word2vec是一种静态词嵌入方法,它不会随着上下文场景的变化而变化。但一词多义在现实中太常见了,因此这种静态嵌入的局限性在很多场景显得力不从心。而ELMo就是为解决这些问题提出的,它的提出意味着从词嵌入(Word Embedding)时代进入了语境词嵌入(Contextualized Word-Embedding)时代!

ELMo原理

ELMo,是Embedding from Language Models的简称,它的核心思想体现在深度上下文(Deep Contextualized),除了提供临时词嵌入外,还提供生成这些词嵌入的预训练模型。因此在实际应用中,ELMo可以基于预训练模型,根据实际上下文场景动态调整单词的词嵌入表示。
ELMo首先把输入转换为字符级别的Embedding,根据字符级别的Embedding来生成上下文无关的word Embedding,然后使用双向语言模型(如Bi-LSTM)生成上下文相关的Embedding,其整体模型结构如下:
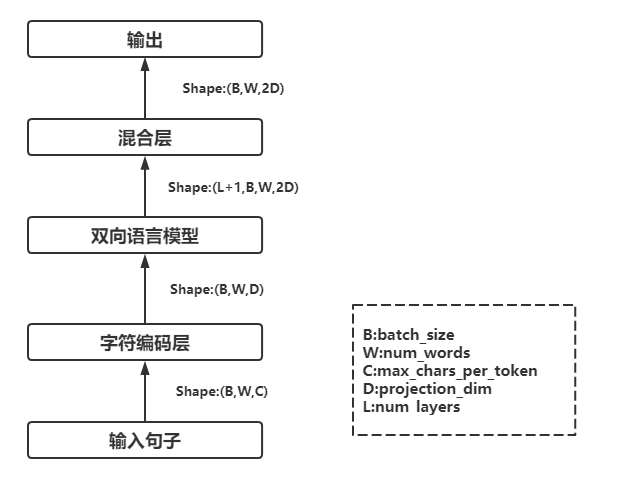
1.输入句子
句子维度B*W*C,其中B表示批量大小,W表示一句话中单词的个数,C表示每个单词的最大字符数目,可设置为某个固定值。对于一个批量中长短不一的语句,采取Padding方式对齐。
2.字符编码层
输入语句首先经过一个字符编码层(Char Encoder Layer),ELMo实际是对字符进行编码,它会对每个单词中所有字符进行编码,得到这个单词的表示。输入维度是B*W*C,经过字符编码层后的数据维度为B*W*D。这里展开进一步说明:
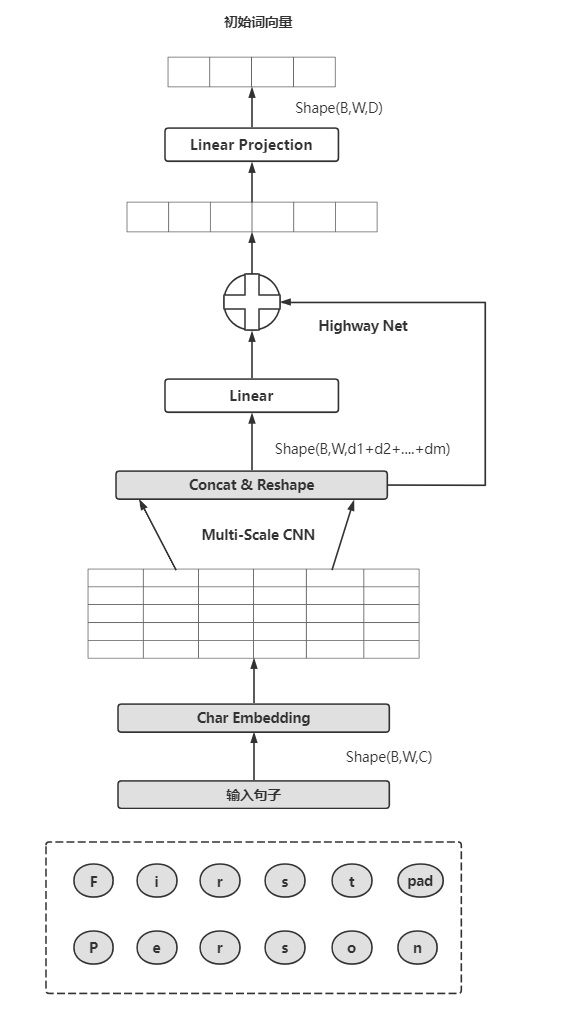
Char Embedding
对每个字符进行编码,包括一些特殊字符,如单词的开始<bow>、单词的结束<eow>、句子的开始符<bos>、句子的结束符<eos>、单词补齐符<pow>和句子补齐符<pos>等,维度会变为B*W*C*d,这里d表示字符的Embedding维度(char_embed_dim)
Multi-Scale CNN
Char Embedding通过不同规模的一维卷积、池化等作用后,再经过激活层,最后进入拼接和修改状态层(Concat&Reshape)
Concat&Reshape
把卷积后的结果进行拼接,使其形状变为(B,W,d1+...+dm),di表示第i个卷积的通道数
Highway Net
Highway Net类似残差连接,这里有2个Highway层
Linear Projection
该层为线性映射层:上一层得到的维度d1+...+dm比较长,经过该层后将维度映射到D,作为词嵌入输入后续的层中,这里输出维度为B*W*D
3.双向语言模型
对字符级语句编码后,该句子会经过双向语言模型(Bi-LSTM),得到输出维度(L+1)*B*W*2D,这里+1是加上最初的Embedding层,类似残差连接
4.混合层
得到各层的表征后,会经过一个混合层(Scalar Mixer),它会对前面这些层的表示进行线性融合,得出最终的ELMo向量,维度为B*W*2D
以上就是ELMo模型的总体流程,由于采用LSTM结构,因此其并发能力、关注语句的长度在大的语料库面前有点力不从心。而现在业界更普遍的是基于Transformer的BERT模型,因此,我们不对ELMo进行详细展开。该模型就介绍到此,以后有机会再展开。
参考资料:
《深入浅出Embedding》