学习目标
1、了解HTTP协议的基本概念
2、掌握HTTP请求报文与响应报文
3、学会使用开发者工具查看HTTP协议的通信过程
4、搭建Python自带的静态Web服务器
5、掌握Python静态Web服务器开发
一、HTTP协议概述
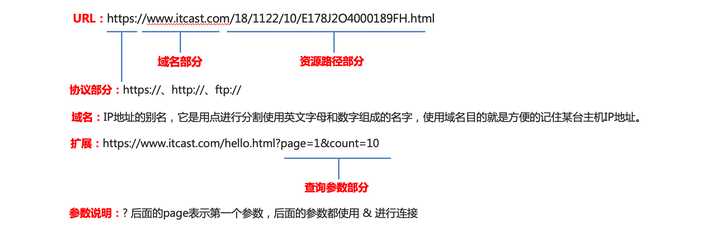
1、网址URL
网址又称为URL,URL的英文全拼是(Uniform Resoure Locator),表达的意思是统一资源定位符,通俗理解就是网络资源地址。URL地址:https://www.itcast.com/18/1122/10/E178J2O4000189FH.html
2、URL的组成
3、HTTP协议
☆ 场景导入
首先我们来看一个场景:

在浏览器与Web服务器通信过程中,其数据格式有什么规则么,是否可以任意设置?答:不是的,浏览器与Web服务器端的通信,必须使用HTTP协议来规定浏览器和web服务器之间通讯的数据的格式。
☆ 什么是HTTP协议?
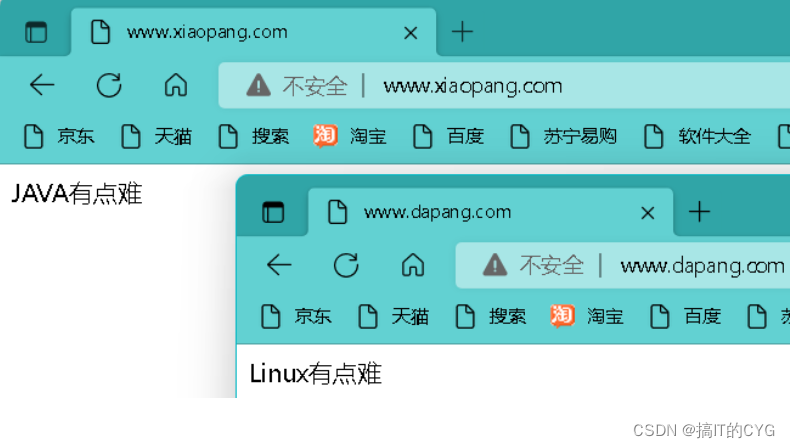
HTTP协议的全称是(HyperText Transfer Protocol),翻译过来就是超文本传输协议。超文本是指在文本数据的基础上还包括非文本数据,非文本数据有图片、音乐、视频等,而这些非文本数据会使用链接的方式进行加载显示,通俗来说超文本就是带有链接的文本数据也就是我们常说的网页数据,如下图所示:

☆ HTTP协议的概念及作用
HTTP协议的制作者是蒂姆·伯纳斯-李,1991年设计出来的,HTTP协议设计之前目的是传输网页数据的,现在允许传输任意类型的数据。传输HTTP协议格式的数据是基于TCP传输协议的,发送数据之前需要先建立连接。TCP传输协议是用来保证网络中传输的数据的安全性的,HTTP协议是用来规定这些数据的具体格式的。
注意:HTTP协议规定的数据格式是浏览器和Web服务器通信数据的格式,也就是说浏览器和Web服务器通信需要使用HTTP协议。
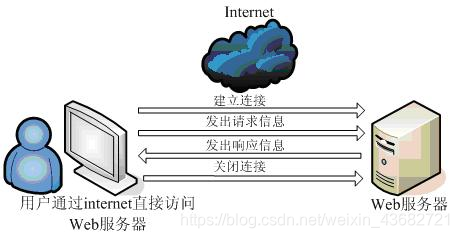
☆ 浏览器访问Web服务器的过程
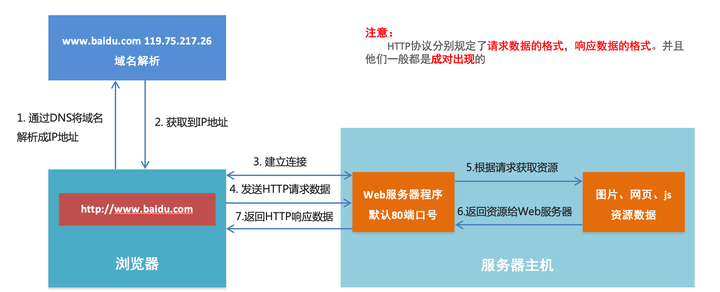
二、HTTP请求报文与响应报文
1、HTTP请求报文
HTTP最常见的请求报文有两种:① GET方式的请求报文 ② POST方式的请求报文 GET: 获取Web服务器数据 POST: 向Web服务器提交数据
2、GET请求报文格式

---- 请求行 ----
GET /wp-content/uploads/2020/12/zm.svg HTTP/1.1 # GET请求方式 请求资源路径 HTTP协议版本
---- 请求头 -----
Host: www.itcast.cn # 服务器的主机地址和端口号,默认是80
Connection: keep-alive # 和服务端保持长连接
Upgrade-Insecure-Requests: 1 # 让浏览器升级不安全请求,使用https请求
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 # 用户代理,也就是客户端的名称
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 # 可接受的数据类型
Accept-Encoding: gzip, deflate # 可接受的压缩格式
Accept-Language: zh-CN,zh;q=0.9 #可接受的语言
Cookie: pgv_pvi=1246921728; # 登录用户的身份标识
---- 空行 ----
3、GET请求报文分析
GET / HTTP/1.1\r\n
Host: www.itcast.cn\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: zh-CN,zh;q=0.9\r\n
Cookie: pgv_pvi=1246921728; \r\n
\r\n (请求头信息后面还有一个单独的’\r\n’不能省略) => 空白行
注意:每项数据之间使用\r\n进行结束 在HTTP请求中,每个选项结束后,其后面都要添加一个标签\r\n(代表一行的结束)
在Windows系统中,换行符使用\n来实现。但是在Linux以及Unix系统中,换行符需要使用\r\n来实现。
4、POST请求报文格式

---- 请求行 ----
POST /xmweb?host=mail.itcast.cn&_t=1542884567319 HTTP/1.1 # POST请求方式 请求资源路径 HTTP协议版本
---- 请求头 ----
Host: mail.itcast.cn # 服务器的主机地址和端口号,默认是80
Connection: keep-alive # 和服务端保持长连接
Content-Type: application/x-www-form-urlencoded # 告诉服务端请求的数据类型
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 # 客户端的名称
---- 空行 ----
---- 请求体 ----
username=hello&pass=hello # 请求参数
5、POST请求报文分析
POST /xmweb?host=mail.itcast.cn&_t=1542884567319 HTTP/1.1\r\n
Host: mail.itcast.cn\r\n
Connection: keep-alive\r\n
Content-Type: application/x-www-form-urlencoded\r\n
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\r\n
\r\n(请求头信息后面还有一个单独的’\r\n’不能省略)
username=hello&pass=hello
注意:每项数据之间使用\r\n进行结束
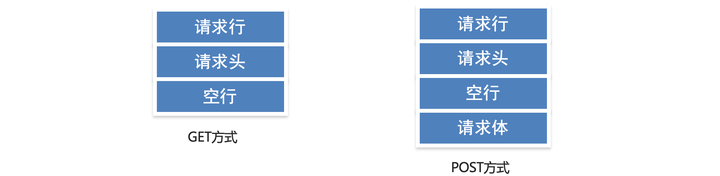
6、GET与POST请求报文小结
① 一个HTTP请求报文可以由请求行、请求头、空行和请求体4个部分组成
② 请求行是由三部分组成: 请求方式、请求资源路径、HTTP协议版本(1.1或2.0)
③ GET方式的请求报文没有请求体,只有请求行、请求头、空行组成
④ POST方式的请求报文可以有请求行、请求头、空行、请求体四部分组成。注意:POST方式可以允许没有请求体,但是这种格式很少见。
7、HTTP 响应报文分析(重点)

--- 响应行/状态行 ---
HTTP/1.1 200 OK # HTTP协议版本 状态码 状态描述
--- 响应头 ---
Server: Tengine # 服务器名称
Content-Type: text/html; charset=UTF-8 # 内容类型(响应的数据类型,image/png)
Connection: keep-alive # 和客户端保持长连接
Date: Fri, 23 Nov 2018 02:01:05 GMT # 服务端的响应时间
--- 空行 ---
--- 响应体 ---
<!DOCTYPE html><html lang=“en”> …</html> # 响应给客户端的数据(html网页)
响应头信息主要是告诉浏览器的客户端应该如何处理我们返回的数据。
8、HTTP响应状态码
是用于表示Web服务器响应状态的3位数字代码
| 状态码 | 说明 |
|---|---|
| 200 | 服务器已成功处理了请求 |
| 400 | 错误的请求,请求地址或者参数有误 |
| 404 | 请求资源在服务器不存在 |
| 500(服务器端异常) | 服务器内部源代码出现错误 |
三、查看HTTP协议的通信过程
1、谷歌浏览器开发者工具
安装GoogleChrome浏览器,在Windows和Linux平台按F12或Ctrl+Shift+I调出开发者工具,Mac中选择“视图 ->开发者->”开发者工具或者直接使用alt+command+i 这个快捷键,还有一个多平台通用的操作就是在网页右击选择检查。
提示:开发者工具还是查看网页布局和JS代码调试的利器。
2、HTTP协议的通信过程

注意:每一次浏览器和服务器的数据通讯,都是成对出现的即请求和响应,同时每一次请求和响应都必须符合HTTP协议的格式
3、谷歌浏览器开发者工具使用
第一步:了解各选项卡功能
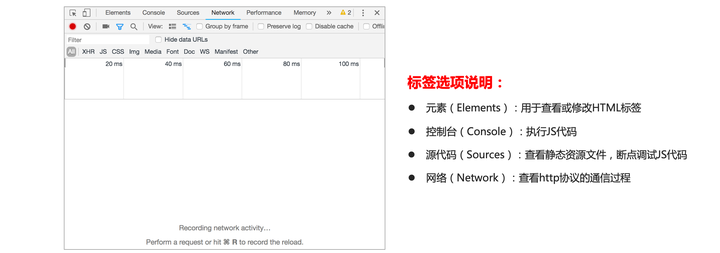
第二步:使用Network发送HTTP请求

第三步:查看HTTP协议的通信过程 请求头、请求头信息
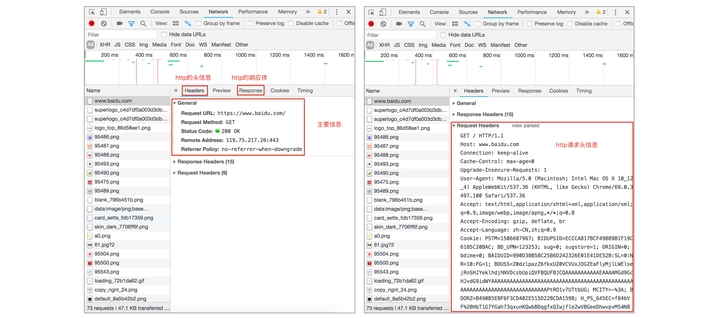
响应头、响应体信息

4、小结
谷歌浏览器的开发者工具是查看http协议的通信过程利器,通过Network标签选项可以查看每一次的请求和响应的通信过程,调出开发者工具的通用方法是在网页右击选择检查。Headers选项总共有三部分组成:
① General: 主要信息
② Response Headers: 响应头
③ Request Headers: 请求头 Response选项是查看响应体信息的
四、搭建Python自带的静态Web服务器
1、什么是静态Web服务器
可以为发出请求的浏览器提供静态文档(html/css/js/图片/音频/视频)的程序。平时我们浏览百度新闻数据的时候,每天的新闻数据都会发生变化,那访问的这个页面就是动态的,而我们开发的是静态的,每天访问我们自己的静态web服务器,页面的数据不会发生变化。
2、搭建Python自带的静态Web服务器
Linux创建方式:

Windows创建方式:
① 创建一个文件夹,然后把所有的资源文件都放入这个文件夹中
② 在DOS窗口使用cd命令切换到此目录
③ 使用python -m命令创建静态Web服务器
python -m http.server 9000
-m表示运行包里面的模块,执行这个命令的时候,需要进入你自己指定静态文件的目录,然后通过浏览器就能访问对应的html文件了,这样一个静态的web服务器就搭建好了。
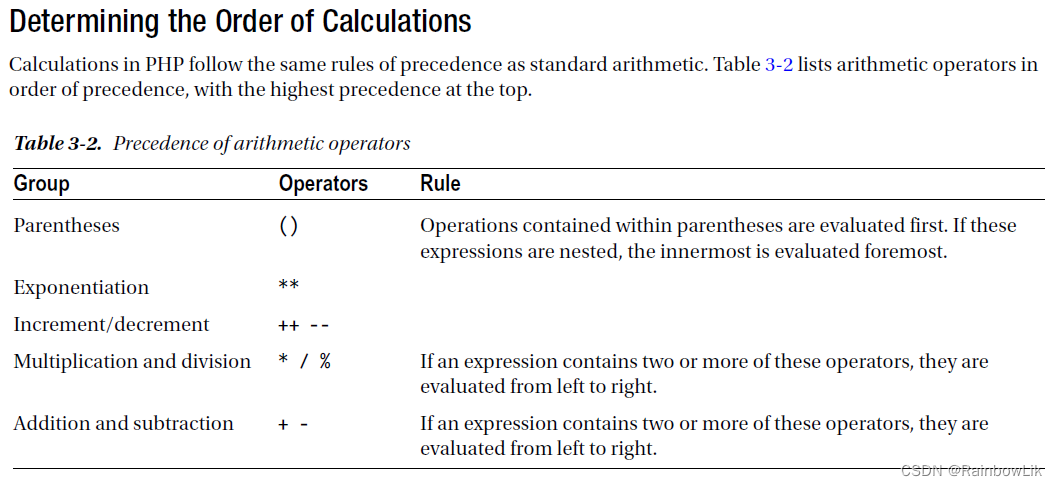
④ 访问Web静态服务器:
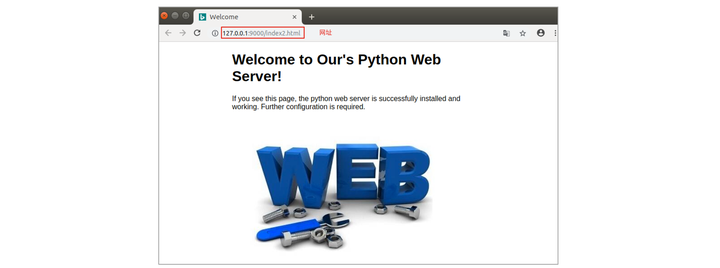
查看HTTP通信过程:

3、小结
静态Web服务器是为发出请求的浏览器提供静态文档的程序,搭建Python自带的Web服务器使用 python –m http.server 端口号这个命令即可,端口号不指定默认是8000
强调!:应答体中携带的数据发送到浏览器,浏览器经过渲染产生具体页面
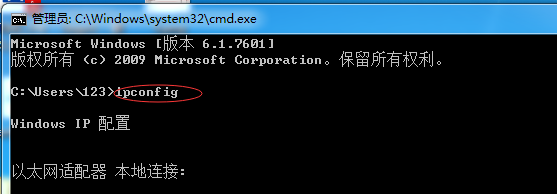
五、使用Python开发自己的Web服务器
Web服务器 = TCP服务器(七步走) + HTTP协议(请求、响应)
1、开发步骤

2、返回固定页面的数据
import socket
if __name__ == '__main__':
# 1、创建socket
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 2、绑定IP和端口
tcp_server_socket.bind(("", 8080))
# 3、设置监听
tcp_server_socket.listen(128)
while True:
# 4、建立连接
client_socket, client_addr = tcp_server_socket.accept()
client_request_data = client_socket.recv(1024).decode()
print(client_request_data)
with open("html/index.html", "rb") as f:
file_data = f.read()
# 响应行
response_line = "HTTP/1.1 200 OK\r\n"
# 响应头
response_header = "Server:pwb\r\n"
# 响应体
response_body = file_data
# 响应数据
response_data = (response_line + response_header + "\r\n").encode() + response_body
# 5、发送数据
client_socket.send(response_data)
# 6、关闭客户端socket连接
client_socket.close()
3、返回指定页面的数据
分析步骤:① 获取用户请求资源的路径
② 根据请求资源的路径,读取指定文件的数据
③ 组装指定文件数据的响应报文,发送给浏览器
④ 判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器 获取用户请求资源的路径:
request_list = client_request_data.split(" ", maxsplit=2)
request_path = request_list[1] # /gdp.html
if request_path == "/":
# 如果用户没有指定资源路径那么默认访问的数据是首页的数据
request_path = "/index.html"
获取指定页面的数据:
# 读取指定文件数据
# 使用rb的原因是浏览器也有可能请求的是图片
with open("html/" + request_path, "rb") as file:
# 读取文件数据
file_data = file.read()
组装指定页面数据的响应报文:
# 响应行
response_line = "HTTP/1.1 200 OK\r\n"
# 响应头
response_header = "Server: PWS1.0\r\nContent-Type: text/html;charset=utf-8\r\n"
# 响应体
response_body = file_data
# 拼接响应报文数据
response_data = (response_line + response_header + "\r\n").encode("utf-8") + response_body
# 发送响应报文数据
client_socket.send(response_data)
client_socket.close()
组装404页面数据的响应报文:
try:
# 打开指定文件,代码省略...
except Exception as e:
response_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server: PWS1.0\r\nContent-Type: text/html;charset=utf-8\r\n'
response_body = '<h1>非常抱歉,您当前访问的网页已经不存在了</h1>'.encode('utf-8')
response_data = (response_line + response_header + '\r\n').encode('utf-8') + response_body
# 发送404响应报文数据
client_socket.send(response_data)
else:
# 发送指定页面的响应报文数据,代码省略...
finally:
client_socket.close()
六、FastAPI框架
学习目标
-
能够知道什么是FastAPI
-
能够知道怎么安装FastAPI
-
能够掌握FastAPI的基本使用
-
能够掌握FastAPI实现访问多个指定网页
1. 什么是FastAPI
FastAPI是一个现代的,快速(高性能)python web框架. 基于标准的python类型提示,使用python3.6+构建API的Web框架.

简单讲FastAPI就是把做web开发所需的相关代码全部简化, 我们不需要自己实现各种复杂的代码, 例如多任务,路由装饰器等等. 只需要调用FastAPI提供给我们的函数, 一调用就可以实现之前需要很多复杂代码才能实现的功能.
FastAPI的特点
-
性能快:高性能,可以和NodeJS和Go相提并论
-
快速开发:开发功能速度提高约200%至300%
-
更少的Bug:
-
Fewer bugs: 减少40%开发人员容易引发的错误
-
直观:完美的编辑支持
-
简单: 易于使用和学习,减少阅读文档的时间
-
代码简洁:很大程度上减少代码重复。每个参数可以声明多个功能,减少bug的发生
-
标准化:基于并完全兼容API的开发标准:OpenAPI(以前称为Swagger)和JSON Schema
搭建环境
-
python环境:Python 3.6+
fastapi安装
☆ 安装方式1:
-
安装fastapi
-
pip install fastapi
-
如果用于生产,那么你还需要一个ASGI服务器,如Uvicorn或Hypercorn
-
pip install uvicorn
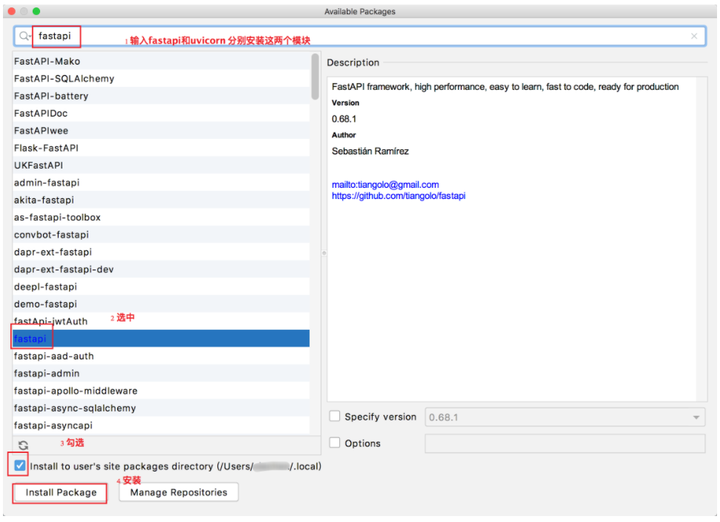
☆ 安装方式2 : 1)选择File->Settings

2)选择对应项目的Project Interpreter -> 选择pygame(可以输入pygame进行搜索,节省时间) -> install package按钮 -> 等待项目安装pygame 包完成(可能需要几分钟到十几分钟)-> 返回后如果有pygame package信息,则说明项目配置成功

2. FastAPI的基本使用
功能需求:
-
搭建服务器
-
返回html页面
基本步骤:
-
导入模块
-
创建FastAPI框架对象
-
通过@app路由装饰器收发数据
-
运行服务器
代码实现:
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index.html")
def main():
with open("source/html/index.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
3. 通过FastAPI访问多个指定网页
-
路由装饰器的作用:
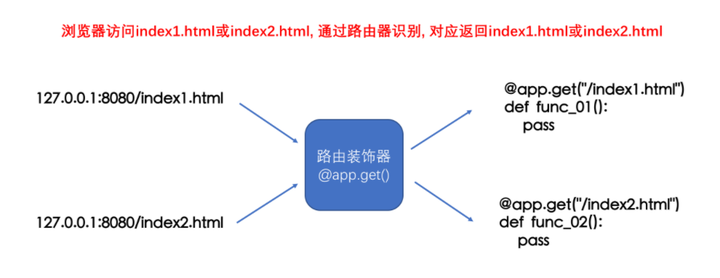
-
实际上通过路由装饰器我们就可以让一个网页对应一个函数, 也就可以实现访问指定网页了.
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index1.html")
def main():
with open("source/html/index1.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
@app.get("/index2.html")
def main():
with open("source/html/index2.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
4. 小结
-
基本步骤:
-
导入模块
-
创建FastAPI框架对象
-
通过@app路由装饰器收发数据
-
运行服务器