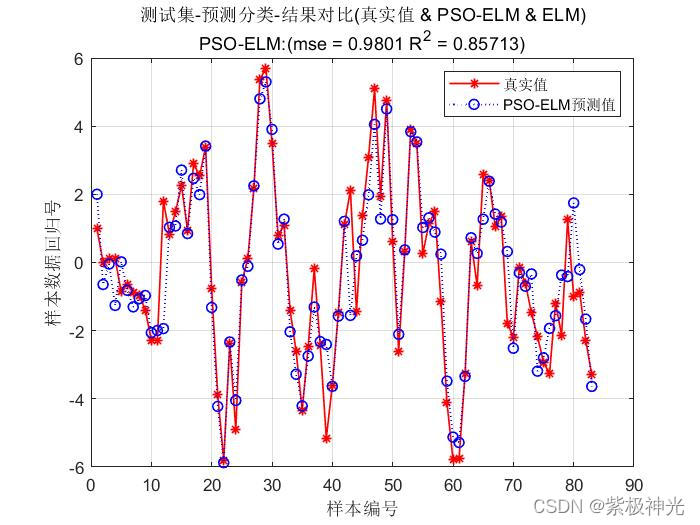
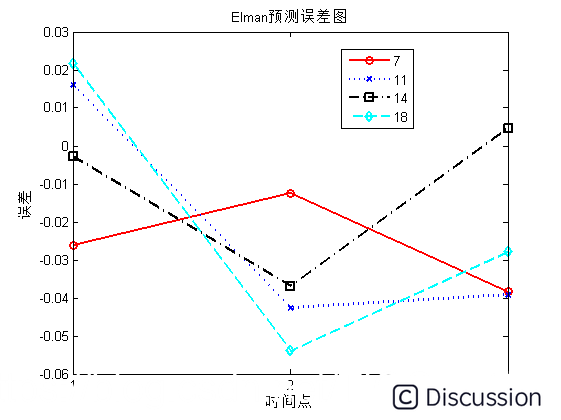
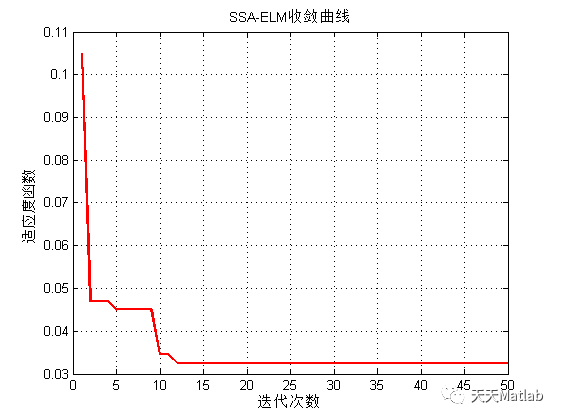
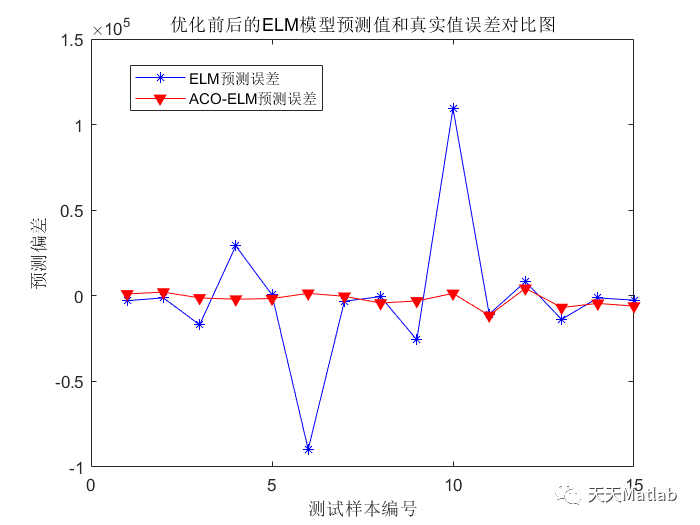
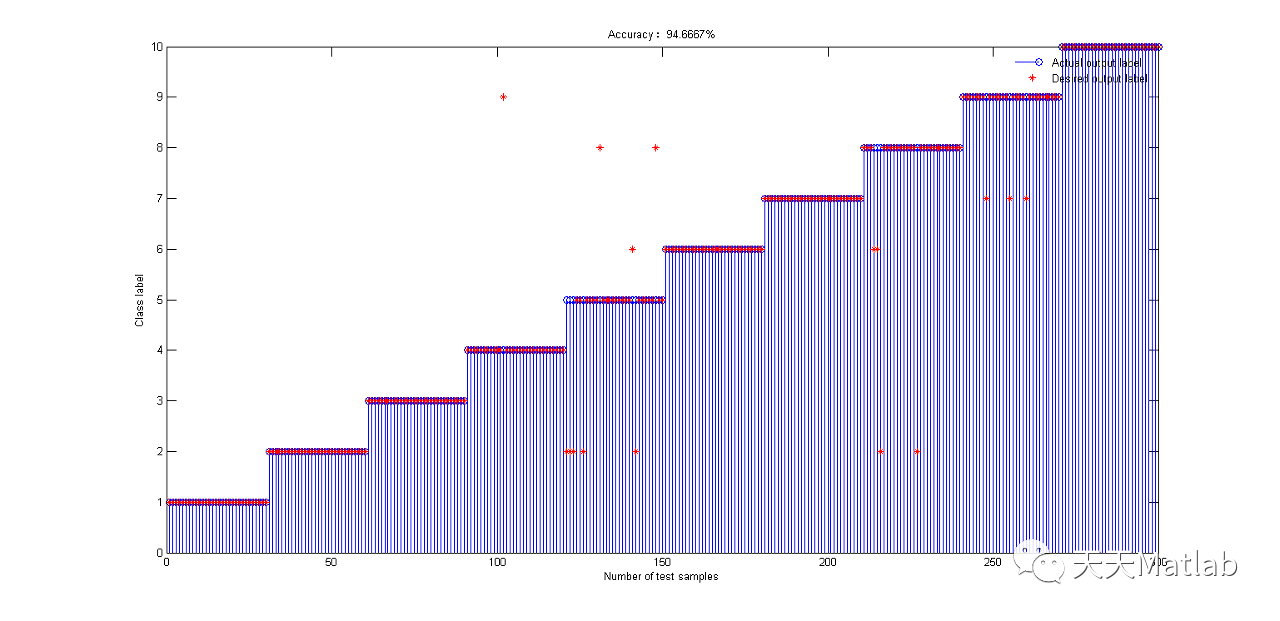
在反复的看了ELMo源码和参考网上各路大神的经验之后,终于对ELMo的架构有了比较清楚的认识。总结一下自己对ELMo的理解,其实还有很多细节没有搞清楚。
一.模型架构
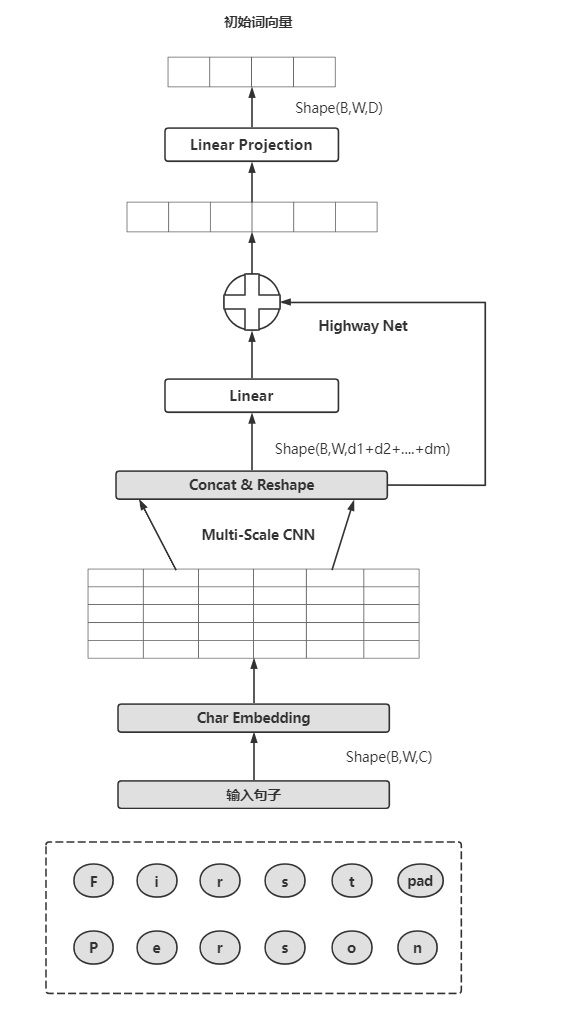
下面是我画的一个架构简图,对于ELMo不管你输入的是词还是字符,它都会以字符的单位进行后续的字符卷积,对与词的索引是根据词典序号索引的,而字符论文说英文的字符加上一些特殊的标记字符总共不会超过262个,所以对字符的索引是通过utf-8编码来索引的,比如单词“word"的utf-8编码是{119,111,114,100},通过这些编码就可以找到某一个固定的字符。对于整个模型的输入(这里只考虑最小单位的输入,也就是模型的每一个样本)的话由于是语言模型,而作者在train_elmo文件中定义的时间步(unroll_steps)是20,也就是一个样本就是X=20个词,对应的Y=20个对应的下一个词。这就是我们之前常说的一个样本X:Y。
在得到我们的样本之后,初始化一个262*16的字符嵌入矩阵(或者二维数组),这个16就是每一个字符向量的纬度可以自己定义,通过索引可以找到每个词对应字符的向量,然后进行字符卷积,这其中包括最池化,然后在经过2个highway layers。进入BiLSTM。这一层总共有20个LSTMCell,分别对应20个词的向量的输入,论文中的4096也就是源码中的lstm_dim其实就是隐藏层最原始的h,c的纬度。或者说就是单个LSTMCell里面单个门的sigmoid单元的个数,这个参数其实就是tensorflow中tf.nn.rnn_cell.LSTMCell(num_units)中的第一个参数。注意不同地方的命名不一样,非常容易混淆。源码中的名字也换了好几次。
两层LSTM之间还有一个残差连接,其实就是把第一层LSTM的输入加到LSTM的输出上。
最后就是一个softmax,但是这个用的是Sampled_softmax,这个我开始读源码的时候并没有注意到,知道看到n_negtive_samples_batch这个参数时才开始注意它。在网上找了很多资料感觉都是把论文的东西重复了一遍,并没有讲的很清楚,这里感觉是用了负采样的思想,在计算softmax的时候,只需要找一些负样本,并不需要计算所有的可能的词。但是这只是训练 的时候才会用到,而真正在预测的时候还是要遍历词典,计算softmax分母的和,就是那个当词典很大的时候非常耗费时间的那部分。

注意:
我上面所说的中间有20个词输入是源码中的bilm.train中的实现方式,是通过tf.nn.static_rnn()实现的。就是这个BiLSTM的长度是固定的,不管你的句子长度有多少,他都会凑成20个词。这里只是在训练权重的时候时间步设置为20,这里训练就是训练模型的共享参数,因为rnn的参数在时间步上是共享的,这一点要注意。
但是在bilm.model中也是最初生成词向量的结构中,rnn是用tf.nn.dynamic_rnn()实现的,感觉这里才是真正的语言模型,在训练好参数之后,这里生成文件中每一行句子的词向量,这里的动态rnn,每一词输入的个数就是每一行句子的长度,而每一个批量的时间步就是这个批量中最大句子的长度,这个批量中长度不够的,用‘0’来进行填补。
下面是我用Notepad++打开的作者使用的训练文件部分截图,作者使用的训练文件是已经分词好了的,将单词和标点符号以及特殊的’s都用空格分开。难怪源码中没有进行分词处理,只是通过空格分开了每一个词。

为了更加清楚的认识输入和输出,我打印了2个训练样本{X:Y}如下图所示。

但是在bilm.model中确用了另一种实现方式,tf.nn.dynamic_rnn(),这种方式的BiLSTM的长度不是固定的,而且每一个批量的都不一定一样,它是根据输入的句子长度来进行调整的,我不知大这个bilm.model 是用来干嘛的,他后面并没有调用。如果知道的可以讨论一下。
模型搞清楚之后,就是跑代码了,由于这个模型对设备要求较高,我只用了一个小型的数据train文件和词典文件跑了一下。得到了3个ckpt文件和一个权重文件,这个权重文件包含了ELMo的所有模型参数,用HDF explorer打开后可以查看参数的结构。
有了模型结构ckpt文件和模型参数weights.h5文件我就可以算出特定句子中词的3层组合向量,也就是作者所说的与上下文相关的词向量。

二.动态词向量(context dependent)词向量的是生成
其实ELMo模型最大的创新之处就是这个,生成与上下文相关的词向量。作者先用20个时间步的模型训练共享参数,这个上面讲过使用静态rnn实现的,然后在计算动态词向量的时候用了动态rnn,这个时候给定任意长度的句子,用之前预训练好的模型,可以算出这个句子的每个词的3层向量,这3层向量由一层是与上下文无关的向量,这个也是模型中BiLSTM的输入,另外两层的向量是lstm的输出,当然模型最后的输出是经过投影之后的。生成动态词向量的函数是dump_bilm_embeddings(),这个函数把训练文件中每个字的词向量保存为h5格式的文件。3层动态词向量就是代码中的lm_embeddings这个4阶张量。当我们获取这个3层动态词向量之后,为了检验词向量的质量,必须搭建下游模型比如文本分类等。输入下游模型的词向量可以是这3层词向量的任意组合,也可以是单个层的输入到下游模型中。当然这个组合权重论文中也提到,也可以加入每层的组合权重来体现每层的向量在不同任务时所发挥的比重。代码中的dump_token_embeddings()保存的其实是与上下文无关的词向量。很明显他是用词典文件生成的,每一个词的词向量是唯一的,dump_bilm_embeddings()才是真正的动态的词向量