Extractor,大大提升了SAM的细粒度Object Part Segmentation能力。
3.3 Video Object Segmentation
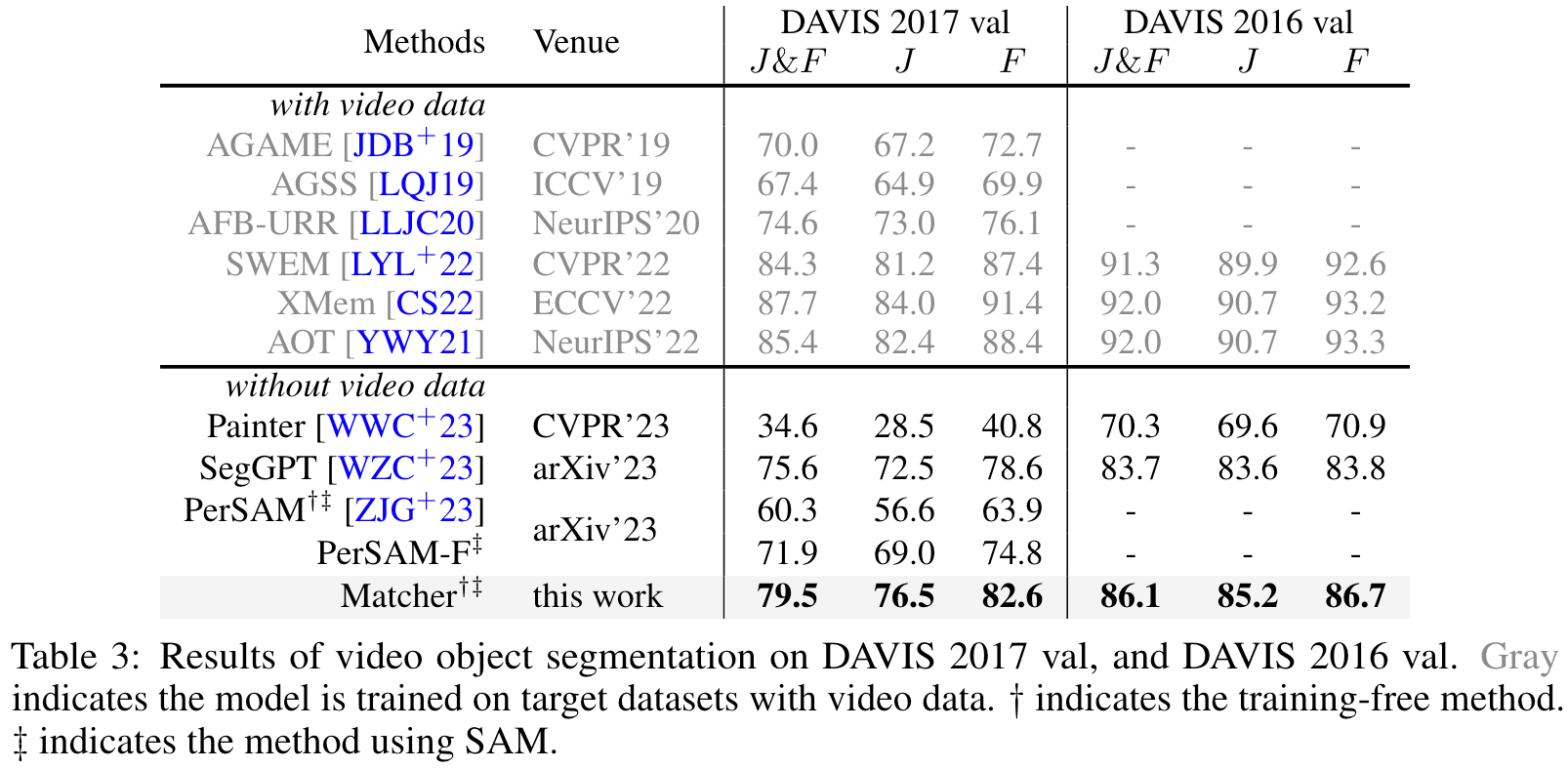
在没有在视频数据集上训练的情况下,Matcher可以取得和在视频数据集上训练过的模型相当的性能。
3.4 Ablation Study
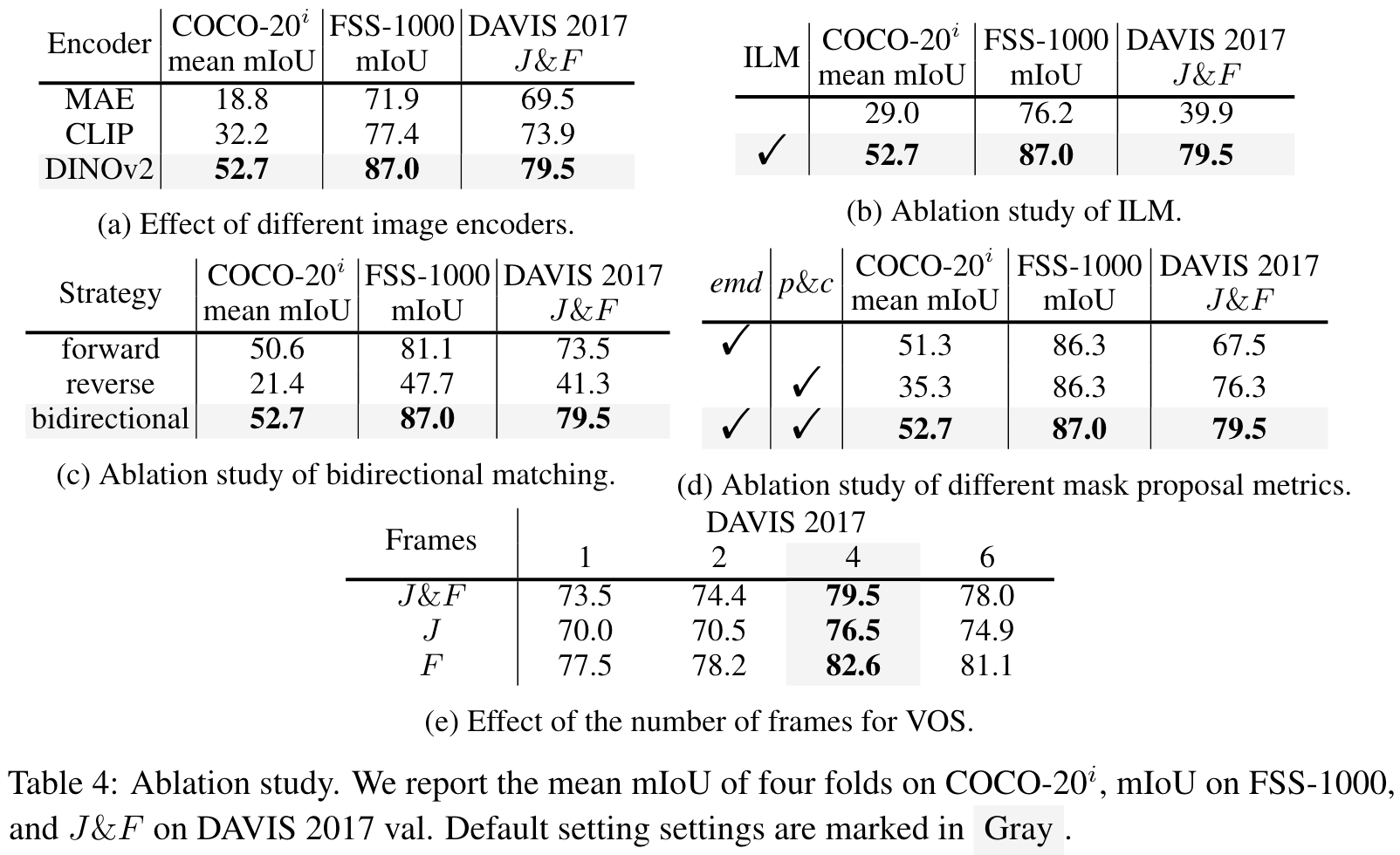
3.4.1 Effect of Different Image Encoders
对比CLIP、MAE,DINOv2在所有数据集上,都取得了更优的性能。
-
CLIP:由于文本-图像对比预训练限制了学习复杂的像素级信息,CLIP不能精确地匹配图像块。
-
MAE:虽然MAE可以通过Mask图像来提取像素级特征,但它的表现很差。作者怀疑,MAE提取的块级特征混淆了周围块的信息,导致错误的特征匹配。
-
DINOv2:通过图像级和块级判别式自监督学习预训练,DIVOv2提取了通用的视觉特征,并展示了令人印象深刻的块级特征匹配能力。
3.4.2 Ablation Study of ILM
ILM极大地提升了模型的分割能力。
3.4.3 Ablation Study of Bidirectional Matching
从结果可以看出,Reverse Matching效果很差,Forward Matching已经可以取得尚可的效果,但Bidirectional Matching可以取得更佳的性能。
3.4.4 Ablation Study of Different Mask Proposal Metrics
对于不同的数据集,三种指标的效果不同:
- 对于COCO数据集来说,emd指标相较于purity和coverage,更为重要
- 对于DAVIS 2017数据集来说,purity和coverage则更为重要
- 对于FSS数据集来说,两者效果相当
当同时结合以上指标时,都能取得更好的效果。
3.4.5 Effect of the Number of Frames for VOS
随着帧数的增加,效果会逐渐提升,在四帧时效果最优。
3.5 Qualitative Results